A dependency on the previous cycle is a cross-cycle dependency where a node instance depends on the successful run of another node's instance from the previous cycle.
DataWorks supports the following three types of cross-cycle dependencies:
First-level child nodes
Node dependency: The current node depends on its direct downstream nodes (first-level child nodes). For example, if node A has three downstream nodes B, C, and D, a dependency on first-level child nodes means that the current instance of node A depends on the successful completion of the previous cycle's instances of nodes B, C, and D.
Business scenario: The current node's run depends on its downstream nodes having successfully cleansed data in the previous cycle. The data that was cleansed originated from the current node's output table in that previous cycle. To verify that the data cleansing results meet expectations, you can configure Data Quality rules on the output tables of the downstream nodes.
Current node
Node dependency: This is a cross-cycle self-dependency. The current node instance depends on the successful completion of its own instance from the previous cycle.
Business scenario: The current node's run depends on the business data that it produced in the previous cycle. To verify that the data meets expectations, you can configure Data Quality monitoring rules on the node's output table.
Custom: You can manually specify the nodes for the dependency by entering their node IDs. To specify multiple nodes, separate the IDs with a comma (,), for example, 12345,23456.
Node dependency: The current node's run depends on the successful completion of the specified custom nodes from the previous cycle.
Business scenario: The business logic requires a dependency on the successful data output from another business process, even though the current node does not directly operate on that data.
In the Operation Center, cross-cycle dependencies are displayed as dashed lines to distinguish them from same-cycle dependencies.
When you unpublish a node, you must delete its dependencies. This includes both cross-cycle dependencies (①) and same-cycle dependencies (②).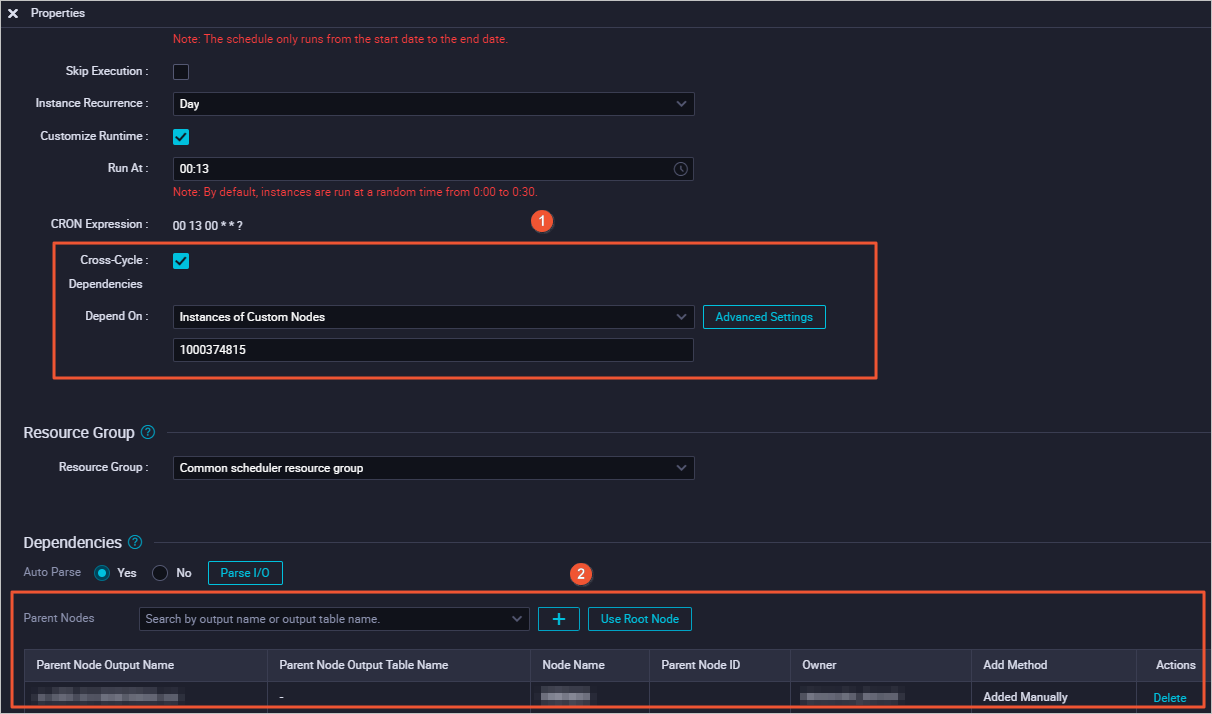
You can choose which cycle of the upstream nodes to depend on. Typically, you select only one type of dependency: same-cycle or cross-cycle. The auto-parsing feature creates a same-cycle dependency on upstream nodes by default. To change this, you must first delete the same-cycle dependency and then add the cross-cycle dependency. For more information, see Scheduling dependency logic.
