Data Integration supports full and incremental (near real-time) synchronization from sources such as ApsaraDB for OceanBase, MySQL, Oracle, and PolarDB to MaxCompute. This solution integrates full data migration with real-time incremental synchronization, merging data at the destination on a T+1 basis. This topic describes how to create a full and incremental (near real-time) task using MySQL as the source and MaxCompute as the destination.
How it works
The full and incremental synchronization task employs a unified process for initial full data migration and continuous incremental synchronization. Once the task starts, the system automatically creates and coordinates batch and real-time subtasks to merge and write data to the target table (Base table).
The core process consists of three phases:
Full initialization: Upon startup, a batch synchronization subtask migrates table schemas and historical data from all source tables to the target Base table in MaxCompute. Once full data initialization is complete, this batch synchronization task is frozen.
Incremental data synchronization: After the full migration concludes, a real-time synchronization subtask starts continuously capturing incremental changes (Insert, Update, Delete) from the source database (e.g., via MySQL binary logs) and writes them to a temporary Log table in MaxCompute in near real-time.
Periodic merge (Merge): A daily (T+1) Merge task combines the incremental data accumulated in the Log table from the previous day (T) with the full data in the Base table. This generates the latest full snapshot data for day T and writes it to a new partition in the Base table. The merge task runs once a day.
Using a partitioned table as an example, the data flow is as follows:

This synchronization task features the following:
Multi-table to multi-table/single-table: Supports synchronizing multiple source tables to corresponding target tables or merging data from multiple source tables into a single target table using mapping rules.
Task components: A full database synchronization task consists of a batch synchronization subtask for full initialization, a real-time synchronization subtask for incremental synchronization, and a Merge task for consolidating data.
Target table support: Supports writing data to both partitioned and non-partitioned tables in MaxCompute.
Usage notes
Resource requirements: The task requires a Serverless resource group or an exclusive resource group for Data Integration. When synchronizing in instance mode, the minimum resource specifications are 8 vCPUs and 16 GB for an exclusive resource group for Data Integration, or 2 CUs for a Serverless resource group.
Network connectivity: Ensure network connectivity between the Data Integration resource group and both the source (e.g., MySQL) and target (e.g., MaxCompute) data sources. For details, see Overview of network connectivity solutions.
Region restrictions: Synchronization is supported only for self-managed MaxCompute data sources located in the same region as the current DataWorks workspace. When using a self-managed MaxCompute data source, you must bind MaxCompute computing resources in DataWorks DataStudio; otherwise, MaxCompute SQL nodes cannot be created, causing the full synchronization "done" node creation to fail.
Scheduling resource group restrictions: The batch full synchronization subtask requires a configured resource group. Shared resource groups for scheduling are not supported.
Target table type restrictions: Synchronization to MaxCompute external tables is not supported.
Precautions
Primary key requirements: Tables without primary keys are not supported. You must manually specify one or more columns as the business primary key (Custom Primary Key) during configuration.
AccessKey (AK) validity: If you use a temporary AccessKey (AK) for synchronization, the task will fail when the AK expires (automatically after 7 days). The platform automatically restarts the task upon detecting a failure caused by a temporary AK. If monitoring is configured for this task type, you will receive an alert.
Data visibility latency: On the day of configuration, you can query only the historical full data for full and incremental (near real-time) tasks to MaxCompute. Incremental data becomes available in MaxCompute after the Merge task completes the following day. For details, see the data writing section in How it works.
Storage and lifecycle: The full and incremental (near real-time) synchronization task generates a full partition every day. To control storage costs, MaxCompute tables automatically created by the task have a default lifecycle of 30 days. If this does not meet your business needs, you can modify the lifecycle by clicking the corresponding MaxCompute table name during task configuration. For details, see Edit target table schema (Optional).
