This topic provides answers to some frequently asked questions about data backfilling.
I enable the data backfilling feature for a node, but no data backfill instances are generated. Why?
How do I backfill data for nodes that are scheduled to run by week or month?
What is the data backfilling feature used for?
You can use the data backfilling feature to backfill data of a historical period of time or a period of time in the future for an auto triggered node. The scheduling parameters that you configured for the node are automatically replaced with specific values based on the data timestamp that you specified to backfill data for the node. The following figure shows how to write incremental data from a MySQL data source to a specified time-based partition in MaxCompute. 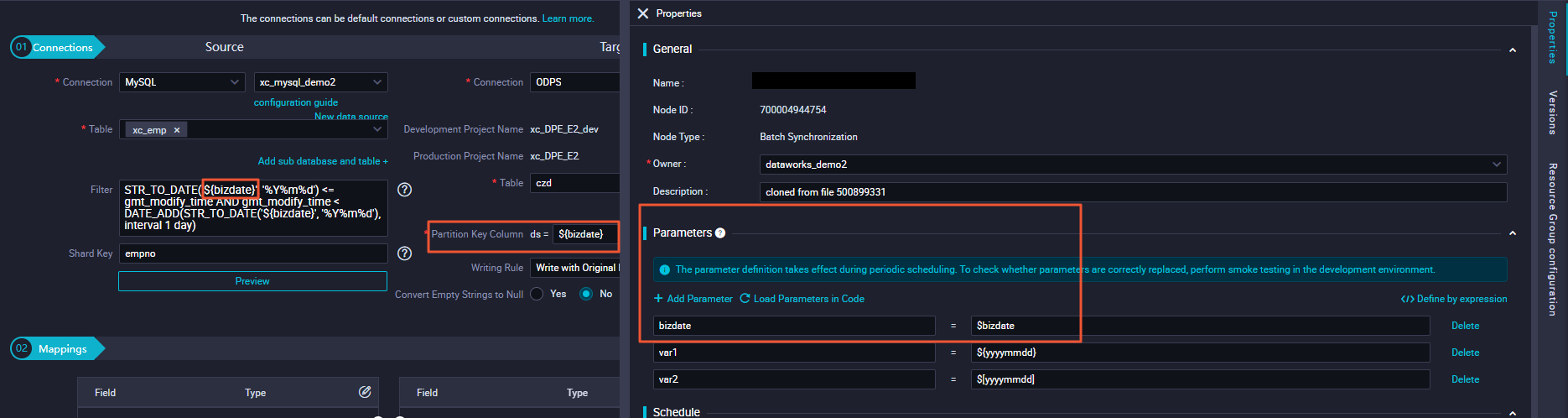
The data backfill instances for a node that is scheduled to run by hour or minute do not run in parallel after I enable the parallelism feature for the data backfill instances. What do I do?
Problem description
The data backfill instances for a node that is scheduled to run by hour or minute do not run in parallel after the parallelism feature is enabled for the data backfill instances.
Cause
The parallelism feature allows you to run multiple data backfill instances for a daily scheduled node in parallel to backfill data for the node for a number of days based on the data timestamp. If you backfill data for a node that is scheduled to run by hour or minute, whether all data backfill instances that are generated for the node on the current day can be run in parallel is not controlled by the parallelism feature, but depends on whether you configure the self-dependency for the node. For more information about self-dependency, see Scenario 2: Configure scheduling dependencies for a node that depends on last-cycle instances.
Solution
If you do not enable the parallelism feature, only one data backfill instance is generated. The data backfill instance is run multiple times in sequence based on the data timestamp.
If you enable the parallelism feature, you can specify a maximum of 10 data backfill instances to backfill data for the node at the same time. The data backfill instances are run in parallel based on the data timestamp.
Scenario: You want to backfill data of a week for a node that is scheduled to run by hour or minute.
If you configure the self-dependency for the node, one data backfill instance is run multiple times in sequence on each day based on the data timestamp.
If you do not configure the self-dependency for the node, multiple data backfill instances are run in parallel on each day based on the data timestamp.
The data backfill instances for a node are not run after I specify the data timestamp for data backfilling. The data backfill instances are in the Pending (Schedule) state and are highlighted in yellow in the DAG of the node. Why does this happen?