The following figure shows the dependencies of the nodes in the business flow.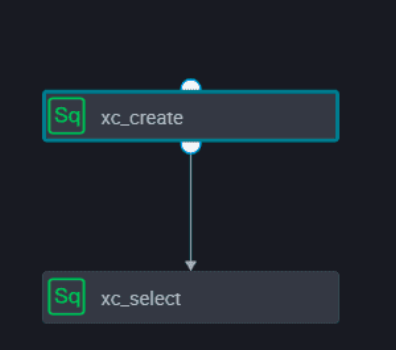
The Operation Center page shows the dependencies of the business flow.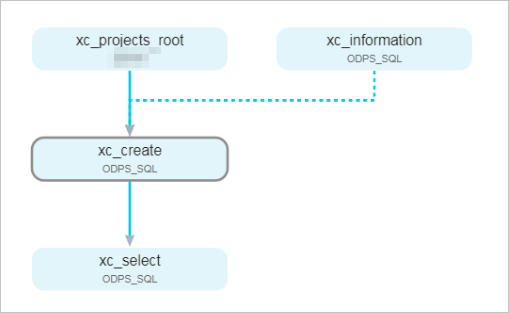
The following figure shows an example of the code for the xc_create node.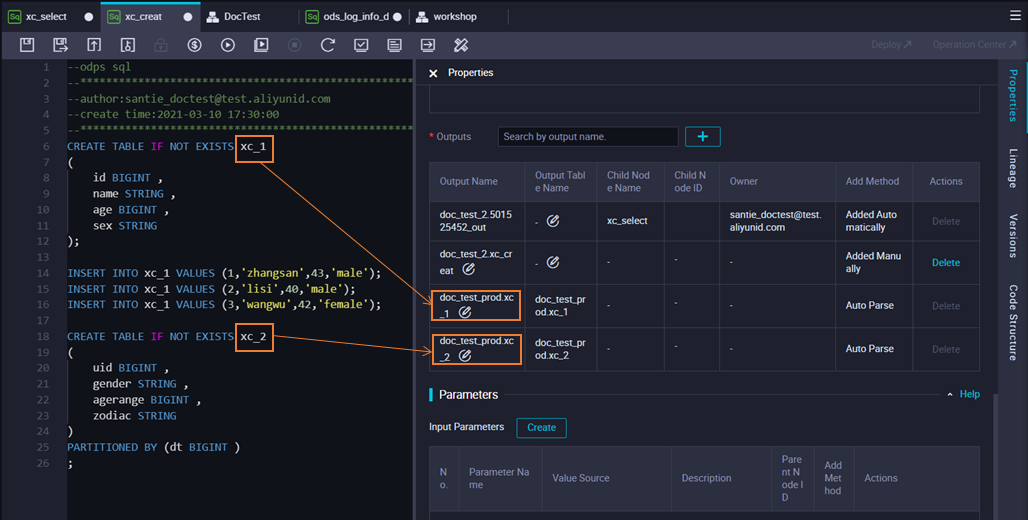
As shown in the figure, the SQL code for the xc_create node creates and populates two tables: xc_1 and xc_2. These tables are then set as the outputs for the node.
