Data Quality enables you to configure monitoring rules for data tables. These rules verify whether your table data meets specified requirements and can automatically block problematic tasks to prevent dirty data from propagating downstream. This ensures that output data conforms to expectations. This topic describes how to configure, execute, and manage quality monitoring rules for a table.
Prerequisites
You must acquire engine metadata before configuring quality monitoring rules. Quality rules are based on engine data tables and apply to the corresponding table data. For more information, see Metadata acquisition.
Limits
Data source limits: You can configure quality monitoring rules only for MaxCompute, E-MapReduce, Hologres, CDH Hive, AnalyticDB for PostgreSQL, AnalyticDB for MySQL, StarRocks, MySQL, SQL Server, DLF, and Lindorm data sources.
Network limits: After you configure a rule, the scheduling node that generates the table data must use a resource group with a stable network connection to trigger the Data Quality rule check.
Rule activation limits: Rules with dynamic thresholds require 21 days of sampling records to function correctly. If fewer than 21 days of records exist, the rule check will be abnormal. If you lack 21 days of sampling records, you can configure the rule, associate it with a scheduling node, and then use the data backfill feature to generate the required 21 days of records.
Core components of quality monitoring

Configuring quality monitoring rules by table is the core process for defining and instantiating data validation logic. This process creates a complete quality monitoring configuration consisting of four key parts:
Monitoring scope: Specifies the target asset for data quality checks. The configuration includes:
Monitored object: Select one or more physical tables to check. Both partitioned and non-partitioned tables are supported.
Timestamp range: For partitioned tables, you must use a partition filter expression to dynamically scan partitions during each check. For example, use
$[yyyymmdd-1]to check the partition data from the day before the data timestamp.
Quality rules: Define the specific validation logic and standards to determine if the data meets expectations.
Rule definition: You can add one or more quality rules to a monitored object. Each rule is instantiated from a rule template, which can be:
System template: A built-in template provided by DataWorks. It covers multiple dimensions such as integrity, uniqueness, and validity. Examples include "Table Row Count Fluctuation" and "Field Unique Value Count".
Custom template: A reusable, personalized validation logic created by users with SQL.
Rule properties: Each rule requires key properties to be configured. These include a threshold (for example, fluctuation rate not exceeding 30%) and a severity level (strong rule or soft rule). If a strong rule check fails, it can block the associated scheduling node.
Trigger methods: Define when the quality monitoring job runs.
Triggered by a scheduling node: Associate the quality monitoring job with an upstream DataWorks scheduling node—typically the node that generates the monitored table. When the scheduling node runs successfully, it automatically triggers the associated quality rules for validation. This is a best practice for automated data quality assurance.
Manual trigger: The validation process is not associated with any scheduling node and must be started manually from the interface. This method is suitable for temporary, one-time data exploration and validation.
Alert policies: Configure the notification strategy for when data quality issues occur.
Alert subscription: You can configure alerts for specific rule check results, such as "Failed" or "Warning". The system supports sending notifications through various channels, including email, text message, phone call, DingTalk, Lark, WeCom group chatbots, and custom Webhooks.
After you configure these four components and save the settings, a complete quality monitoring plan is created. We recommend testing the configuration before publishing it to the production environment.
Procedure
1. Go to the table quality details page
Go to the Data Quality page.
Log on to the DataWorks console. In the top navigation bar, select the desired region. In the left-side navigation pane, choose . On the page that appears, select the desired workspace from the drop-down list and click Go to Data Quality.
Go to the page for configuring monitoring rules by table.
In the navigation pane on the left, click to go to the rule configuration page.
In the Data Source list on the left, select the database that contains the table for which you want to configure a rule.
Filter the tables by database type, database, or table name. Click the target table name or click Rule Management in the Actions column. This takes you to the table quality details page for that table.
This page displays all configured quality monitoring jobs and rules for the current table. You can quickly filter rules based on whether they are associated with a quality monitoring job. You can also define the execution method for rules that are not yet associated with a quality monitoring job.
