The Auto Scaling feature of Database Autonomy Service (DAS) monitors the real-time performance data of database instances. Based on the data, DAS detects traffic exceptions and recommends appropriate specifications and disks. This enables database services to automatically scale storage and computing resources.
Background information
Database O&M staff often face the issue of how to choose appropriate database specifications including CPU cores and memory for business applications. Excessively high specifications cause a waste of resources. Excessively low specifications result in insufficient computing resources and affect your business.
In most cases, O&M staff use specifications that can meet the CPU requirements of stable business traffic. For example, O&M staff may use the specifications of 4 CPU cores and 8 GB memory to keep the CPU utilization below 50%. In addition, O&M staff use relatively high disk specifications, such as 200 GB, to ensure the stable operation of the business.
However, O&M staff of database applications often encounter traffic spikes that exhaust database resources. This issue may occur in various scenarios:
When a new service is released, the actual amount of business traffic exceeds the estimated amount. This causes the resources to be exhausted. For example, a large amount of traffic is routed to a newly released application or a new feature is released on a high-traffic platform.
In some scenarios, unpredictable traffic surges occur. For example, an event or celebrity incurs heated public discussions, or an influencer leads a fashion trend and a sudden shopping spree.
In some scenarios, infrequent but centralized access is required, such as daily punch-in and punch-out activities or financial accounting tasks that are performed several times a week. In such scenarios, the business pressure is low on most occasions. To save resources, O&M staff often do not allocate high specifications, despite the known peak hours of access.
In most cases, O&M staff are unprepared for the abrupt occurrences of lack of computing resources, which has a severe impact on business. One of the challenges that O&M staff often handle is how to deal with resource insufficiency.
Computing resources or storage resources of databases may be exhausted:
When computing resources are exhausted, the CPU utilization reaches 100% and the computing capabilities that are associated with the current specifications cannot meet the business requirements.
When storage resources are exhausted, the disk space usage reaches 100% and the amount of data that is written to the database reaches the upper limit for the current specifications. In this case, new data cannot be written to the business system.
To resolve the preceding two types of issues, DAS provides innovative services so that database services can automatically scale storage and computing resources.
This topic describes the technical challenges, solutions, and core technologies of DAS Auto Scaling.
Technical challenges
You can change the specifications of computing resources to improve the performance of databases. Computing resources consist of only CPU cores and memory, but changing the specifications in the production environment may involve multiple operations, such as data migration, high-availability (HA) switchovers, and proxy switching. This may cause substantial impacts and affect your business.
In most cases, when business traffic spikes occur, computing resources become insufficient and the CPU utilization may even reach 100%.
Can the capacity increases resolve the issue of insufficient resources?
When databases are used, the 100% CPU utilization is merely one of the symptoms that occur due to insufficient computing resources. This symptom can be caused by various root causes and the issue can be resolved by using different solutions:
For example, you may encounter business traffic spikes and the resources associated with the current specifications cannot meet the computing requirements. In this case, you can perform auto scaling at appropriate points in time for capacity increases.
In another example, a large number of slow SQL statements cause congestion in task queues and consume a large amount of resources, such as computing resources. In this case, the first response of senior database administrators (DBAs) is to implement SQL throttling instead of capacity increases as the emergency solution.
When the system detects that instance resources are insufficient, DAS needs to identify the root causes of the complex issues and make informed decisions based on the root causes, such as throttling and capacity increases.
When are the capacity increases performed?
Determine appropriate points in time and methods of the capacity increases:
The accuracy of the decision on the points in time for performing the capacity increases as emergency solutions is closely related to the evaluation of the emergencies. If emergency alerts are reported at an excessively high frequency, instances are frequently scaled out to use high specifications. This causes unnecessary costs. If emergency alerts are reported at a later time, the impact of the emergencies on your business last for a longer period. This may even cause business failures. In real-time monitoring scenarios, extreme difficulties exist when you predict whether an error that abruptly occurs persists at the next moment. Therefore, making a decision on whether to report emergency alerts is a challenge.