The following figure shows an example of the code for the xc_select node.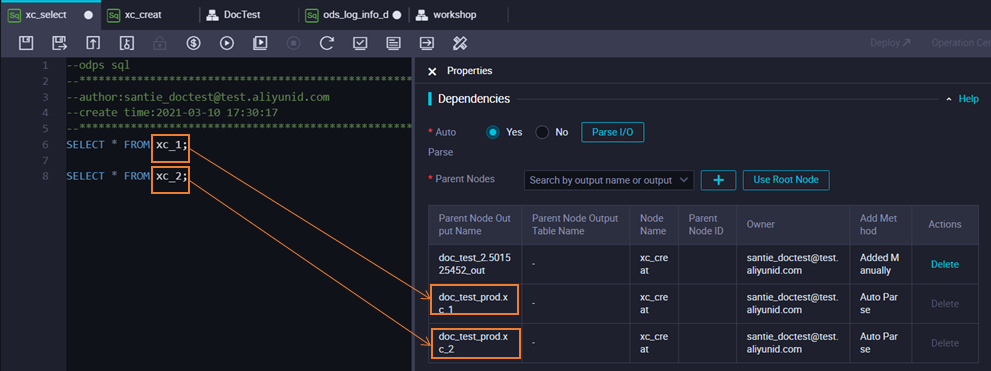
As shown in the figure, the SQL code for the xc_select node queries data from the tables produced by the xc_create node. The auto-parsing feature automatically identifies the xc_create node as an upstream dependency for the xc_select node.
Dependency on previous cycle: First-level child nodes
Node dependency: The current node depends on the successful completion of its direct downstream nodes from the previous cycle. For example, if node A has three downstream nodes (B, C, and D), the current instance of node A will only run if the previous cycle's instances of B, C, and D all completed successfully.
Business scenario: The current node's run depends on its downstream nodes having successfully performed data cleansing in the previous cycle. The data that was cleansed originated from the current node's output table. The current node instance will run only if its downstream nodes ran successfully in the previous cycle.
The xc_create node is set to depend on its first-level child nodes.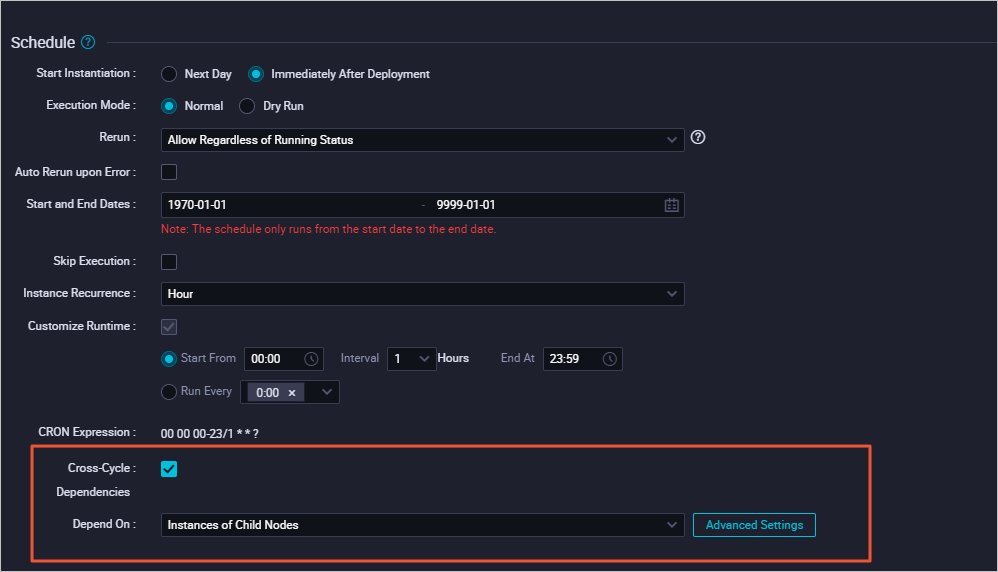
The Operation Center page shows the dependencies for each node.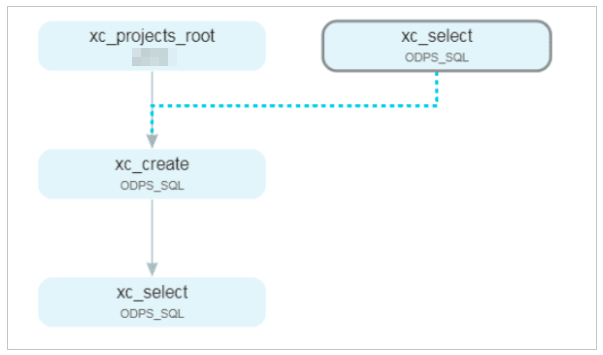
Dependency on previous cycle: Current node
Node dependency: The current node instance depends on the successful completion of its own instance from the previous cycle. If the previous instance did not complete successfully, the current instance is blocked.