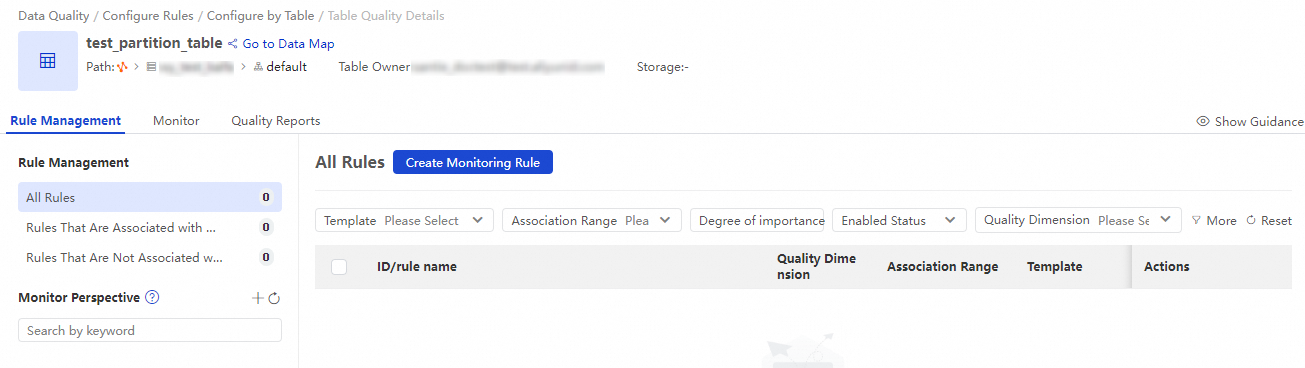
2. Create a quality monitoring job
Create a new quality monitoring job.
You can create a quality monitoring job in one of two ways:
Rule management page
On the Table Quality Details page for the table, click the Rule Management tab. Next to Monitor Perspective, click the
 icon to create a new quality monitoring job.
icon to create a new quality monitoring job.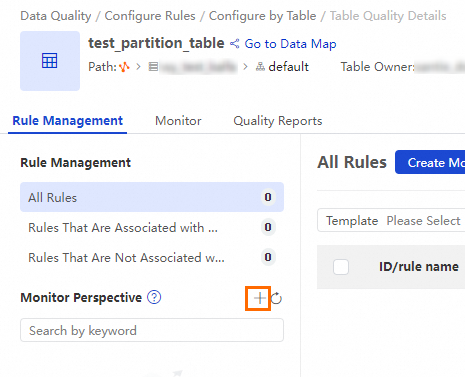
Quality monitoring page
On the Table Quality Details page for the table, switch to the Monitor tab. Click Create Monitor.
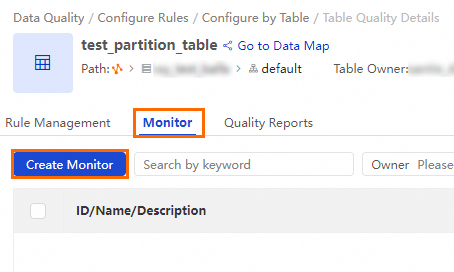
Configure the parameters for the quality monitoring job.
Configuration item
Parameter
Description
Basic Configurations
Monitor Name
Enter a custom name for the monitoring rule.
Quality Monitoring Owner
You can specify the owner of the monitor as needed. When you configure alert subscriptions, you can specify the monitor owner as the alert recipient by using Email, Email and SMS, or Telephone.
Monitored Object
The object for data quality checks. By default, this is the current table.
Data Range
Use a partition filter expression to define the partitions to be checked by the quality rule.
For a non-partitioned table, you do not need to configure this parameter. All data in the table is checked by default.
Partitioned table: The expression format is
partition_name=partition_value. The partition value can be a static field or a built-in partition filter expression from Appendix 2.
NoteThis configuration does not take effect when you use a custom template or custom SQL to configure rules. For rules configured with a custom template or custom SQL, the partitions to be checked are determined by the custom SQL.