In most cases, you can use two methods to increase capacities: scale-out and scale-up. In a scale-out, read-only nodes are added for horizontal scaling. In a scale-up, instance specifications are upgraded for vertical scaling.
Scale-outs are applicable to scenarios in which the amount of read traffic is relatively large and the amount of the write traffic is relatively small. However, data migration is required to create read-only nodes for traditional databases. During the data migration, new data is generated on the primary nodes. The generated incremental data must be synchronized to the read-only nodes. Therefore, a large amount of time is required to create new nodes.
In scale-ups, existing specifications are upgraded. The upgrades follow a general process. In the general process, a secondary database is upgraded first and then a switchover is performed between a primary database and a secondary database. Then, the specifications of the new secondary database are upgraded. This process reduces the impact on the business. However, after the secondary database is upgraded and serves as the primary database, issues of data synchronization and data latency still exist.
Therefore, you must determine the method of performing capacity increases based on the existing conditions and the traffic of the current instance.
Which methods are used to perform the capacity increases? How do I choose specifications?
When databases are used, each time instance specifications are changed, various management and O&M operations are involved. For example, you want to change the specifications of a database that is deployed on a physical machine. In most cases, each time the database specifications are changed, a wide range of operations are involved. These operations include data file migration, control group (cgroup) isolation and reallocation, switchovers among traffic proxy nodes, and switchovers between primary and secondary nodes. The process of changing the specifications of a Docker-based database is more complex. This is because additional microservices-related operations must be performed, such as generating Docker images, selecting Elastic Compute Service (ECS) instances, and managing available specifications. Therefore, if you use appropriate specifications, the number of specification changes can be reduced in an effective way. This saves time for your business.
After the CPU utilization reaches 100% and you upgrade the specifications, you may encounter two scenarios. In one scenario, the loads of your computing resources decrease and your business traffic is stable. In the other scenario, the CPU utilization is still 100% and the traffic increases due to the enhanced computing capabilities. The results in the first scenario are optimal and expected. However, the results in the second scenario are also common. In the second scenario, after the upgrade, the new specifications still cannot meet the requirements of your business traffic capacities. Therefore, the resources are still insufficient and your business is still affected.
The decision-making on how to choose appropriate high specifications based on the database operating information affects the results of capacity increases.
Solutions
DAS Auto Scaling can help you handle the preceding three technical challenges. The following sections describe DAS Auto Scaling from the following three aspects: service capabilities, solutions, and core technologies. Multiple types of databases are involved, such as ApsaraDB RDS for MySQL, PolarDB for MySQL, and ApsaraDB for Redis. The features such as automatic storage expansion, auto scaling for specifications, and automatic bandwidth adjustment are also involved. A use case is provided at the end of this topic for further explanations.
Service capabilities
The automatic storage expansion feature can perform a pre-upgrade to increase the disk space for your instance that is about to reach the upper limit for the current specifications. This prevents your business from being affected by the fully occupied database disk space. In this feature, you can configure the threshold ratio for storage expansion. You can also use the default upper threshold that is provided by DAS, which is 90%. After the threshold is exceeded, DAS increases the disk capacities for the instance.
DAS provides the auto scaling feature for specifications to automatically change the specifications of database instances. This feature can adjust your computing resources so that an appropriate amount of computing resources can be used to process application requests in your business loads. In this feature, you can configure the abruptness level, the duration of your business traffic loads, and the maximum specifications. You can also specify whether to roll back to the original specifications after the specifications are changed.
DAS provides the automatic bandwidth adjustment feature to automatically change the bandwidth of database instances. This feature can adjust the bandwidth to an appropriate specification. This way, the issue of insufficient bandwidth is resolved.