SLA: Data Integration uses the MaxCompute engine synchronization data tunnel for data upload and download (for SLA details, see Data upload scenarios and tools). Evaluate your technical choices based on the MaxCompute engine synchronization data tunnel SLA.
Binlog retention policy: Real-time synchronization relies on the binary logs (binlogs) of the source MySQL database. Ensure the binlog retention period is sufficient to prevent synchronization interruptions caused by missing start offsets during long pauses or failure retries.
Billing
The full and incremental task consists of a batch synchronization task for the full phase, a real-time synchronization task for the incremental phase, and a periodic task for the periodic merge phase. Billing applies separately to each of these three phases. All three phases consume CUs of the resource group (see Billing of serverless resource groups). The periodic task also incurs task scheduling fees (see Scheduling instance fees).
Additionally, the full and incremental synchronization link to MaxCompute consumes MaxCompute computing resources for periodic merging of full and incremental data. These fees are charged directly by MaxCompute based on the size of synchronized full data and the merge cycle. For specific fees, see Billable items and billing methods.
Procedure
Step 1: Select synchronization type
Go to the Data Integration page.
Log on to the DataWorks console. In the top navigation bar, select the desired region. In the left-side navigation pane, choose . On the page that appears, select the desired workspace from the drop-down list and click Go to Data Integration.
In the left navigation pane, click Synchronization Task. Then, click Create Synchronization Task at the top of the page. In the Create Synchronization Task dialog box, configure the following key information:
Source Type:
MySQL.Destination Type:
MaxCompute.Name: Enter a custom synchronization task name.
Task Type:
Full increment of the whole warehouse.Sync Procedure: Structural migration, Incremental synchronization, Full initialization, and Cycle Merge.
Step 2: Configure network connectivity
In the Network and Resource Configuration section, select the Resource Group used for the synchronization task. You can allocate CUs separately for full and incremental synchronization in the Task Resource Usage section to optimize resource utilization.
Select the added
MySQLdata source for Source and the addedMaxComputedata source for Destination, and then click Test Connectivity.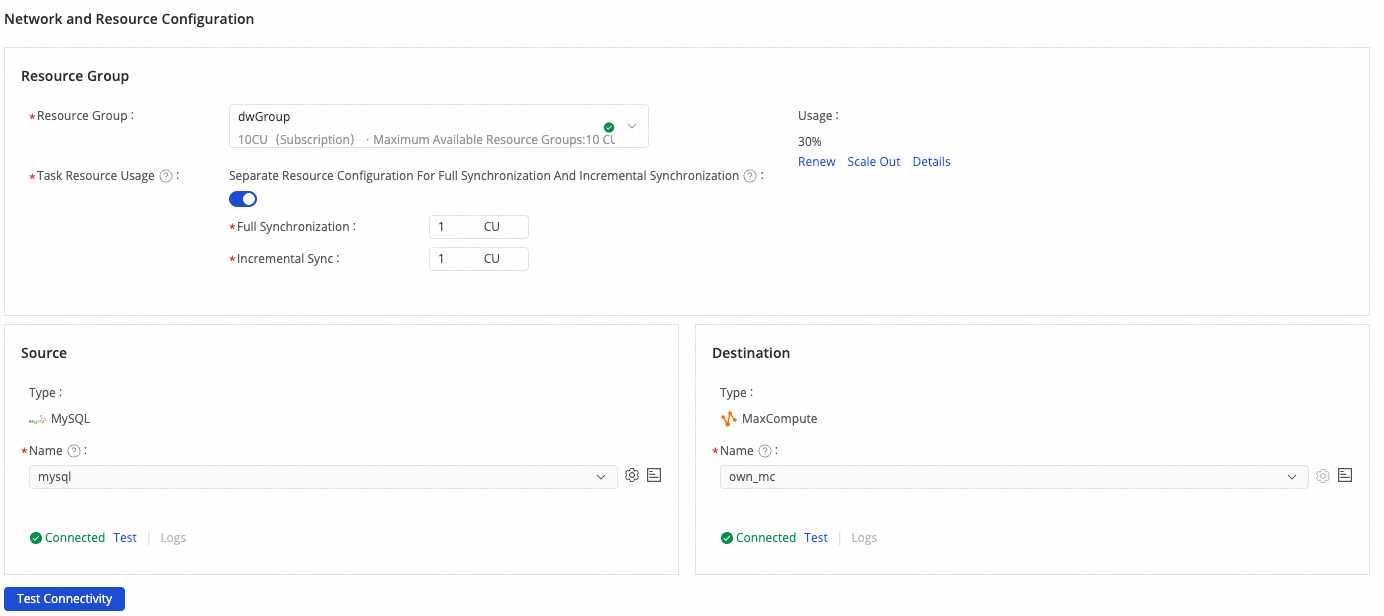
Ensure connectivity is successful for both source and target data sources, then click Next.