Monitoring Rule
Monitoring Rule
Associate quality rules with the quality monitoring job to determine which rules will check if the data in the current timestamp range meets expectations.
NoteYou can create multiple quality monitoring jobs for different partitions and associate them with different quality rules. This lets you apply different validation rules to different partitions.
If you have not yet created a quality rule, you can skip this step for now. Create the quality monitoring job first, and then add the rule to it later. For more information about how to create a quality rule, see 3. Configure Data Quality rules.
Running Settings
Trigger Method
The trigger method for the monitor.
Triggered by Node Scheduling in Production Environment: After the scheduling node that you associate with the monitor finishes running in Operation Center, the rules that are associated with the monitor are automatically triggered. Note that dry-run nodes do not trigger monitoring rules to run.
Triggered Manually: The monitoring rules that are associated with the monitor are manually triggered.
ImportantIf the table whose data quality you want to check is a non-MaxCompute table and Triggered By Node Scheduling In Production Environment is selected for Trigger Method, you cannot associate scheduling nodes that are run on the shared resource group for scheduling with the monitor. Otherwise, an error may be reported when the monitor is run.
Associated Scheduling Node
If you set the Trigger Method parameter to Triggered By Node Scheduling In Production Environment, you can configure this parameter to select the scheduling nodes that you want to associate with the monitor. After the scheduling nodes finish running, the rules that are associated with the monitor are automatically triggered.
Running Resources
The computing resources required to run the quality rule checks. By default, the data source of the monitored table in the workspace is selected. If you select another data source, make sure the corresponding resources can access the table.
Handling Policies
Quality Issue Handling Policies
Configure the blocking or alerting policy to be used when a data quality issue is detected.
Block: When a data quality issue is detected, the system identifies the production scheduling node that triggered the table's quality check. It then sets the node to failed, and downstream nodes will not run. This blocks the production pipeline to prevent the spread of problematic data.
The default is
Strong Rule - Critical Anomaly.Alert: When a data quality issue is detected, an alert message is sent to the alert subscription channels of the quality monitoring job.
The defaults are:
Strong Rule - Critical Anomaly,Strong Rule - Warning Anomaly,Strong Rule - Check Failed,Soft Rule - Critical Anomaly,Soft Rule - Warning Anomaly, andSoft Rule - Check Failed.
Alert Method Configuration
You can send alert notifications by using Email, Email and SMS, DingTalk Chatbot, DingTalk Chatbot @ALL, Lark Group Chatbot, Enterprise Wecha Robot, Custom WebHook, or Telephone.
NoteYou can add a DingTalk chatbot, Lark chatbot, or WeChat chatbot and obtain a webhook URL. Then, copy the webhook URL to the Recipient field in the alert subscription dialog box.
The Custom Webhook notification method is supported only in DataWorks Enterprise Edition. For information about the message format of an alert notification sent by using a Custom Webhook, see Appendix: Message format of alert notifications sent by using a custom webhook URL.
When you select Email, Email and SMS, or Telephone as the notification method, you can specify Recipient as Monitor Owner, Shift Schedule, or Node Owner.
Data Quality Monitoring Owner: Alert information will be sent to the Quality Monitoring Owner set in the Basic Configurations section of the current quality monitor.
Shift Schedule: When the monitoring rule associated with the monitor is triggered and an alert is generated, the system sends alert notifications to the person on duty for the current day in the shift schedule.
Scheduling Task Owner: Alert notifications are sent to the owner of the scheduling node associated with the monitor.
Click Save to create the quality monitoring job.
3. Configure Data Quality rules
You can configure quality rules based on built-in table-level and field-level monitoring templates. For more information about built-in rule templates, see View built-in rule templates.
On the Table Quality Details page, on the Rule Management tab, select the quality monitoring job you created. Then, click Create Rule to go to the rule configuration page.
Create a Data Quality rule.
Data Quality provides the following methods to configure quality monitoring rules. Choose one as needed.
Method 1: Use a system template
Data Quality has dozens of built-in quality rule templates. On the left, click + Use to quickly create a quality monitoring rule from a template. You can add multiple rules at the same time.
