DataWorks can connect to Cloudera Distribution for Hadoop (CDH) and Cloudera Data Platform (CDP) clusters. After you register a CDH or CDP cluster in DataWorks, you can perform data development and governance operations, such as task development, scheduling, metadata management in Data Map, and data quality monitoring.
Background information
CDH is an open source platform distribution from Cloudera. It provides out-of-the-box features such as cluster management, monitoring, and diagnostics. It also supports various components to help you run end-to-end big data workflows.
CDP is a public data platform that collects and integrates customer data across platforms. It helps you collect real-time data and use it to build individual user data profiles.
You can register CDH and CDP clusters in DataWorks to perform data development and administration operations for your business needs. These operations include task development, scheduling, Data Map (metadata management), and Data Quality.
Prerequisites
You can register a CDH or CDP cluster in the current workspace if you have one of the following permissions:
An Alibaba Cloud account.
A DataWorks workspace member with the Workspace Administrator role. For more information, see Add workspace members and manage their roles.
A DataWorks workspace member that is attached to the AliyunDataWorksFullAccess policy. For more information about how to grant permissions, see Grant permissions to a RAM user and Manage permissions for a RAM role. For more information about how to add a user to a DataWorks workspace as a member, see Add workspace members and manage their roles.
You have deployed a CDH or CDP cluster and obtained the required configuration information. For more information, see Preparations: Obtain CDH or CDP cluster information and configure network connectivity.
Limits
Only serverless resource groups (recommended) or exclusive resource groups for scheduling of an earlier version can be used to run CDH or CDP cluster tasks.
NoteServerless resource groups are general-purpose resource groups that can be used in various scenarios, such as data synchronization and task scheduling. For more information about how to purchase a serverless resource group, see Use serverless resource groups. If you purchased an exclusive resource group for scheduling of an earlier version, you can also use that resource group to run CDH or CDP tasks. For more information, see Use exclusive resource groups for scheduling.
New users can purchase only serverless resource groups.
If you register a cluster of a Custom Version in DataWorks, you can use only an exclusive resource group for scheduling of an earlier version. For more information about cluster versions, see Step 2: Register a CDH or CDP cluster.
You can register a CDH or CDP cluster in DataWorks only in the following regions: China (Beijing), China (Shanghai), China (Hangzhou), China (Shenzhen), China (Zhangjiakou), China (Chengdu), and Germany (Frankfurt).
Step 1: Go to the cluster registration page
Go to the SettingCenter page.
Log on to the DataWorks console. In the top navigation bar, select the desired region. In the left-side navigation pane, choose . On the page that appears, select the desired workspace from the drop-down list and click Go to Management Center.
In the navigation pane on the left, click Cluster Management to go to the Cluster Management page. Click Register Cluster, select CDH as the open source cluster type, and go to the cluster registration page.
Step 2: Register a CDH or CDP cluster
If you use a workspace in standard mode, you must register clusters for the development and production environments. For more information about workspace modes, see Differences between workspace modes.
The development operations for CDP and CDH clusters in DataWorks are basically the same. This topic uses a CDH cluster as an example to describe how to register a CDH cluster in DataWorks.
Configure the basic information about the cluster.
Parameter
Description
Display Name of Cluster
The name of the cluster in DataWorks. The name must be unique.
Cluster Version
Select the version of the cluster that you want to register.
You can select CDH 5.16.2, CDH 6.1.1, CDH 6.2.1, CDH 6.3.2, or CDP 7.1.7. The component versions for these cluster versions are fixed. You can view the component versions in the Cluster Connection Information section. If these cluster versions do not meet your business needs, select Custom Version and configure the component versions as needed.
NoteThe components that you need to configure vary based on the cluster version. The actual components displayed on the page prevail.
If you register a cluster of a Custom Version to DataWorks, you can use only an exclusive resource group for scheduling of an earlier version. After the registration is complete, you must submit a ticket to contact technical support to initialize the environment.
Cluster Name
Used to determine the source of the configuration information for the cluster that you want to register. You can select a cluster that is registered in another workspace or create a cluster.
Registered cluster: The configuration information of the cluster that you want to register directly references the configuration information of a cluster that is registered in another workspace.
New cluster: You must configure the configuration information for the cluster that you want to register.
Configure the cluster connection information.
Select the versions of the components that are deployed in the cluster and enter the component addresses that you obtained. For more information about how to obtain component information, see Preparations: Obtain CDH or CDP cluster information and configure network connectivity.
