Data Lake Analytics (DLA) lakehouse is a real-time data ingestion solution. This solution uses data lake technologies to rebuild the semantics of data warehouses and analyzes data in data lakes by using data warehousing. This topic describes how to use the DLA lakehouse solution to ingest data from ApsaraDB RDS for MySQL into a data lake and analyze the data.
Background information
- Data from diverse sources needs to be stored and managed in a centralized manner. An easy method is required to integrate and analyze data.
- The metadata of a data source is not deterministic or may be significantly changed. Therefore, the metadata needs to be automatically identified and managed. The timeliness of simple metadata discovery features does not meet your requirements.
- If you analyze data by using full data warehousing or by directly connecting DLA to source databases, loads on the source databases are heavy. You need to reduce loads to prevent failures.
- Data warehousing is time-consuming, which usually requires T+1 days. Data ingestion into a data lake requires only T+10 minutes.
- Frequent data updates cause a large number of small files to be generated. This results in poor analytics performance. Upsert operations are required to automatically merge small files.
- A large amount of data is stored in transaction libraries or traditional data warehouses, which is not cost-effective. Low-cost data archiving is required.
- Source databases are row-oriented or non-analytic databases that have poor analytics performance. Column-oriented databases are required.
- The O&M costs of a self-managed big data platform are high. A service-oriented, cloud-native, end-to-end solution is required.
- The storage system of a common data warehouse does not provide external services. A self-managed, open source, controllable storage system is required.
Lakehouse is an advanced paradigm and solution. It solves the preceding pain points that you may encounter during data ingestion. The key technology of a lakehouse is multiversion concurrency control (MVCC). This technology provides the following capabilities during data ingestion and analytics: real-time incremental data writing, atomicity, consistency, isolation, durability (ACID) transactions, automatic merging and optimization of small files across versions, metadata check, automatic evolving, high-efficiency column-oriented analytical formats, high-efficiency index optimization, and data storage of ultra-large partitioned tables. The open source community provides a variety of table formats that can be used to build a lakehouse. These formats include Delta Lake, Apache Iceberg, and Apache Hudi. Alibaba Cloud DLA uses Apache Hudi for the DLA lakehouse solution. For more information about lakehouses, see What is a Lakehouse?
Core concepts and limits
- Lakehouse has two layers of meanings:
- Paradigm: solves the pain points that you may encounter during data ingestion and analytics.
- Storage space: provides a storage space to store data that is ingested from a data
source into a data lake. All the subsequent operations are performed for this lakehouse.
- Each lakehouse has a directory that is different from the directories of other lakehouses. These directories cannot have nested relationships with each other. This prevents data from being overwritten.
- Data in a lakehouse cannot be modified unless necessary.
- Workloads are used to orchestrate and schedule core jobs that are run for a lakehouse.
All the workloads are controlled by the DLA lakehouse solution. Workloads have the
following features:
- Data ingestion and warehousing
- Data is ingested from different sources into a lakehouse to develop a unified data platform. For example, you can ingest data from databases or Kafka into a data lake to build a data warehouse. You can also build a data warehouse based on Object Storage Service (OSS) after data types of the OSS data are converted.
- Different types of data ingestion and warehousing tasks involve multiple stages, such as full synchronization and incremental synchronization. The DLA lakehouse solution orchestrates and schedules these tasks in a centralized manner. This reduces management costs.
- Query optimization
To improve analytics capabilities, the DLA lakehouse solution creates workloads for query optimization. For example, the solution can automatically create indexes, clear historical data, and create materialized views.