You can click + System Template Rule at the top and then modify the Rule Template parameter to select the target rule template.
Method 2: Use a custom template
NoteBefore you use this method to create a rule, you must go to to create a custom rule template. For more information, see Create and manage custom rule templates.
When you reference a custom rule template, the basic configurations of the template, such as FLAG parameter and SQL, are automatically displayed. You can configure the Rule Name parameter based on your business requirements, and the Monitoring Threshold parameter based on the rule type. For example, you must define a normal threshold and a critical threshold for a numeric rule, and you must define a warning threshold in addition to a normal threshold and a critical threshold for a fluctuation-type rule.
Method 3: Use a custom SQL statement
This method lets you customize the data quality validation logic for the table.
Method 4: Use a custom script
Custom script rules support data validation at the hour and minute level. For information on how to write script rules, see Use a system rule template. For example:
- assertion: change 30 minutes ago for max(id) = 15 name: 30-minute difference in max value of id field is 15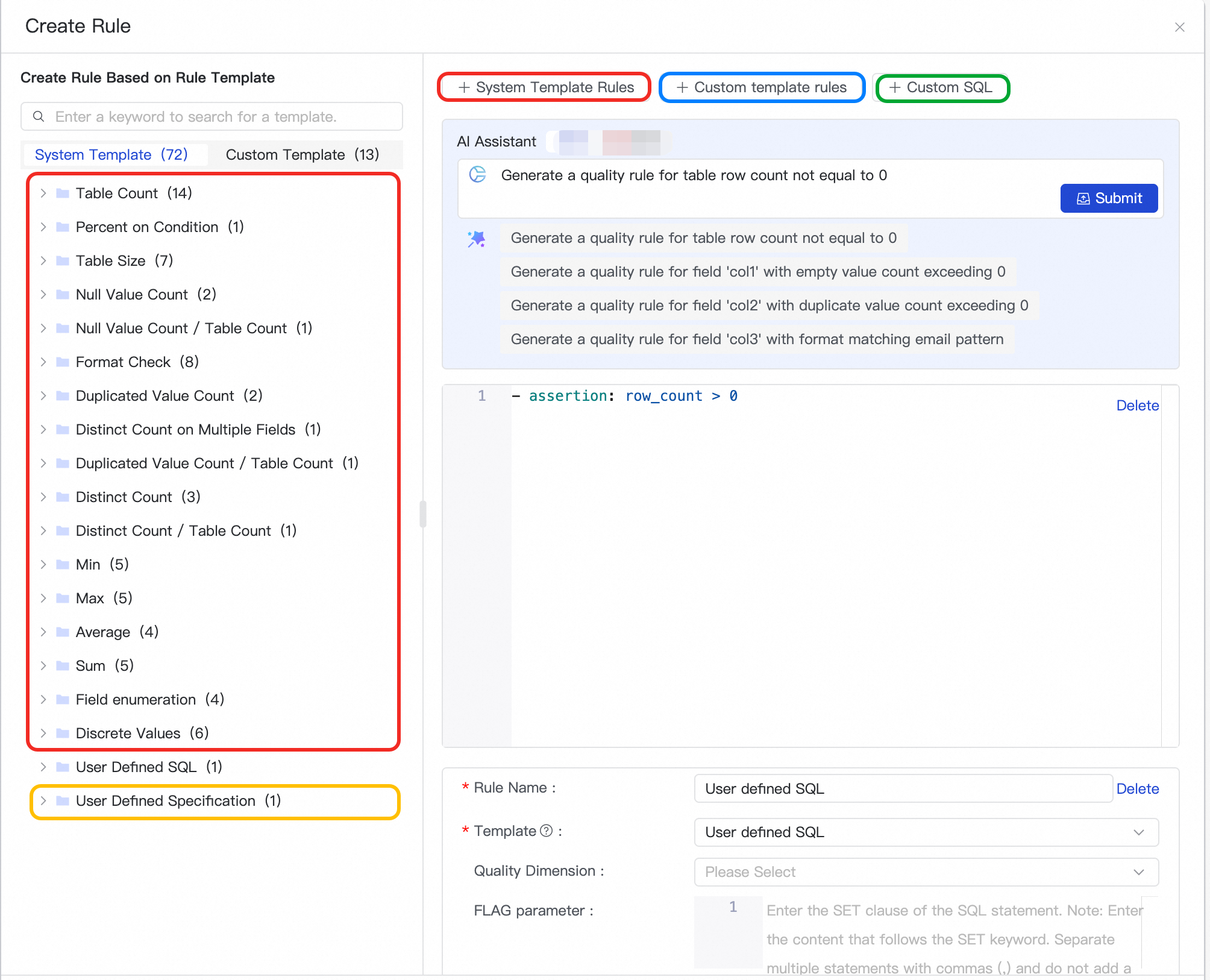
(Optional) You can add the configured rule to a quality monitoring job. For more information about quality monitoring jobs, see 2. Create a quality monitoring job.