Problem description
The data backfill instances for a node are not run after the data timestamp for data backfilling is specified. The data backfill instances are in the Pending (Schedule) state and are highlighted in yellow in the directed acyclic graph (DAG) of the node.
Cause
When you backfill data for a node, if you set the Data Timestamp parameter to a time range that is later than the current time, the data backfill instances for the node are in the Pending (Schedule) state.
Solution
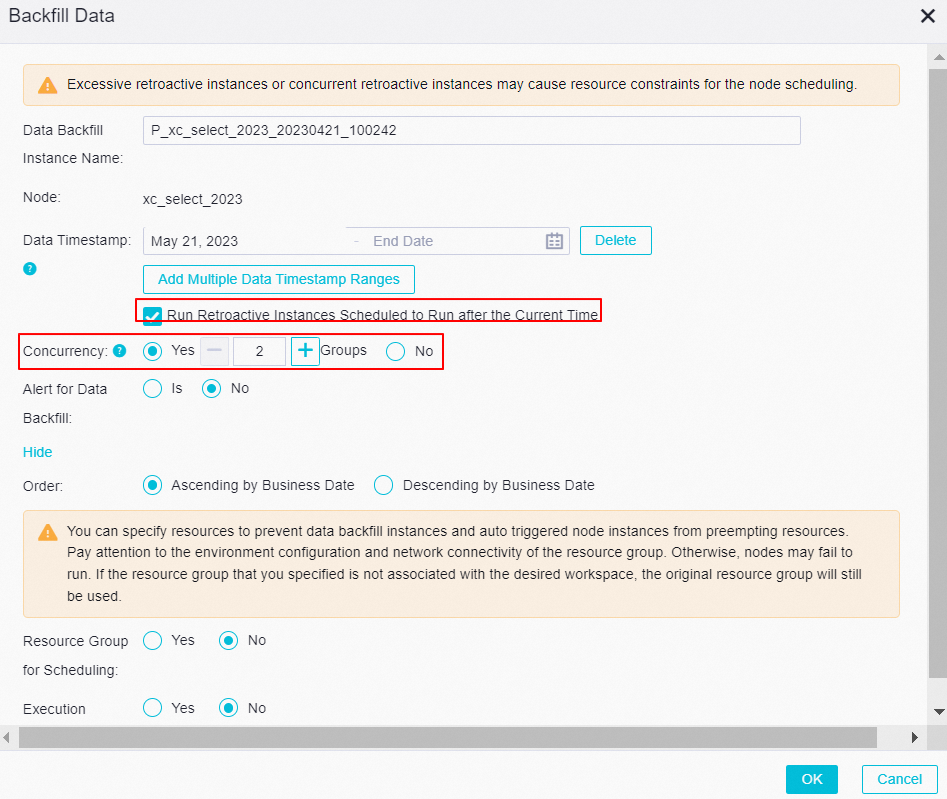
Select the Run Retroactive Instances Scheduled to Run after the Current Time check box.
 Note
NoteIf you set the Data Timestamp parameter to a future time range and do not select the Run Retroactive Instances Scheduled to Run after the Current Time check box, the data backfill instances are in the Pending (Schedule) state and are highlighted in yellow in the DAG of the node for which you backfill data.
If you set the Data Timestamp parameter to a future time range and select the Run Retroactive Instances Scheduled to Run after the Current Time check box, DataWorks runs the data backfill instances immediately after the data timestamp passes.
Why is a data backfill instance for an auto triggered node in the Pending (Schedule) state after I specify the previous day or the current day for the Data Timestamp parameter?
Problem description
A data backfill instance for an auto triggered node is in the Pending (Schedule) state after the previous day or the current day is specified for the Data Timestamp parameter.
Cause
DataWorks runs an auto triggered node on the current day based on the data whose data timestamp is of the previous day. The process of backfilling data of a specific data timestamp for an auto triggered node is equivalent to the process of rerunning the instance that is generated for the node based on the data timestamp.