- Management
- Cost optimization: automatic lifecycle management and tiered storage of cold and hot data
- Data exchange: cross-region data warehousing
- Data security: backup and restoration
- Data quality: automatic check provided by Data Quality Center (DQC)
- Data ingestion and warehousing
- Operations on jobs, such as job splitting, execution, and scheduling are not visible
to users. DLA can schedule jobs to only the serverless Spark engine. Core concepts:
- Jobs for full synchronization (jobs split from a workload)
- Jobs for incremental synchronization (jobs split from a workload)
- Clustering: small file merging
- Indexing: automatic indexing
- Compaction: automatic log merging
- Tier: automatic tiered storage
- Lifecycle: automatic lifecycle management
- Materialized view
- Database: databases of DLA
- Table: tables of DLA
- Partition: partitions of DLA tables
- Column: columns of DLA tables
Solution introduction
The DLA lakehouse solution is a near-real-time solution that ingests data into a data lake in minutes. It can build a unified lakehouse that stores a large amount of data at low costs and can automatically synchronize metadata. This solution uses the serverless Spark engine to compute data and uses the serverless Presto engine to analyze data. The DLA lakehouse solution separates data storage from data computing. It allows you to write, store, and read data on demand.
Preparations
- Activate DLA.
- Create a virtual cluster.
Note DLA runs a lakehouse on the serverless Spark engine. Therefore, you must set Engine to Spark when you create a virtual cluster.
- Create an ApsaraDB RDS for MySQL instance.
Note The DLA lakehouse solution supports only the virtual private cloud (VPC) network. Therefore, when you create an ApsaraDB RDS for MySQL instance, you must set the network type to VPC.
- Create databases and accounts for an ApsaraDB RDS for MySQL instance.
- Use DMS to log on to an ApsaraDB RDS for MySQL instance.
- Enter the SQL statements that you want to execute in the code editor of the SQLConsole tab and execute these statements to create a database table and insert data into the table.
- Track data changes from an ApsaraDB RDS for MySQL instance.
Note
- The DLA lakehouse solution supports only the VPC network. Therefore, you must set Network Type to VPC when you configure a subscription task.
- The DLA lakehouse solution cannot automatically update metadata. Therefore, you must select Data Updates and Schema Updates for Required Data Types.
- Create consumer groups.
- Query the subscribed topic and consumer group ID. The query result is used for subsequent
incremental synchronization that is used to create a workload for data ingestion.
- Query the subscribed topic from the configurations of the subscription task.
- Query the consumer group ID on the Change Tracking Tasks page.
- Activate OSS.
- Create buckets.
Note The DLA lakehouse solution writes data to an empty directory of OSS. To separately manage data, we recommend that you select a separate OSS bucket.
Make sure that the ApsaraDB RDS for MySQL instance from which you want to synchronize data is deployed in the same region as DTS, DLA, and OSS.
Procedure
- Build a lakehouse.
- On the page that appears, configure the parameters. The following table describes
these parameters.

Parameter Description Name of Lake Warehouse The name of the lakehouse that you want to build. Description information The description of the lakehouse. For example, you can enter the scenario or limits of the lakehouse. Storage type The type of the storage system in which data of the lakehouse is stored. Select OSS from the drop-down list. Storage path The OSS directory in which data of the lakehouse is stored. Note Set this parameter based on your business requirements. It cannot be modified after you configure this parameter. We recommend that you select an empty directory that does not have nested relationships with the existing lakehouse directories. This prevents historical data from being overwritten.Coding The encoding format of the stored data. Select UTF8 from the drop-down list.
After the lakehouse is created, it is displayed on the List of Lake Stores tab.
- On the page that appears, configure the parameters. The following table describes
these parameters.
- Create a workload for data ingestion.
- On the data source tab of the New workload page, configure parameters in the Basic configuration, Full synchronization configuration, Incremental synchronization configuration, and Generate target data rule configuration sections. Note Only RDS and PolarDB data sources are supported.
- The following table describes the parameters in the Basic configuration section.