Business scenario: The node's current run depends on the status of its own run from the previous cycle. For easier observation in this example, the node is scheduled to run hourly.
Go to the page to view the node's dependencies.
For an hourly node with a self-dependency (Dependency on previous cycle: Current node), if an instance from the previous cycle does not run successfully, the instance for the next hour will not run either.
For example, if an hourly task fails or does not run, all subsequent hourly instances of that node for the day will also be blocked from running.
Dependency on previous cycle: Custom node
Node dependency: The current node (xc_create) depends on the successful completion of a custom node (1000374815) from the previous cycle. This dependency is required by the business logic, even though the current node's code does not use the output table of node 1000374815.
Business scenario: The business logic requires a dependency on the successful data output of node 1000374815. However, the current node (xc_create) does not operate on this business data, for example, by selecting from the output table of node 1000374815.
Node 1000374815 is selected as a custom upstream dependency for the xc_create node.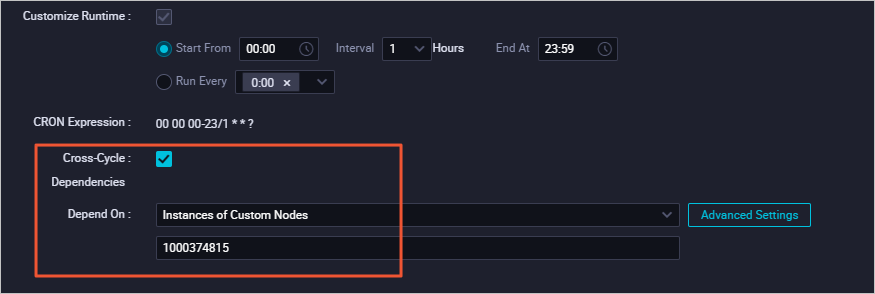
Go to the page to view the node's dependencies.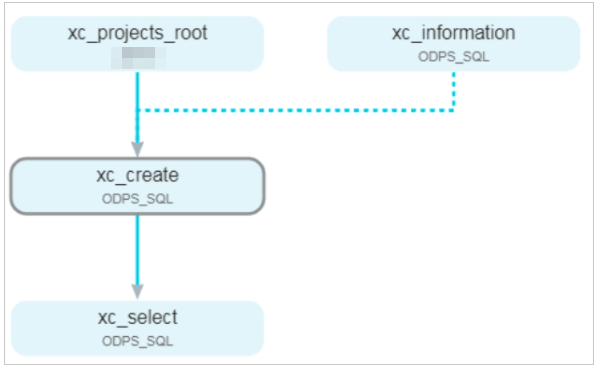
Advanced configuration for cross-cycle dependency
In a branch scenario, a branch node typically has multiple downstream nodes, but only one is selected to run while the others are set to dry-run. This dry-run property propagates to all child nodes of the dry-run branch. To handle this situation, DataWorks provides the scheduling attribute: Do not propagate the dry-run property of ancestor nodes across cycles.
However, if a node in a downstream branch has a self-dependency on its previous cycle, and its branch was not selected in the previous cycle, the node will be set to dry-run indefinitely.
