You can create a Hologres internal table by executing a DDL statement. You can also create a Hologres internal table in the DataWorks console. This topic describes how to create a Hologres internal table in the DataWorks console.
Prerequisites
A Hologres computing resource is added to your workspace and is associated with DataStudio. For more information, see DataStudio (old version): Associate a Hologres computing resource.
You are assigned a role that has the development permissions, such as the Workspace Manager or Development role. For information about how to grant users permissions, see Manage permissions on workspace-level services.
Background information
Hologres tables are classified into Hologres internal tables and Hologres external tables.
Hologres internal tables: This type of Hologres table can store source MaxCompute data. You can synchronize data from source MaxCompute tables to Hologres internal tables for quick queries and analysis. The performance of querying MaxCompute data by using Hologres internal tables is better than that by using Hologres external tables.
Hologres external tables: This type of Hologres table cannot store source MaxCompute data. A Hologres external table can be used to map data of a source MaxCompute table for accelerated queries and analysis. Hologres external tables prevent redundant data storage and allow you to obtain query results in an efficient manner without the need to import or export data.
DataWorks works as a data processing and development platform that allows you to create Hologres tables in the DataWorks console. You can also create Hologres tables by executing DDL statements. For more information, see CREATE TABLE.
Limits
You can create a Hologres internal table in the DataWorks console only in the China (Shanghai) and China (Beijing) regions.
Procedure
Create a workflow.
If you have an existing workflow, skip this step.
Move the pointer over the
 icon and select Create Workflow.
icon and select Create Workflow. In the Create Workflow dialog box, configure the Workflow Name parameter.
Click Create.
Create a Hologres internal table.
Move the pointer over the
icon and choose . In the Create Table dialog box, set Table Type to Internal Table and configure other parameters such as Engine Instance, Path, and Name.
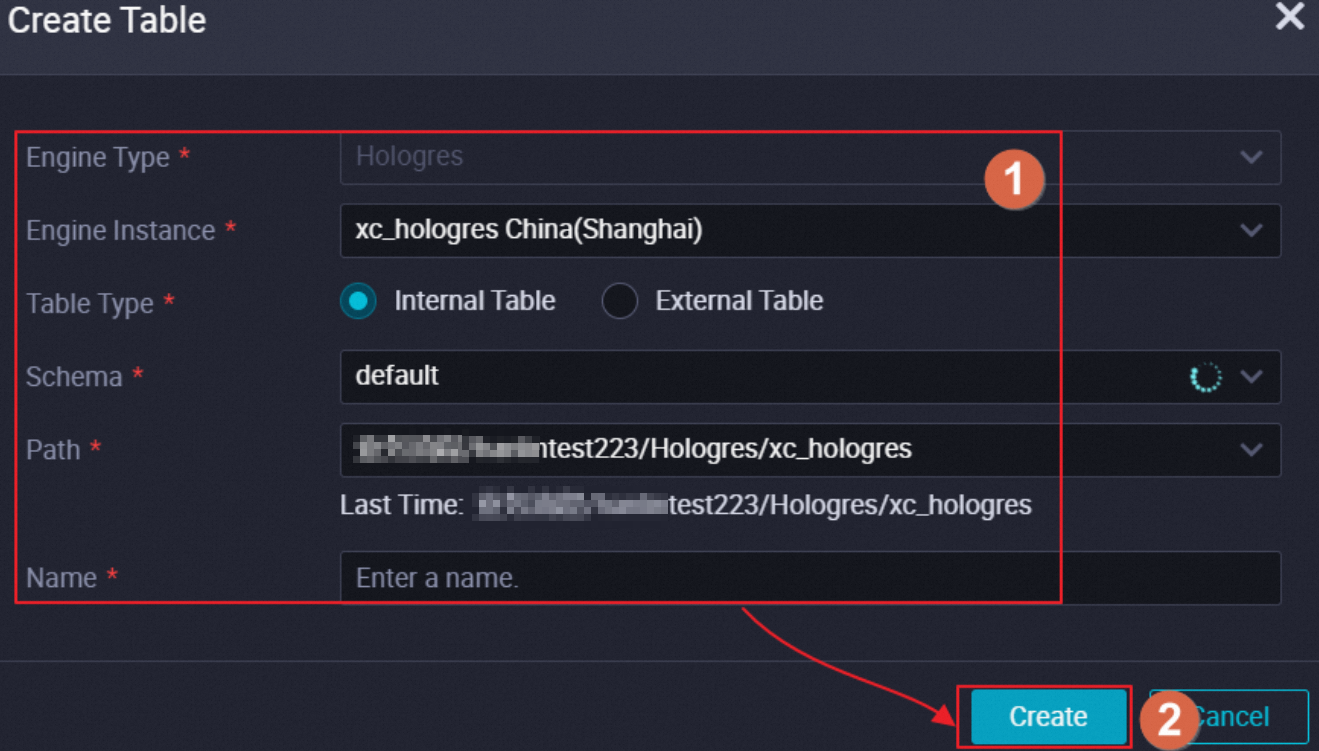
Configure the Hologres internal table.