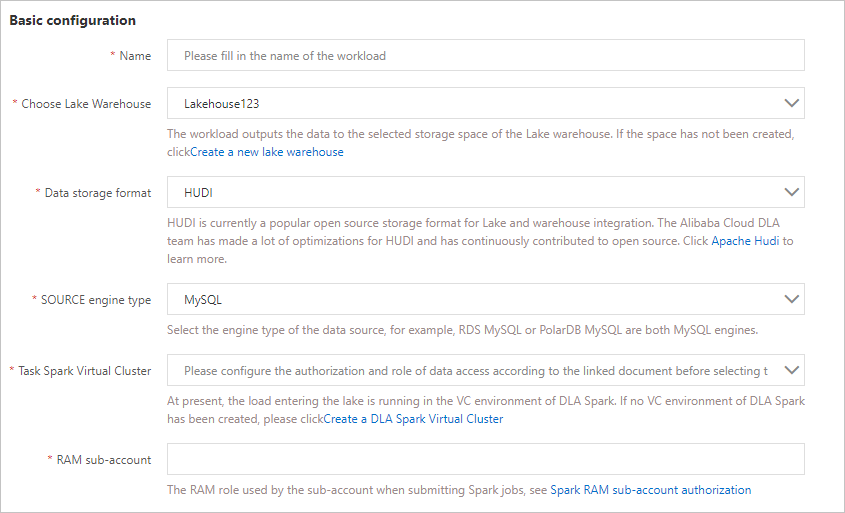
Parameter Description Name The name of the workload that you want to create. Choose Lake Warehouse The lakehouse in which the output data of the workload is stored. Select the created lakehouse from the drop-down list. Data storage format Select HUDI from the drop-down list. SOURCE engine type The engine type of the data source. Select MySQL from the drop-down list. Task Spark Virtual Cluster The name of the virtual cluster on which the Spark job runs. The workload for data ingestion runs in the Spark virtual cluster of DLA. If a virtual cluster is not created, you can create one. For more information, see Create a virtual cluster. Note Make sure that the cluster that you selected runs as expected. Otherwise, the workload fails to start. - The following table describes the parameters in the Full synchronization configuration section.
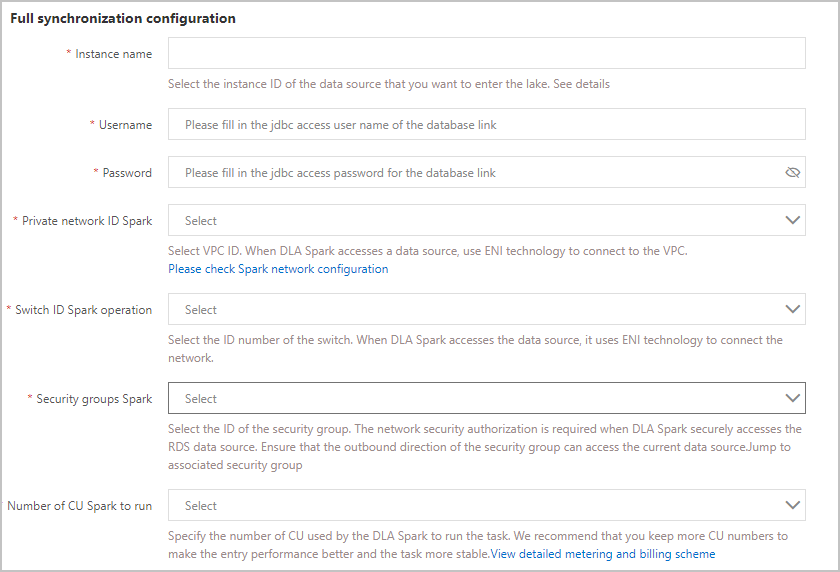
Parameter Description Instance name The name of the data source instance from which data is ingested. Username The username that is used to access the data source instance. Password The password that is used to access the data source instance. Private network ID Spark The ID of the VPC. The serverless Spark engine of DLA uses an elastic network interface (ENI) that is bound to the VPC to access data sources. For more information about how to configure a VPC for the serverless Spark engine of DLA, see Configure the network of data sources. Switch ID Spark operation The ID of the vSwitch in the VPC in which the serverless Spark engine resides. Security groups Spark The ID of the security group that is used for network security authorization when the serverless Spark engine of DLA accesses a data source. You can obtain the security group ID on the Data Security page of the RDS instance. If no security group is added, you can add a security group. For more information, see Configure a security group for an ApsaraDB RDS for MySQL instance. Number of CU Spark to run The number of compute units (CUs) that are used to run Spark jobs of DLA. We recommend that you reserve some CUs to improve data ingestion performance and the stability of Spark jobs. - The following table describes the parameters in the Incremental synchronization configuration section.