NoteThe configured monitoring rule can be triggered only if you add the rule to a monitor. To associate a rule with a monitor, you can select an existing monitor here, or select the rule in the Monitoring Rule section when you configure a monitor.

Click Determine.
4. Test the rule execution
You can test the triggering of rules in a quality monitoring job in the following ways.
Test run from the Rule Management tab
On the Rule Management tab, in the Monitor Perspective, find the quality monitoring job you created and click Test Run.
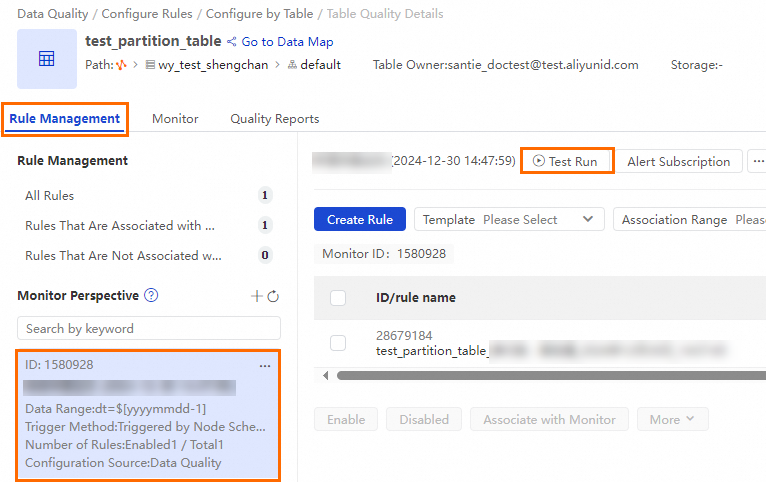
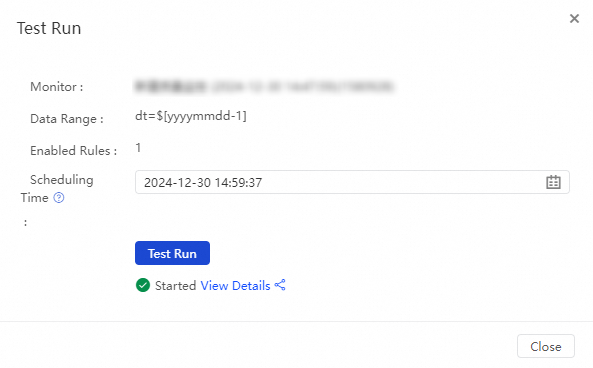
In the Test Run dialog box, check the configurations of parameters, such as Data Range and Scheduling Time, and click Test Run. If Started is displayed, you can click View Details to view results of the test run.
Test run from the Monitor tab
On the Monitor tab, find the created monitor and choose in the Actions column.

In the Test Run dialog box, check the configurations of parameters, such as Data Range and Scheduling Time, and click Test Run. If Started is displayed, you can click View Details to view results of the test run.