Step 3: Select tables
In the Source Table area, select the tables to sync from the source data source. Click the ![]() icon to move the tables to the Selected Tables list.
icon to move the tables to the Selected Tables list.
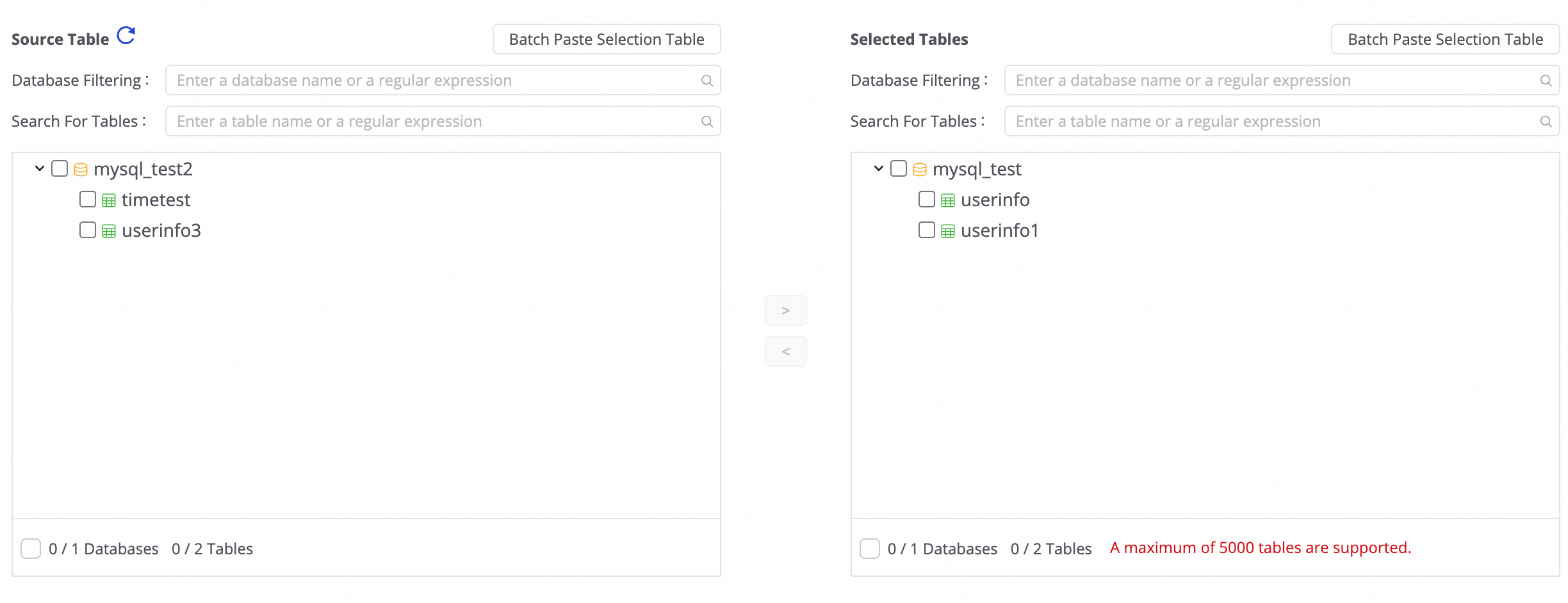
If you have a large number of tables, use Database Filtering or Search For Tables to select tables via regular expressions.