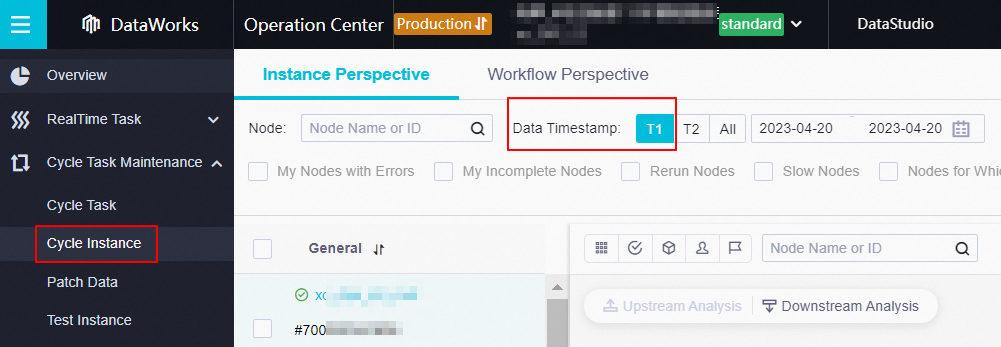
To search for an auto triggered node instance that is scheduled to run on the current day, set the Data Timestamp parameter to T1 on the Cycle Instance page in Operation Center. The data timestamp of the instance is the previous day and the time at which the instance is scheduled to run is the current day.
Why are multiple data backfill instances generated for a node when I backfill data of a time range from 00:00 to 01:00 for the node?
Problem description
When you backfill data of a time range from 00:00 to 01:00 for a node, multiple data backfill instances are generated for the node.
Cause
The number of data backfill instances that are generated for a node varies based on the scheduling time that you specified for the node.
Example 1: You configure a node to be scheduled every hour from 00:00 to 23:59. If you backfill data of a time range from 00:00 to 01:00 for the node, two data backfill instances are generated and scheduled to run at 00:00 and 01:00, separately.
Example 2: You configure a node to be scheduled every 30 minutes from 00:00 to 23:59. If you backfill data of a time range from 00:00 to 01:00 for the node, three data backfill instances are generated and scheduled to run at 00:00, 00:30, and 01:00, separately.
If a large number of data backfill instances are generated for a node, some of the data backfill instances are in the Pending (Resources) state and are highlighted in yellow in the DAG of the node. Why does this happen?
Problem description
If a large number of data backfill instances are generated for a node, some of the data backfill instances are in the Pending (Resources) state and are highlighted in yellow in the DAG of the node.
Cause
The number of parallel threads that are supported by a resource group is limited. If the number of parallel instances of a node exceeds the number of supported parallel threads, the excessive instances are in the Pending (Resources) state.
NoteFor information about how to troubleshoot the issue, see Nodes that are waiting for resources.
I receive an error message, which indicates that the scheduling time of a node for which data backfilling is required is not within the specified data timestamp range. Why?
Problem description
An error message is returned, which indicates that the scheduling time of a node for which data backfilling is required is not within the specified data timestamp range.
Cause
A time range for scheduling is not specified for a node that is scheduled to run by hour or minute. As a result, data backfill instances are not generated for the node.
I enable the data backfilling feature for a node, but no data backfill instances are generated. Why?
Problem description
The data backfilling feature is enabled for a node, but no data backfill instances are generated.
Cause
Data backfill instances can be generated only for a node whose scheduling time is within the specified effective period of scheduling. Make sure that the scheduling time of the node meets the requirement.
How do I backfill data for nodes that are scheduled to run by week or month?
Description: When you backfill data for nodes that are scheduled to run by week or month, select the previous day before the scheduling time as the data timestamp. For a node that is scheduled to run on a specific day every week or on a specific day every month, the scheduling system runs the node only on that day every week or month. On the other days, dry-run instances are generated but the scheduling system does not actually run the node. For more information, see Scenario 1: An instance is scheduled to run on a specific day every week or every month.
NoteThe time selected for data backfilling is the data timestamp. The data timestamp is calculated by using the following formula:
Data timestamp = Scheduling time of the node for which you want to backfill data - 1.For information about relationships between scheduling parameters and the data timestamp, scheduling time, and actual running time of a node, see Appendix: Relationships between scheduling parameters and the data timestamp, scheduling time, and actual running time of a node.
Sample scenario: Backfill data for a node scheduled to run by month
When you backfill data for a node scheduled to run by month, if the node is scheduled to run at 00:00 on the first day of every month, set the data timestamp for data backfilling to the last day of the previous month.