5. Modify alert subscriptions
You set up alert subscriptions in Step 2. Create a quality monitoring job. When a rule is triggered, the system sends a notification to the corresponding alert recipient. If you want to modify the alert subscription to notify other users, you can configure it in the following ways.
Subscriptions on the Rule Management tab
On the Rule Management tab, in the Monitor Perspective, find the quality monitoring job you created and open the alert subscription page as shown below.
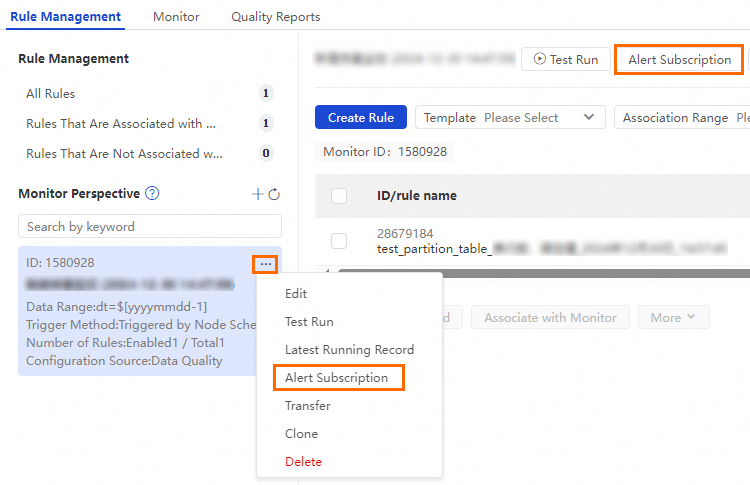
In the Alert Subscription dialog box, add a Notification Method and a Recipient, and then click Save in the Actions column. After you save the configurations, you can configure another subscription with a different notification method and alert recipient.
Data Quality supports the following notification methods: Email, Email and SMS, DingTalk Chatbot, DingTalk Chatbot @ALL, Lark Group Chatbot, Enterprise Wechat Robot, Custom Webhook, and Telephone.
NoteYou can add a DingTalk chatbot, Lark chatbot, or WeChat chatbot and obtain a webhook URL. Then, copy the webhook URL to the Recipient field in the alert subscription dialog box.
The Custom Webhook notification method is supported only in DataWorks Enterprise Edition. For information about the message format of an alert notification sent by using a Custom Webhook, see Appendix: Message format of alert notifications sent by using a custom webhook URL.
When you select Email, Email and SMS, or Telephone as the notification method, you can specify Recipient as Monitor Owner, Shift Schedule, or Node Owner.
Data Quality Monitoring Owner: Alert information will be sent to the Quality Monitoring Owner set in the Basic Configurations section of the current quality monitor.
Shift Schedule: When the monitoring rule associated with the monitor is triggered and an alert is generated, the system sends alert notifications to the person on duty for the current day in the shift schedule.
Scheduling Task Owner: Alert notifications are sent to the owner of the scheduling node associated with the monitor.
Subscribe from the Quality Monitoring tab
On the Quality Monitoring tab, find the quality monitoring job you created, and in the Actions column, click .
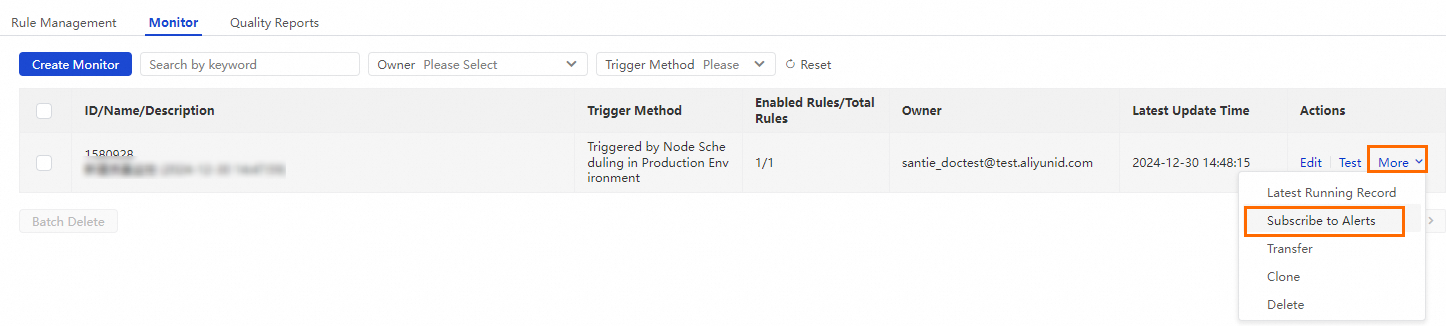
In the Alert Subscription dialog box, add a Notification Method and a Recipient, and then click Save in the Actions column. After you save the configurations, you can configure another subscription with a different notification method and alert recipient.