In terms of user interaction, DAS Auto Scaling uses notifications to display the progress and the status information about your tasks. The notifications are divided into three types: specification recommendations, task status, and events that are triggered by exceptions. The notifications for events triggered by exceptions inform you that tasks of changing specifications are triggered. The notifications for specification recommendations describe the original specifications and the expected specifications for storage expansion and specification changes. The notifications for task status provide the progress and status information about Auto Scaling tasks.
Solutions
The following figure shows the steps of implementing a closed-loop procedure for using DAS Auto Scaling to provide the preceding capabilities.
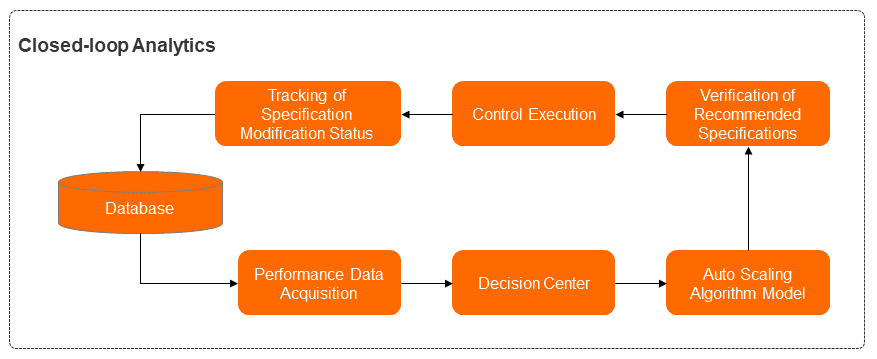
The closed-loop procedure involves the modules for performance data collection, decision-making center, algorithm model, specification recommendation and verification, management, and status tracking. Each of these modules provides the following features:
The module for performance data collection collects real-time performance data of instances. The performance data includes various performance metrics, specification configurations, and session information about operating database instances.
The decision-making center module makes global decisions based on the current performance data, the session list of instances, and other data to handle the first challenge. For example, if the current computing resources are insufficient and SQL throttling can resolve this issue, this module determines that SQL throttling is enabled. If business traffic spikes occur, this module determines that the auto scaling process continues.
The algorithm model module is the core module of the DAS Auto Scaling feature. This module implements computing so that DAS can perform anomaly detection on business loads and provide recommendations about capacity specifications for database instances. This helps you handle the second and third challenges.
The specification recommendation and verification module provides specific recommendations about specifications and checks whether the recommended specifications are suitable for the deployment types and actual operating environments of database instances. This module also performs another verification to check whether the recommended specifications are included in the available specifications that are provided for the current region. This ensures that the recommendations can be implemented by the management module.
The management module distributes and implements the provided specification recommendations.
The status tracking module measures and tracks performance changes that occur on database instances before and after the specifications are changed.
The following section describes the business scenarios of the following three features that are supported by DAS Auto Scaling: automatic storage expansion, auto scaling for specifications, and automatic bandwidth adjustment.
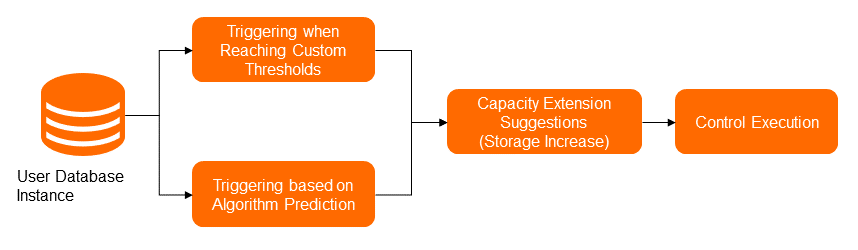
The following figure shows the storage expansion solution. Storage expansion is triggered in two ways: user-defined threshold and algorithm-based forecasting. Based on time-series forecasting algorithms and the used disk space of database instances in a past period, the algorithm predicts the disk space to be used in a subsequent period. If the used disk space exceeds the disk specifications of the instances in a short period, automatic storage expansion is triggered. Each time storage expansion is performed, the disk space must be increased by at least 5 GB and at most 15%. This ensures that the disk space of the database instances is sufficient.
