This topic describes how to create and run Spark jobs in the Data Lake Analytics (DLA) console.
Prerequisites
A virtual cluster is created. For more information about how to create a virtual cluster, see Create a virtual cluster.
NoteWhen you create a virtual cluster, you must set Engine to Spark.
If you log on to the DLA console as a RAM user, the RAM user must be authorized to submit Spark jobs. For more information, see Grant permissions to a RAM user (detailed version). If SparkPi is used, DLA does not need to access external data sources. You need only to bind a DLA sub-account to the RAM user and grant the RAM user the permissions to access DLA.
Procedure
Log on to the DLA console.
In the top navigation bar, select the region in which DLA resides.
In the left-side navigation pane, choose Serverless Spark > Submit job.
On the Parameter Configuration page, click Create a job Template.
In the Create a job Template dialog box, configure the parameters.
Parameter
Description
File Name
The name of the folder or file. File names are not case sensitive.
Data Format
The data format. You can select File or Folder from the Data Format drop-down list.
Parent
The root directory of the file or folder.
All jobs must be created in the Job List directory.
You can create a folder in the Job List directory and create jobs in the created folder. You can also directly create jobs in the Job List directory.
Job type
The type of the job. Valid values:
SparkJob: a Spark job that is written in Python, Java, or Scala. You need to enter job configurations in the JSON format in the code editor.
SparkSQL: a Spark SQL job. You can use SET commands to configure the job. For more information, see Spark SQL.
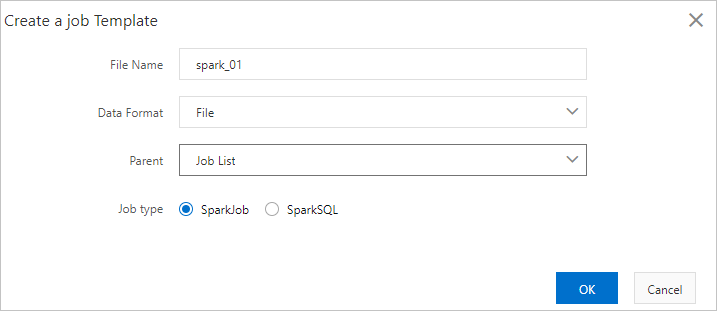
Click OK to create a Spark job.
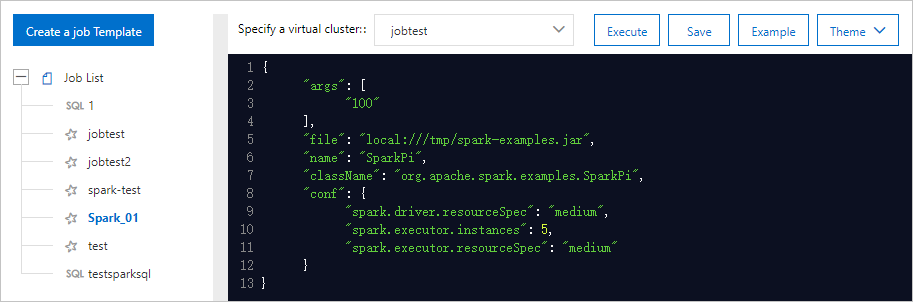
Write the configurations of the job in the code editor. For more information, see Configure a Spark job.
After the configurations of the job are written, you can perform the following operations:
Click Save to save the Spark job. Then, you can reuse the job if needed.
Click Execute to run the Spark job. Then, you can check the status of the job on the Job list tab in real time.
On the Parameter Configuration page, click Example to view the configurations of a sample SparkPi job in the code editor. You can click Execute to run this sample job.
(Optional) On the Job list tab, view the job status or perform operations on the job.
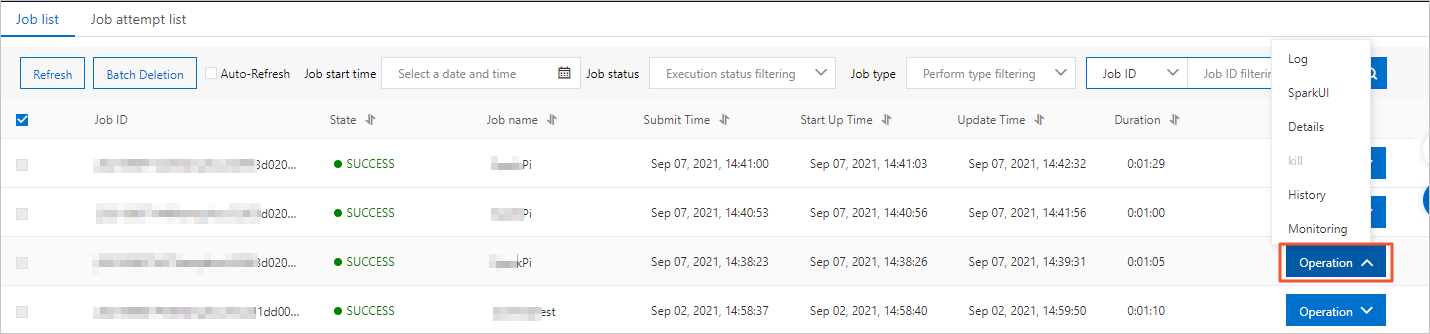
Parameter
Description
Job ID
The ID of the Spark job, which is generated by DLA.
State
The status of the Spark job. Valid values:
STARTING: indicates that the Spark job is being submitted.
RUNNING: indicates that the Spark job is running.
SUCCESS: indicates that the Spark job succeeds.
DEAD: indicates that an error occurs when the Spark job is running. You can view the job logs for troubleshooting.
KILLED: indicates that the Spark job is terminated.
Job name
The name of the Spark job that you created.
Submit Time
The time when the Spark job is submitted.
Start Up Time
The time when the Spark job starts to run.
Update time
The time when the status of the Spark job changes.
Duration
The time consumed to run the Spark job.
Operation
This parameter has the following options:
Log: allows you to query the log information of the Spark job. The first 300 lines in the job log can be queried.
SparkUI: provides the URL to access the Spark web UI. You can query the job information on the Spark web UI. If the token expires, click Refresh to obtain the updated URL of the Spark web UI.
Details: allows you to view the JSON script that is used to submit the Spark job.
Kill: allows you to terminate the Spark job.
History: allows you to query the retry attempts for the job.
Monitoring: allows you to query the monitoring data of the job.
(Optional) Click the Job attempt list tab to query the retry attempts for all the jobs.
NoteBy default, one job can be retried only once. To retry a job several times, configure the job attempt parameters. For more information, see Configure a Spark job.
On the Job attempt list tab, find the job and click History in the Operation column to query the retry attempts for the job.

Appendix
DLA provides demo code for developing Spark jobs. You can visit GitHub to obtain the demo code. You can directly download the demo code and run an mvn command to package the code. We recommend that you follow the instructions in this topic to configure the POM file and develop a Spark job.
Use Data Management (DMS) to orchestrate and periodically schedule Spark jobs. For more information, see Use the task orchestration feature of DMS to train a machine learning model.
Configure a Spark job. For more information, see Configure a Spark job.