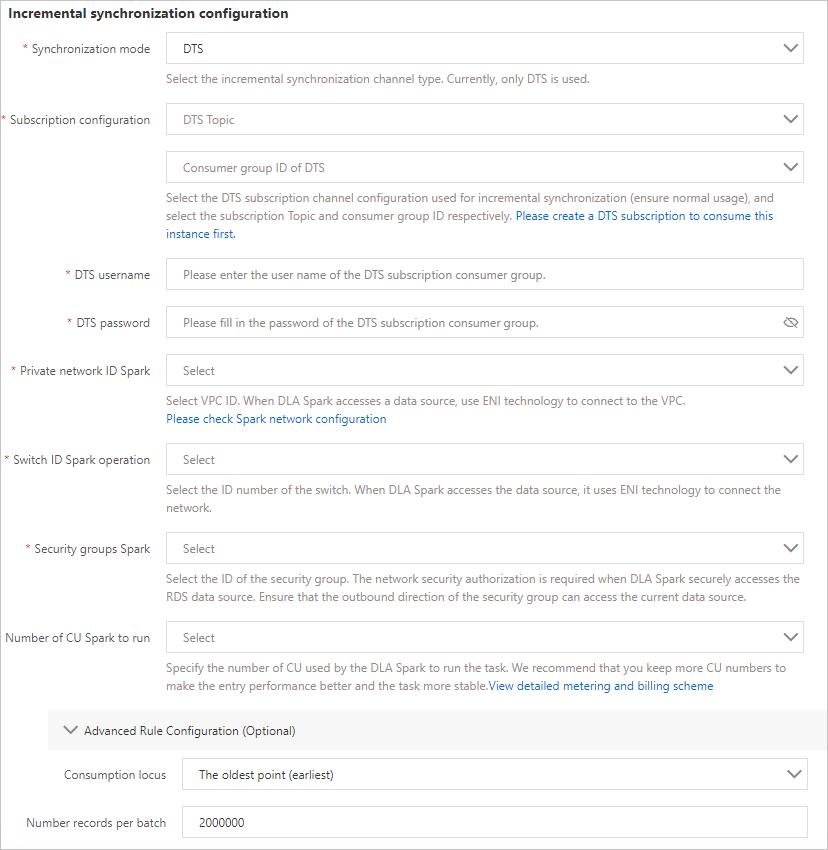
Parameter Description Synchronization mode The type of the channel that is used for incremental synchronization. Select DTS from the drop-down list. Subscription configuration The configuration of the DTS subscription channel used for incremental synchronization. Select the subscribed topic or consumer group ID from the drop-down list. DTS username The username of the consumer group for DTS data subscription during incremental synchronization. DTS password The password that corresponds to the username. Private network ID Spark The ID of the VPC. The serverless Spark engine of DLA uses an elastic network interface (ENI) that is bound to the VPC to access data sources. For more information about how to configure a VPC for the serverless Spark engine of DLA, see Configure the network of data sources. Switch ID Spark operation The ID of the vSwitch in the VPC in which the serverless Spark engine resides. Security groups Spark The ID of the security group that is used for network security authorization when the serverless Spark engine of DLA accesses a data source. You can obtain the security group ID on the Data Security page of the RDS instance. If no security group is added, you can add a security group. For more information, see Configure a security group for an ApsaraDB RDS for MySQL instance. Number of CU Spark to run The number of compute units (CUs) that are used to run Spark jobs of DLA. We recommend that you reserve some CUs to improve data ingestion performance and the stability of Spark jobs. Advanced Rule Configuration (Optional) - Consumption offset: the time when data is consumed. Select earliest from the drop-down list. This value indicates that the system automatically obtains data from the earliest time.
- Number records per batch: the amount of data extracted by DTS at a time.
- The following table describes the parameters in the Generate target data rule configuration section.