The points in time at which the auto scaling feature is implemented on disks are determined by the specified thresholds and forecasting results. If the disk utilization slowly increases to the specified threshold, such as 90%, storage expansion is triggered. If the disk utilization rapidly increases and the algorithm forecasts that space insufficiency will occur in a short period, Auto Scaling also provides recommendations about disk storage expansion and the corresponding reasons.
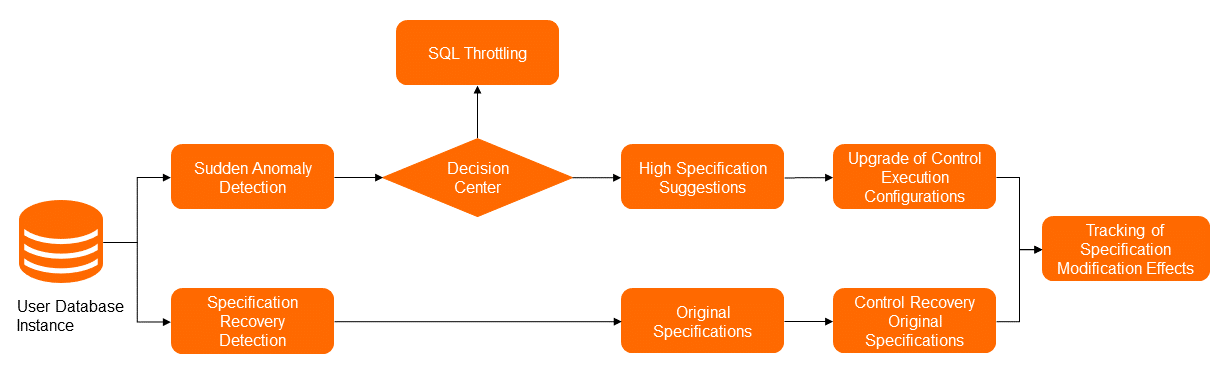
The following figure shows the solution for auto scaling for specifications. In the process of changing specifications, the anomaly detection module identifies traffic exceptions that are caused by business traffic spikes from multiple dimensions. These dimensions include multiple performance metrics, such as queries per second (QPS), transactions per second (TPS), active sessions, and IOPS. Then, the decision-making center determines whether to implement the auto scaling feature to change the specifications. If the auto scaling feature is to be implemented, the specification recommendation module provides high-specification recommendations. Then, the management module changes the specifications.
After the traffic exceptions end, the anomaly detection module identifies that the traffic returns to the normal state. Then, the management module downgrades the specifications based on the original specification information that is stored in the metadata. After the entire process of changing specifications is complete, the status tracking module provides the performance change trends during the process and evaluates the results.
To determine the appropriate points in time for triggering the auto scaling feature for specifications, DAS performs anomaly detection on various performance metrics of instances, such as CPU utilization, disk IOPS, and instance logic reads. Then, the system triggers the auto scaling feature for specifications in an effective way to change specifications based on the duration that is covered by the specified observation window. After the auto scaling feature for specifications is triggered, the module of the specification recommendation algorithm implements computing based on the trained model, current performance data, current specifications, and previous performance data. This way, the module provides the instance specifications that are suitable for the current traffic. In addition, to determine the points in time for triggering the rollback to original specifications, DAS also considers the duration of the observation window in a quiescent period and the instance performance data. After the condition for rolling back to the original specifications is met, the rollback is performed.