Step 4: Configure task settings
Log table time range: This parameter defines the time query range when merging data from the Log table to the target partition.
Extend this range appropriately to ensure all data belonging to the partition is merged correctly and to prevent cross-day partition errors caused by data latency.
Merge task scheduling: Set the scheduling time for the daily Merge task. For details on setting scheduling times, see Schedule time.
Periodic scheduling parameters: Set scheduling parameters. These parameters can be used later in partition settings to assign values to partitions, meeting the requirement of writing to partitions by date.
Table partition settings: Set partitions for the target table, including partition column names and assignment methods. The assignment column can use scheduling parameters to automatically generate partitions by date.
Step 5: Map target tables
In this step, you define mapping rules between source and target tables and specify rules such as primary keys, dynamic partitions, and DDL/DML configurations to determine how data is written.
Actions | Description | ||||||||||||
Refresh Mapping Results | The system lists the selected source tables. Target table attributes take effect only after you refresh and confirm.
| ||||||||||||
Customize Mapping Rules for Destination Table Names (Optional) | The system uses a default table name generation rule:
You can:
| ||||||||||||
Edit Mapping of Field Data Types (Optional) | The system provides default mapping between source and target field types. You can click Edit Mapping of Field Data Types in the upper-right corner of the table to customize the field type mapping relationship between source and target tables, then click Apply and Refresh Mapping. When editing field type mapping, ensure the field type conversion rules are correct; otherwise, type conversion failures may occur, leading to dirty data and affecting task execution. | ||||||||||||
Edit Destination Table Structure (Optional) | The system automatically creates non-existent target tables or reuses existing tables with the same name based on custom table name mapping rules. DataWorks automatically generates the target table schema based on the source table schema. Manual intervention is not required for standard scenarios. You can also modify the table schema using the following methods:
For existing tables, you can only add fields. For new tables, you can add fields, partition fields, and set table types or properties. See the editing area in the interface for details. | ||||||||||||
Destination Table Column Assignment | Native fields are automatically mapped based on matching field names in the source and target tables. The Added Fields from the previous step require manual assignment. The procedure is as follows:
You can assign constants or variables. Switch the type in Assignment Method. Supported methods include: Table Field
| ||||||||||||
Source Split PK | You can select a field from the source table in the source split key drop-down list or select No Split. During synchronization, the task is split into multiple subtasks based on this field to enable concurrent and batch data reading. We recommend using the primary key or a field with even data distribution as the source split key. String, float, and date types are not supported. Source split keys are currently supported only for MySQL sources. | ||||||||||||
Execute Full Synchronization | If full synchronization was configured in Step 3, you can individually deselect full data synchronization for specific tables. This applies to scenarios where full data has already been synchronized to the target via other means. | ||||||||||||
Full Synchronization Condition | Filters source data during the full synchronization phase. Enter the WHERE clause excluding the WHERE keyword. | ||||||||||||
DML Rule | DML message processing is used to perform granular filtering and control on change data ( | ||||||||||||
Full Data Merge Cycle | Currently only supports daily merge. | ||||||||||||
Merge Primary Key | You can define the primary key by selecting one or more columns from the table.
|
 button and selecting Manual Input or Built-in Variable for concatenation. Supported variables include Source Data Source Name, Source Database Name, and Source Table Name.
button and selecting Manual Input or Built-in Variable for concatenation. Supported variables include Source Data Source Name, Source Database Name, and Source Table Name.