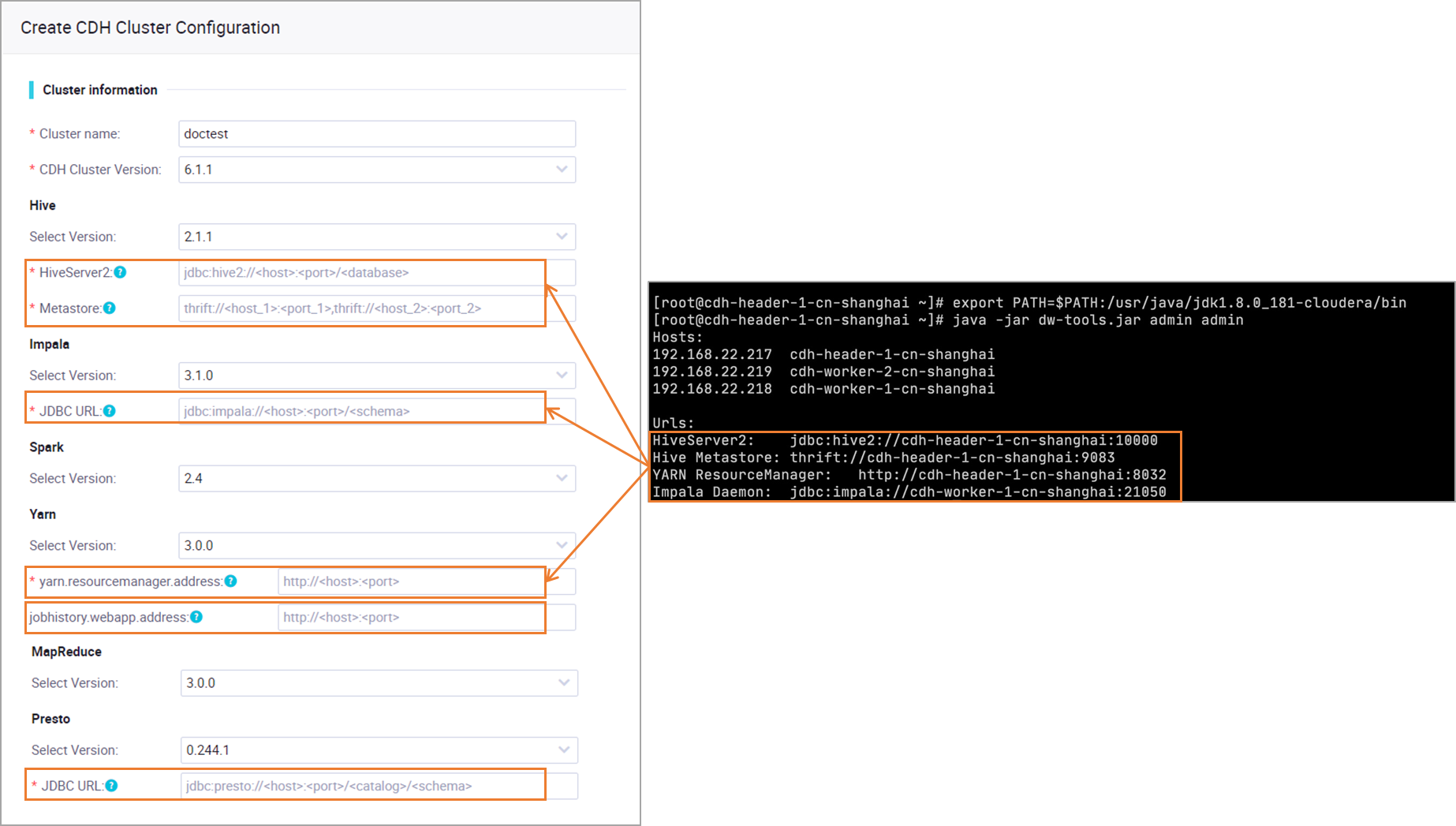 Note
NoteIf you use a serverless resource group to access CDH-related components by domain name, you must configure authoritative resolution for the domain names of the CDH components in PrivateZone of Alibaba Cloud DNS. For more information, see Add a built-in authoritative domain name and Set the scope of a domain name.
Add cluster configuration files.
Upload the configuration files of the required components. For more information about how to obtain the configuration files, see Preparations: Obtain CDH or CDP cluster information and configure network connectivity.
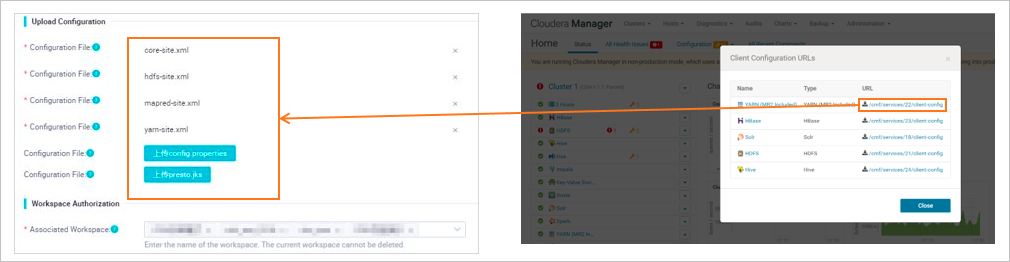
The following table describes the configuration files.