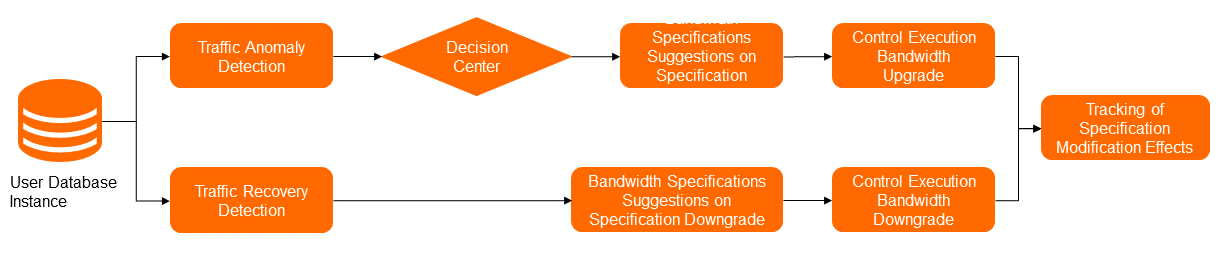
The following figure shows the solution for automatic bandwidth adjustment. In the process of changing the bandwidth, the anomaly detection module detects traffic exceptions based on the outbound and inbound traffic usage. Then, the decision-making center determines whether to implement the automatic bandwidth adjustment feature to upgrade the bandwidth. If the feature is to be implemented, the specification recommendation module provides high-specification recommendations. Then, the management module upgrades the bandwidth.
After the traffic exceptions end, the anomaly detection module identifies that the traffic returns to the normal state. Then, the management module downgrades the bandwidth based on the original specification information that is stored in the metadata. After the entire process of changing the bandwidth is complete, the status tracking module provides the performance change trends during the process and evaluates the results.
To determine the appropriate points in time for triggering the automatic bandwidth adjustment feature, DAS performs anomaly detection of the outbound and inbound traffic of the instance. Then, the system triggers the automatic bandwidth adjustment feature to upgrade the bandwidth based on the duration that is covered by the specified observation window. After the automatic bandwidth adjustment feature is triggered, the module of the specification recommendation algorithm implements computing based on the trained model, current performance data, current bandwidth specifications, and previous performance data. This way, the module provides the bandwidth specifications that are suitable for the current traffic. In addition, to determine the points in time for triggering the rollback to original bandwidth specifications, DAS also considers the instance performance data. After the condition for rolling back to the original bandwidth specifications is met, the rollback is performed.
Core technologies
DAS Auto Scaling relies on the comprehensive technologies that are developed by the Alibaba Cloud database data channel team, management team, and kernel team. This feature relies on the following key technologies:
Data monitoring of network-wide database instances with a latency of several seconds. Data monitoring and collection channels implement data collection, monitoring, display, and diagnosis for database instances across the entire network within seconds. More than 10 million monitoring metrics can be processed per second in real time. This lays a solid data foundation for intelligent database services.
Unified management task flows about instances across the entire network. Management task flows perform O&M operations on the instances across the entire Alibaba Cloud network. This ensures that Auto Scaling technologies are implemented as expected.
Time-series algorithm for anomaly detection based on forecasting and machine learning. The time-series algorithm for anomaly detection provides a wide range of features, such as performing periodic detection, determining turning points, and identifying continuous intervals of exceptions. You can use this algorithm to forecast the data of more than 700,000 online database instances. When the algorithm is used to forecast data for the next day, the number of instances for which the result error is less than 5% accounts for more than 99%. When data is forecast for the period that occurs 14 days later, the number of instances for which the result error is less than 5% accounts for more than 94%.
Forecasting model of database response time (RT) based on deep learning. This algorithm forecasts the RT of running instances based on various performance metrics of database instances, such as CPU utilization, logical reads, physical reads, and IOPS. The forecasting results are used for reference when the databases reduce the BufferPool memory. This saves a memory of 27 TB for Alibaba databases. The 27 TB memory space accounts for about 17% of the total memory.
Next generation PolarDB for MySQL based on the cloud computing architecture. PolarDB for MySQL is a relational database that is provided by the Alibaba Cloud database team for the cloud computing era. In this database, compute nodes are separated from storage nodes. This feature provides powerful technical support for Auto Scaling. This prevents additional overheads that are caused by data replication and storage and significantly improves user experience.