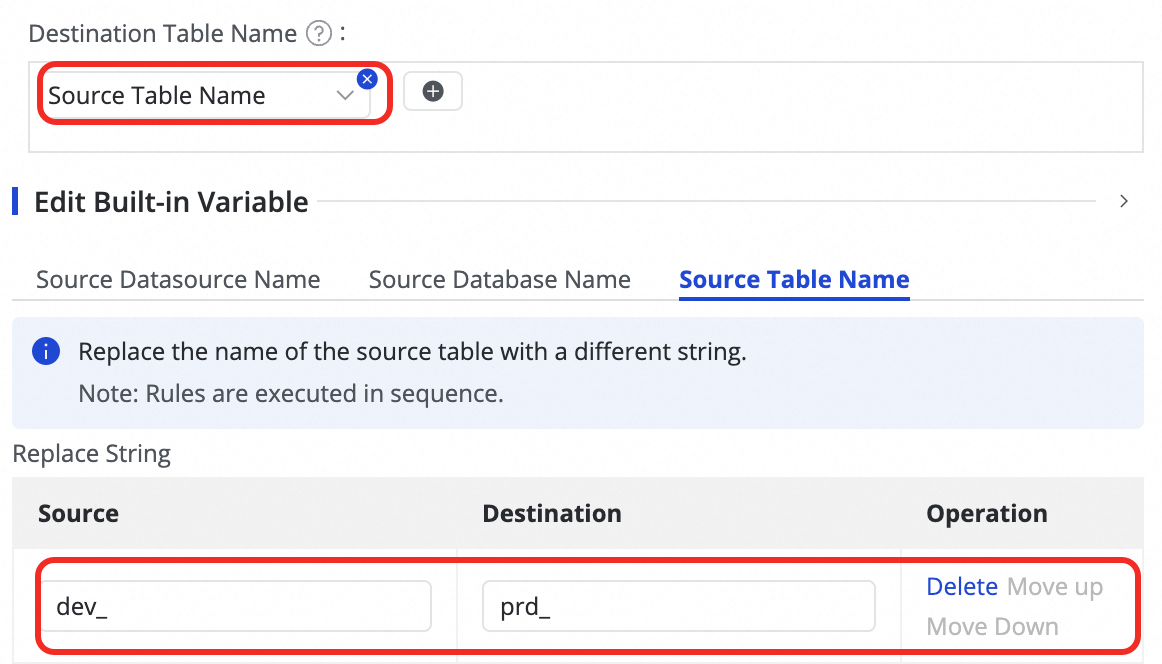


 button in the Destination Table Name column to add a field.
button in the Destination Table Name column to add a field. tooltip.
tooltip.Step 6: Configure DDL capabilities
Certain real-time synchronization tasks detect metadata changes in the source table structure and synchronize updates or take other actions such as alerting, ignoring, or terminating execution.
Click Configure DDL Capability in the upper-right corner of the interface to set processing policies for each change type. Supported policies vary by channel.
Normal Processing: The destination processes the DDL change information from the source.
Ignore: The change message is ignored, and no modification is made at the destination.
Error: The whole database real-time synchronization task is terminated, and the status is set to Error.
Alert: An alert is sent to the user when such a change occurs at the source. You must configure DDL notification rules in Configure Alert Rule.
When DDL synchronization adds a source column to the destination, existing records are not backfilled with data for the new column.
