Problem description
When you submit a node, the system reports the following error: "The input and output do not match the code kinship analysis."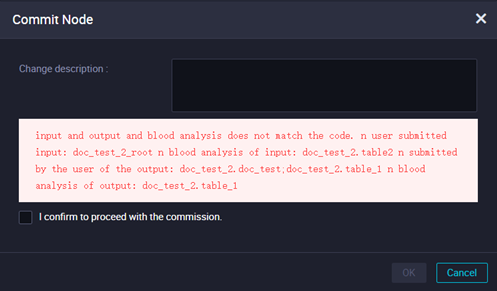
Possible causes
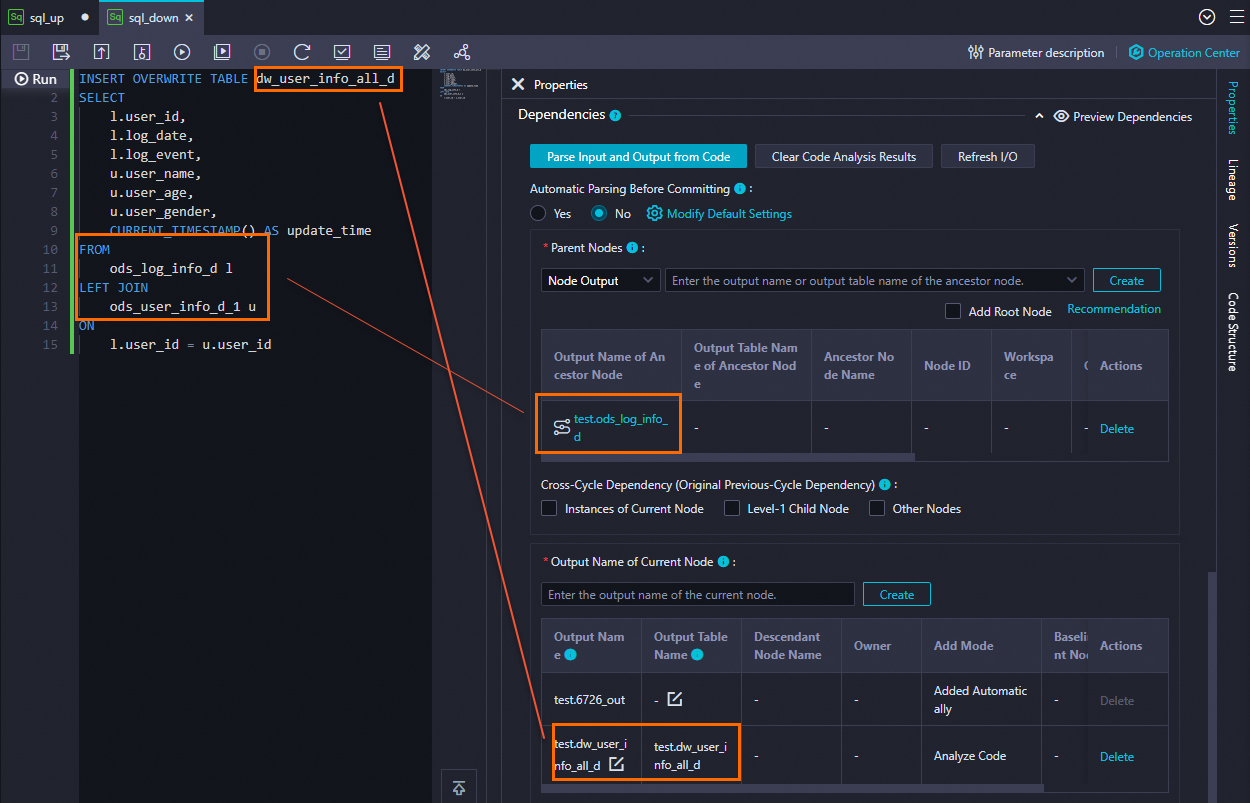
This error occurs when the table in your code's SELECT statement does not match the configured parent node dependency, or when the table in the INSERT or CREATE statement does not match the configured output of the current node.
For example:
The code for the node that you submitted contains a SELECT statement for a table named table2, but table2 is not configured as a parent node dependency.
The node you submitted has doc_test configured as its output, but the node's code does not contain an INSERT or CREATE statement for a table named doc_test.
Solution
For tables that are not generated periodically, you can ignore the message and submit the node.
DataWorks scheduling dependencies ensure that the data in tables updated by scheduling nodes is current. The platform cannot monitor tables that are not updated by the DataWorks scheduling system. If the node code selects data from a table that is not generated by a periodic schedule, you can delete the ancestor node dependency configuration that was automatically generated from the SELECT statement. Tables that are not generated by periodic scheduling include the following:
Tables uploaded to DataWorks from a local computer
Dimension tables
Tables not generated by DataWorks scheduling
Tables generated by one-time tasks
For tables that are populated periodically, ensure that their data lineage and scheduling dependencies are consistent.
Force-submitting a node without a review can have the following impacts:
For example, your code selects data from Table A, which is generated daily by a scheduling node. If you do not add Table A as a parent node dependency for the current node, a scheduling dependency is not created. If the node that generates Table A fails, descendant nodes use stale data from the previous successful run of the node for Table A. This can cause data errors.
For example, your code creates or inserts data into Table B, but you do not configure Table B as the output of the current node. If another node selects data from Table B, the system automatically parses this relationship and adds Table B as an input for that node. This creates a dependency. However, the system cannot find the node that generates Table B through this dependency. When you submit the node, an error occurs: "The output name of the parent node that the current node depends on does not exist." For more information, see Node submission error: The output name of the parent node that the current node depends on does not exist.