Data Quality supports the following notification methods: Email, Email and SMS, DingTalk Chatbot, DingTalk Chatbot @ALL, Lark Group Chatbot, Enterprise Wechat Robot, Custom Webhook, and Telephone.
NoteYou can add a DingTalk chatbot, Lark chatbot, or WeChat chatbot and obtain a webhook URL. Then, copy the webhook URL to the Recipient field in the alert subscription dialog box.
The Custom Webhook notification method is supported only in DataWorks Enterprise Edition. For information about the message format of an alert notification sent by using a Custom Webhook, see Appendix: Message format of alert notifications sent by using a custom webhook URL.
When you select Email, Email and SMS, or Telephone as the notification method, you can specify Recipient as Monitor Owner, Shift Schedule, or Node Owner.
Data Quality Monitoring Owner: Alert information will be sent to the Quality Monitoring Owner set in the Basic Configurations section of the current quality monitor.
Shift Schedule: When the monitoring rule associated with the monitor is triggered and an alert is generated, the system sends alert notifications to the person on duty for the current day in the shift schedule.
Scheduling Task Owner: Alert notifications are sent to the owner of the scheduling node associated with the monitor.
Next steps
After the monitor is run, you can choose Quality O&M in the left-side navigation pane and click Monitor and Running Records to view the quality check status of the specified table and the complete quality rule check records.
Appendix
Appendix 1: Formulas for fluctuation rate and variance
Fluctuation rate formula:
Fluctuation rate = (Sample value - Baseline value) / Baseline valueSample value: The specific value of the sample collected on the current day. For example, for a 1-day fluctuation check of the table row count in an SQL task, the sample is the row count of the current day's partition.
Baseline value: The comparison value from historical samples.
NoteIf the rule is a
1-day fluctuation rate of table row countcheck for an SQL task, the baseline value is the table row count from the previous day's partition.If the rule is a
7-day average fluctuation rate of table row countcheck for an SQL task, the baseline value is the average of the table row data from the previous 7 days.
Variance fluctuation formula:
(Current sample - Average of last N days) / Standard deviationNoteVariance can only be used for numeric types such as BIGINT and DOUBLE.
Appendix 2: Built-in partition filter expressions
Scenario:
The data timestamp (bizdate) is
20240524.Scheduled time is
10:30:00
Partition Filter Expression | Check Target Description | Example (Based on the scenario) |
| Checks the partition data of the current data timestamp. |
|
| Checks the partition data from the day before the data timestamp. |
|
| Checks the partition data from 7 days before the data timestamp (one week ago). |
|
| Checks the partition data from the same day of the previous month as the data timestamp. |
|
| Checks the partition for the current data timestamp, accurate to the current scheduled time (second level). |
|
| Checks the second-level partition data at midnight of the current data timestamp. |
|
| Checks the second-level partition data from one hour before the scheduled time on the current data timestamp. |
|
| (For hourly partitions) Checks the partition from one hour before the scheduled time. The format is usually |
|
| (For minute-level partitions) Checks the partition from 30 minutes before the scheduled time. The format is usually |
|
| (For subpartitions) Checks all hourly partition data from the day before the data timestamp. | All partitions from |