Step 7: Other configurations
Alarm configuration
1. Add Alarm
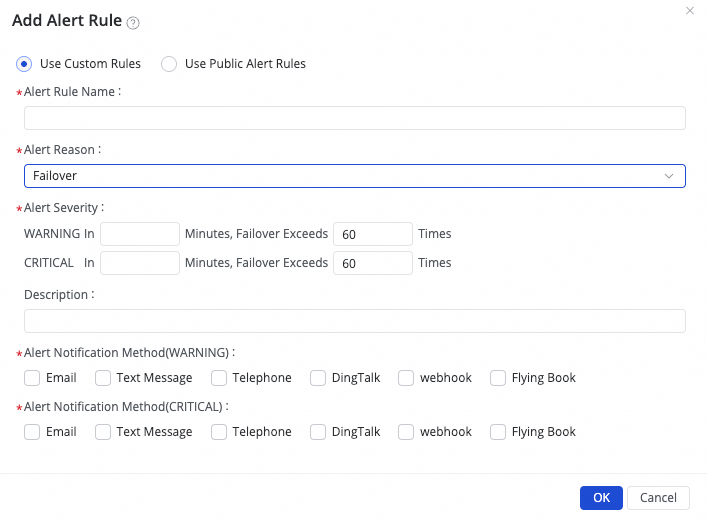
(1) Click Create Rule to configure alarm rules.
Set Alert Reason to monitor metrics like Business delay, Failover, Task status, DDL Notification, and Task Resource Utilization for the task. You can set CRITICAL or WARNING alarm levels based on specified thresholds.
By setting Configure Advanced Parameters, you can control the time interval for sending alarm messages to prevent alert fatigue and message backlogs.
If you select Business delay, Task status, or Task Resource Utilization as the alarm reason, you can also enable recovery notifications to notify recipients when the task returns to normal.
(2) Manage alarm rules.
For created alarm rules, you can use the alarm switch to control whether the alarm rule is enabled. Send alarms to specific recipients based on the alarm level.
2. View Alarm
Expand in the task list to enter the alarm event page and view the alarm information that has occurred.
Resource group configuration
You can manage the resource group used by the task and its configuration in the Configure Resource Group panel in the upper-right corner of the interface.
1. View and switch resource groups
Click Configure Resource Group to view the resource group currently bound to the task.
To change the resource group, switch to another available resource group here.
2. Adjust resources and troubleshoot "insufficient resources" errors
If the task log displays a message such as
Please confirm whether there are enough resources..., the available computing units (CUs) of the current resource group are insufficient to start or run the task. You can increase the number of CUs occupied by the task in the Configure Resource Group panel to allocate more computing resources.
For recommended resource settings, see Data Integration Recommended CUs. Adjust the settings based on actual conditions.
The batch synchronization task in DataWorks is dispatched by the scheduling resource group to the Data Integration task execution resource group for execution. Therefore, in addition to using the Data Integration task execution resource group, the batch synchronization task also consumes resources from the scheduling resource group and incurs scheduling instance fees.
Advanced parameter configuration
For custom synchronization requirements, click Configure in the Advanced Settings column to modify advanced parameters.
Click Advanced Settings in the upper-right corner of the interface to enter the advanced parameter configuration page.
Modify the parameter values according to the prompts. The meaning of each parameter is explained after the parameter name.
Understand parameters fully before modification to prevent issues like task delays, excessive resource consumption blocking other tasks, or data loss.
Step 8: Execute synchronization task
After you complete the configuration, click Save or Complete to save the task.
On the , find the created synchronization task and click Deploy in the Operation column. If you select Start immediately after deployment in the dialog box that appears and click Confirm, the task is executed immediately. Otherwise, you must manually start the task.
NoteData Integration tasks must be deployed to the production environment before they can be run. Therefore, you must deploy a new or modified task for the changes to take effect.
Click the Name/ID of the task in the Tasks to view the execution details.
Next steps
After configuring the task, you can manage it, add or remove tables, configure monitoring and alerting, and view key task running metrics. For details, see Perform O&M on a full and incremental sync task.
FAQ
Q: Why is the Base table data not updating as expected?
A: See the following causes and solutions:

Symptom | Cause | Solution |
Validation failed for T-1 partition data in the incremental Log table. | The real-time synchronization task encountered an exception, preventing the T-1 partition data in the incremental Log table from being generated correctly. |
|
Validation failed for T-2 partition data in the target Base table. |
|
|