Supported by the preceding technologies, DAS Auto Scaling provides different features based on different engines. DAS Auto Scaling also ensures data consistency and integrity during auto scaling and implements the feature without affecting business stability. This way, your business is protected. The following table describes the supported features for different database engines.
Feature
Supported database engine
Auto scaling for specifications
ApsaraDB RDS for MySQL High-availability Edition that uses standard SSDs or enhanced SSDs (ESSDs), general-purpose ApsaraDB RDS for MySQL High-availability Edition that uses local disks, and general-purpose ApsaraDB RDS for MySQL Enterprise Edition
PolarDB for MySQL Cluster Edition
ApsaraDB for Redis Community Edition and memory-optimized ApsaraDB for Redis Enhanced Edition (Tair)
Automatic storage expansion
ApsaraDB RDS for MySQL High-availability Edition that uses standard SSDs or ESSDs and ApsaraDB RDS for MySQL Cluster Edition
ApsaraDB RDS for PostgreSQL High-availability Edition that uses standard SSDs or ESSDs
ApsaraDB MyBase for MySQL High-availability Edition that uses standard SSDs or ESSDs and ApsaraDB MyBase for MySQL High-availability Edition that uses local disks
Automatic bandwidth adjustment
ApsaraDB for Redis that uses local disks
Use case
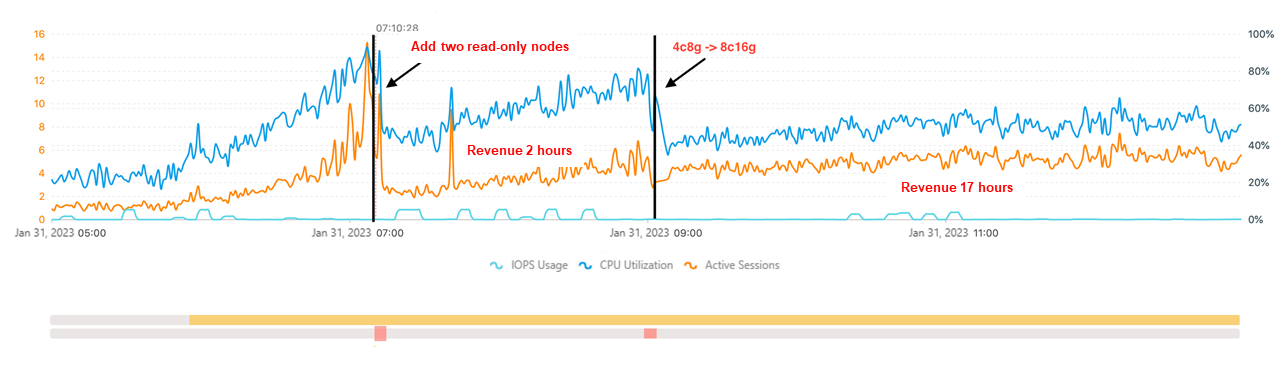
The following example demonstrates how to use the Auto Scaling feature. An Apsara RDS for MySQL instance is used in this example. In this example, an observation window whose duration is 15 minutes is configured. The CPU utilization threshold is set to 80%.
In the preceding figure, the CPU utilization and the number of active sessions surge because of traffic exceptions at 07:10. The CPU utilization reaches 80%, which indicates that the resources are relatively insufficient. The analysis of the read and write traffic of the instance shows that the current traffic is mainly used to read data. The algorithm of DAS Auto Scaling determines that the CPU utilization can be reduced to 60% by adding two read-only nodes. After implementation, the resource insufficiency issue is solved. However, the CPU utilization surges again due to the increase in business at 09:00. In this case, the resources are relatively insufficient again. The analysis shows that the current traffic is mainly used to write data. The algorithm of DAS Auto Scaling determines that the CPU utilization can be reduced to 50% by upgrading the specifications of the computing resources. After implementation, the resource insufficiency issue is solved again.
The preceding example shows that DAS Auto Scaling can proactively troubleshoot the issue of resource insufficiency and effectively ensure the stability of the database business.