Configuration file
Description
Scenarios
core-site.xml
Contains the global configurations of the Hadoop Core library, such as common I/O settings for HDFS and MapReduce.
Upload this file to run Spark or MapReduce tasks.
hdfs-site.xml
Contains HDFS-related configurations, such as data block size, number of backups, and path names.
mapred-site.xml
Configures MapReduce-related parameters, such as the execution method and scheduling behavior of MapReduce jobs.
Upload this file to run MapReduce tasks.
yarn-site.xml
Contains all configurations related to the YARN daemon process, such as the environment configurations for the resource manager, node manager, and application runtime.
Upload this file to run Spark or MapReduce tasks, or if you select Kerberos as the account mapping type.
hive-site.xml
Contains parameters for configuring Hive, such as database connection information, Hive Metastore settings, and the execution engine.
Upload this file if you select Kerberos as the account mapping type.
spark-defaults.conf
Specifies the default configurations for Spark job execution. You can use the
spark-defaults.conffile to pre-configure parameters, such as memory size and the number of CPU cores. Spark applications use these parameter configurations at runtime.Upload this file to run Spark tasks.
config.properties
Contains the configurations of the Presto server, such as the global properties for the coordinator and worker nodes in the Presto cluster.
Upload this file if you use the Presto component and select OPEN LDAP or Kerberos as the account mapping type.
presto.jks
Stores security certificates, including private keys and public key certificates issued to applications. In the Presto database query engine, the
presto.jksfile is used to enable SSL/TLS encrypted communication for the Presto process to ensure data transmission security.Configure the default access identity for the cluster.
Configure the account that is used to access the CDH cluster when you run CDH cluster tasks in DataWorks. The supported accounts vary based on the environment.
NoteWhen you register a cluster, if you set Default Access Identity to an account other than a cluster account and no account mapping is configured or the mapping type is set to no authentication, all tasks fail.
Environment
Default access identity
References
Development environment
Cluster account: A specified cluster account is used to access the CDH cluster, regardless of who runs the CDH tasks in DataWorks, such as an Alibaba Cloud account or a RAM user with only development permissions.
Mapped account: When a task executor runs a CDH task, you must configure a mapping between the task executor account and a cluster account. After the mapping is configured, the mapped cluster account is used to access the CDH cluster when the task runs.
For more information about how to configure account mappings, see Set cluster identity mappings.
Production environment
Cluster account: A specified cluster account is used to access the CDH cluster, regardless of who runs the CDH tasks in DataWorks, such as an Alibaba Cloud account or a RAM user with only development permissions.
Mapped account: When the task owner, an Alibaba Cloud account, or a RAM user runs a CDH task, you must configure a mapping between the corresponding account and a cluster account. After the mapping is configured, the mapped cluster account is used to access the CDH cluster when the task runs.
Click Complete Creation to register the cluster in DataWorks.
Step 3: Initialize a resource group
You must initialize the resource group the first time you associate a cluster, or if the cluster service configuration changes or a component is upgraded (for example, if you modify the core-site.xml file). This ensures that the resource group can access the CDH cluster and that CDH cluster tasks can run using the current environment configuration of the resource group. On the Cluster Management page, find the registered CDH cluster, click Initialize Resource Group in the upper-right corner, select the required resource group, and then initialize it.
DataWorks lets you use only serverless resource groups (recommended) and exclusive resource groups for scheduling to run CDH cluster tasks. Therefore, you can initialize only these two types of resource groups. If no resource group is available, you can create one as needed. For more information, see Use serverless resource groups and Use exclusive resource groups for scheduling.
If you register a cluster of a Custom Version to DataWorks, you can use only an exclusive resource group for scheduling of an earlier version. After the registration is complete, you must submit a ticket to contact technical support to initialize the environment.
(Optional) Set a YARN resource queue
A YARN resource queue partitions and isolates cluster resources to ensure that different types of tasks can use computing resources fairly and avoid interference. To set a dedicated YARN resource queue for tasks of different modules, find the CDH cluster that you bound on the Cluster Management page. On the YARN Resource Queue tab, click EditYARN Resource Queue to configure the settings.
(Optional) Set Spark-related parameters
You can set dedicated SPARK property parameters for tasks in different modules.
On the Cluster Management page, find the CDH cluster that you bound.
Click the Spark-related Parameter tab and then click EditSpark-related Parameter to go to the page for editing the SPARK parameters of the CDH cluster.
Click Add below a module. Enter the Spark Property Name and the corresponding Spark Property Value to set the Spark property information.
What to do next
Set cluster identity mappings: If the default access identity for the CDH cluster is not a specified cluster account (which means access is through a DataWorks account), you must configure mappings between DataWorks accounts and cluster accounts. This allows DataWorks accounts to access the CDH cluster using the mapped cluster identity, which implements data permission isolation and control.
After you configure the CDH computing resource, you can use CDH-related nodes in DataStudio to perform data development operations.