For example, if the node (I_am_the_left_one) is set to dry-run, its downstream nodes will also be set to dry-run.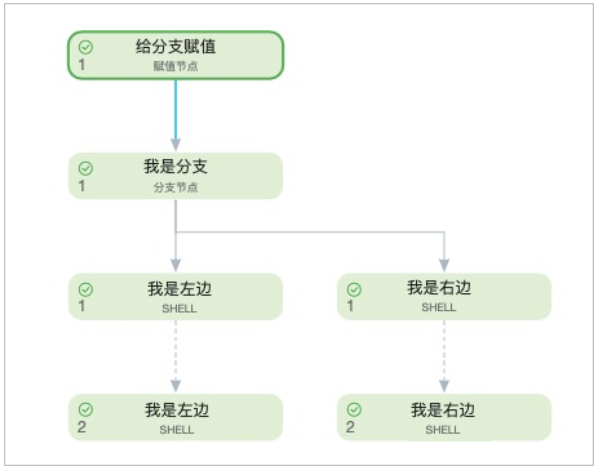
To ensure that a node's run status in the next cycle is determined by the branch selection in the next cycle, not by the dry-run property from the previous cycle, perform the following steps:
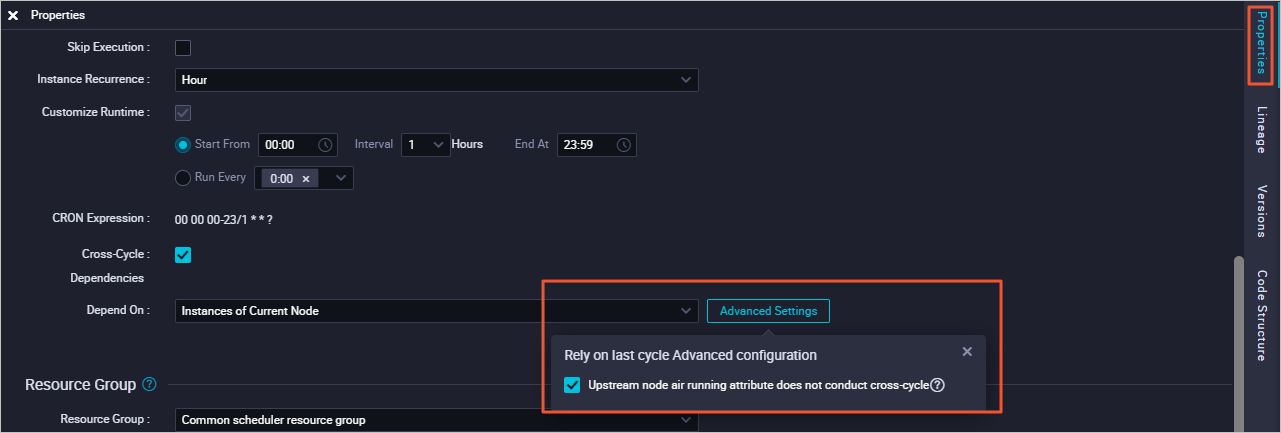
On the right side of the node editor page, click Scheduling Configuration.
In the Time Property area, select Dependency on previous cycle.
Click Advanced Configuration.
Select Do not propagate the dry-run property of ancestor nodes across cycles. The task will no longer be affected by the dry-run property of the branch node from the previous cycle.
This option only applies to the dry-run property propagated from an unselected ancestor branch node. It does not affect the dry-run property of a regular node from the previous cycle.
Typical scenarios for cross-cycle dependencies
Scenario 1:
Scenario description: A daily node depends on hourly nodes, but you want the daily node to run at its scheduled time (for example, 12:00) without waiting for all 24 hourly instances to complete.
Solution: Configure the upstream hourly node with a self-dependency by selecting . Set the scheduled time for the downstream daily node to 12:00. The daily node does not require a cross-cycle dependency.
When the 12:00 instance of the upstream hourly node runs successfully, the downstream daily node will start to run.
Scenario 2:
Scenario description: A daily node depends on the previous day's data from an hourly node.
Solution: Configure the downstream daily node with , and enter the ID of the upstream hourly node.
Scenario 3:
Scenario description: An hourly node depends on a daily node. When the upstream daily node finishes, the scheduled times for several of the downstream hourly node's cycles have already passed. This can cause multiple instances of the hourly node to start concurrently.
Solution: Configure the downstream hourly node with a self-dependency by selecting . This forces the hourly instances to run sequentially instead of concurrently.
Scenario 4:
Real-time scenario: If a node depends on the data it generated in the previous epoch, how do you confirm the data's generation time?
Solution: Configure the node with a self-dependency by selecting .