On the configuration tab of the Hologres internal table, configure the parameters.
Configure the parameters in the General section.
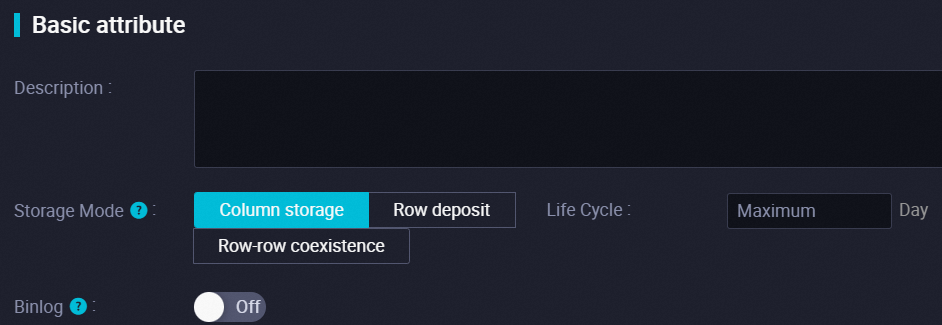 The following table describes the parameters in the General section.
The following table describes the parameters in the General section. Parameter
Description
Storage Mode
The storage mode of the Hologres internal table. Default value: Column storage.
Column storage: This storage mode is suitable for online analytical processing (OLAP) scenarios and supports complex queries, data association, scanning, filtering, and statistics collection. The efficiency of inserting and updating data in column-oriented tables is lower than that in row-oriented tables.
Row deposit: This storage mode is suitable for scenarios in which key-value pairs are used for queries and supports point queries and scans based on primary keys. The efficiency of inserting and updating data in row-oriented tables is higher than that in column-oriented tables.
Row-row coexistence: This storage mode is suitable for scenarios in which both column-oriented storage and row-oriented storage are used. It supports both point queries and OLAP. This storage mode involves more storage costs and costs of internal data status synchronization.
NoteFor more information about storage modes, see the description of the
orientationparameter in CREATE TABLE.Life Cycle
The time-to-live (TTL) period of the Hologres internal table. Unit: second. The default TTL period of the Hologres internal table is permanent.
NoteThe system counts the start of the TTL period from the time when data is first written to the table. If the TTL period expires, the data of the table is deleted in an unspecified time period.
Binlog
Specifies whether to enable binary logging for the Hologres internal table. If binary logging is enabled, you must configure the Binlog Lifecycle parameter. The default TTL period of binary logging is permanent.
NoteOnly Hologres V0.9 and later support subscription to the binary logs of a single table. For more information about binary logging, see Subscribe to Hologres binary logs.
Configure the parameters in the Physical Model section.
NoteThe parameter configurations in the Physical Model section are only used to facilitate table management based on your business requirements and are not used to implement the underlying logic.

Parameter
Description
Theme
The level-1 folder and level-2 folder to which the Hologres internal table belongs. The parameters can be used to categorize tables based on business categories. You can store tables of the same business category in the same folder.
NoteThe level-1 folder and level-2 folder are folders in DataWorks. You can easily manage tables in folders.
Layer
The physical data layer to which the Hologres internal table belongs. Data layering is used to define and manage data layers. In most cases, data layers are categorized into data import layers, data sharing layers, and data analysis layers. You can store a table at a specific data layer based on the business category.