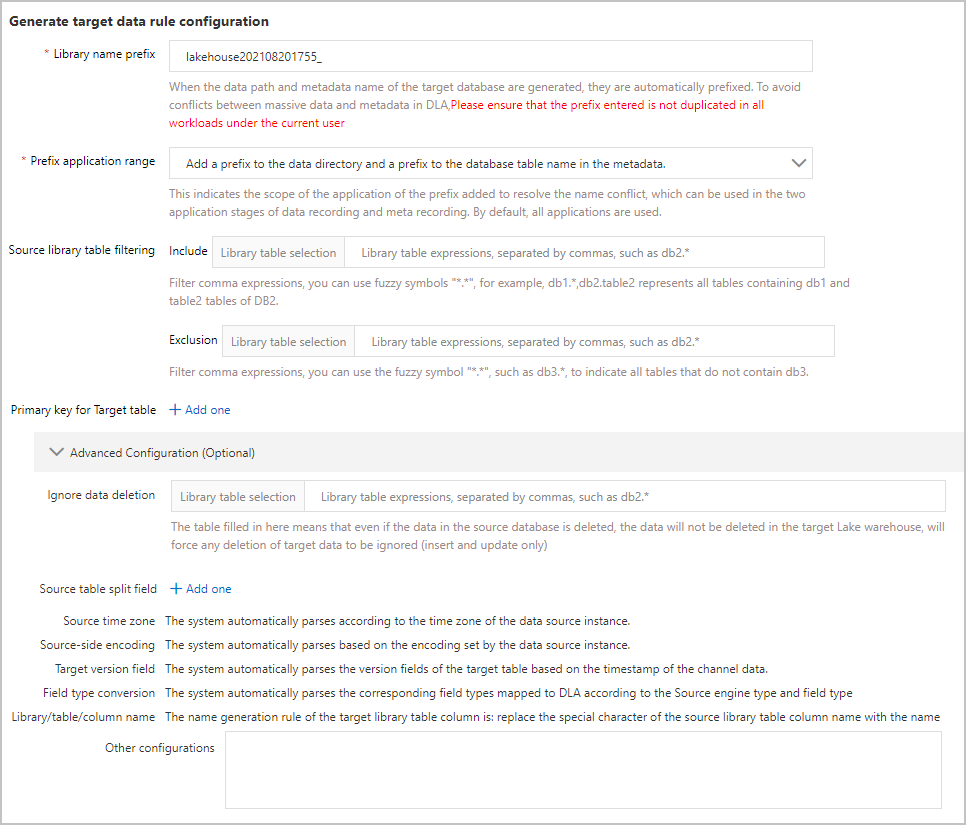
Parameter Description Library name prefix The prefix that is automatically added when the data path and metadata name of the destination database are generated. To prevent conflicts between a large amount of data and metadata in DLA, make sure that the prefix that you entered is unique among all workloads within your Alibaba Cloud account. Prefix application range The application scope of the database name prefix. Valid values: - Add a prefix to the data directory and a prefix to the database tablename in the metadata.
- The data directory is not prefixed, and the database table name in the metadata is prefixed.
Source library table filtering The databases and tables from which data needs to be synchronized. The priority of Exclusion is higher than that of Include. Primary key for Target table The primary key of the specified database table. For example, if you enter db1.user_*in the Library table selection field andf1,f2in the Primary key field, the tables with the prefixuser_in thedb1database use thef1 and f2fields as the primary keys.Note If you do not configure this parameter, the system attempts to use primary keys or unique keys in the table in sequence as the primary keys for the destination table. If the primary key or unique key does not exist in the table, the system determines that synchronization is not required.Advanced Configuration (Optional) Ignore data deletion: the partition field of the specified database table. For example, if you specify
db1.user_*as the database table andgmt_createas the partition field, all the tables with the prefixuser_in thedb1database use thegmt_createfield as the partition field. If you do not configure this parameter, the generated table is not partitioned by default.
- The following table describes the parameters in the Basic configuration section.
After a workload is created, it is displayed on the Workload list tab. - On the data source tab of the New workload page, configure parameters in the Basic configuration, Full synchronization configuration, Incremental synchronization configuration, and Generate target data rule configuration sections.