NoteYou can click the
 icon to create a data layer. For more information, see Manage settings for tables.
icon to create a data layer. For more information, see Manage settings for tables. Category
The physical category of the Hologres internal table. The parameter is used to categorize tables in a finer-grained manner from the business dimension. In most cases, tables are categorized into tables at the basic service level, tables at the advanced service level, and tables at other levels.
NoteYou can click the
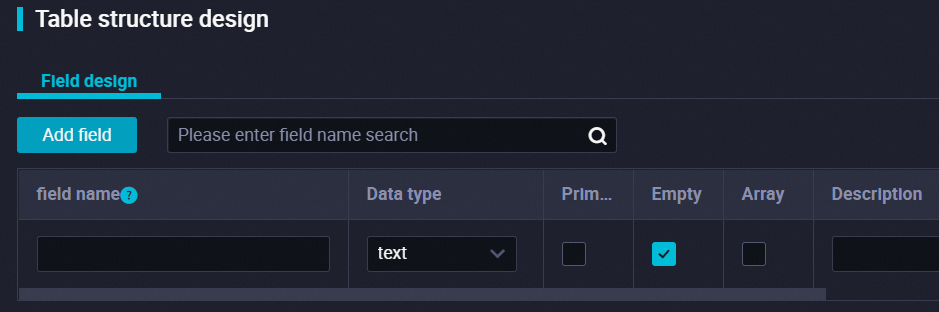
icon to create a physical category. For more information, see Manage settings for tables. Configure the parameters in the Schema section.
Tab
Description
Field Design
The tab on which you can add and define fields for the Hologres internal table. For information about the data types supported by Hologres, see Data types.
Storage Design
The tab on which you can specify the storage method for the fields in the Hologres internal table.
Distribution column: the distribution key for the Hologres internal table. Hologres distributes data in the Hologres internal table to each shard based on the distribution key for subsequent data computing and scanning by shard.
Segmented column: a column of a time data type. If event time columns are contained in query conditions, Hologres can find the storage location of data with ease based on the event time columns. This parameter is suitable for logs, traffic, and time-related data.
Cluster column: the columns for which Hologres creates clustered indexes. Hologres sorts data based on clustered indexes. Hologres allows you to use clustered indexes to accelerate RANGE and FILTER queries on indexed columns.
Dictionary encoding column: specifies whether to build dictionary mappings for the values of specific columns. Dictionary mappings can convert string comparisons to numeric comparisons to accelerate queries such as GROUP BY and FILTER.
Bitmap column: specifies whether to build bitmap indexes for specific columns. Bitmap indexes can help filter data that equals a specified value in a stored file. Therefore, we recommend that you convert equality filter conditions to bitmap indexes.
For more information about storage methods, see CREATE TABLE.
Partition
The tab on which you can define a partition field for the Hologres internal table.
NoteIf a partitioned table contains a primary key, the primary key must contain the partition field.
Commit and deploy the Hologres internal table.
After the configuration of the Hologres internal table is complete, you can commit the table to the development and production environments. After the table is committed, you can query the table in the compute engine instance in the related environment.
NoteIf you use a workspace in basic mode, you need to only commit the table to the production environment. For information about workspaces in basic and standard modes, see Differences between workspaces in basic mode and workspaces in standard mode.
Operation
Description
Load from Development Environment
Load the table information from the development environment and display the table information on the current page.
NoteYou can perform this operation only after the table is committed to the development environment. After you perform this operation, the table information in the development environment overwrites the table information on the current page.
Commit to Development Environment
Commit the table to the development environment. This way, the current table is created in the Hologres database in the development environment.
After the table is committed, you can view the table schema in the Hologres folder of the related workflow in DataStudio. The folder is that you specified when you created the table.
Load from Production Environment
Load the table information from the production environment and display the table information on the current page.
NoteYou can perform this operation only after the table is committed to the production environment. After you perform this operation, the table information in the production environment overwrites the table information on the current page.
Commit to Production Environment
Commit the table to the production environment. This way, the current table is created in the Hologres database in the production environment.
What to do next
After the Hologres internal table is created, you can perform the following operations:
Develop Hologres-related data. For more information, see Create a Hologres SQL node and Create Table.
Import MaxCompute data to Hologres internal tables by using Hologres external tables at regular intervals:
Run commands to import data. For more information, see Import data from MaxCompute to Hologres by executing SQL statements.
Perform related operations in the DataWorks console to import data. For more information, see Create a node to synchronize MaxCompute data with a few clicks.