This topic describes the SharedMergeTree table engine family in ApsaraDB for ClickHouse Enterprise Edition.
Overview
The SharedMergeTree table engine family is available only in ApsaraDB for ClickHouse Enterprise Edition.
The SharedMergeTree table engine family is a cloud-native replacement of the ReplicatedMergeTree engines and works on top of Object Storage Service (OSS). Each specific MergeTree engine type has an alternative to a SharedMergeTree engine type. For example, ReplacingSharedMergeTree replaces ReplacingReplicatedMergeTree.
The SharedMergeTree table engine family improves the performance of ApsaraDB for ClickHouse Enterprise Edition. You do not need to make any changes for using the SharedMergeTree table engine family instead of the ReplicatedMergeTree-based engines. The SharedMergeTree table engine family has the following benefits:
Higher insert throughput
Improved throughput of background merges
Improved throughput of mutations
Faster scaling operations
More lightweight strong data consistency for SELECT queries
Compared with ReplicatedMergeTree, SharedMergeTree provides a deeper separation of compute and storage, which is a significant improvement. The following figure shows how ReplicatedMergeTree separates compute and storage: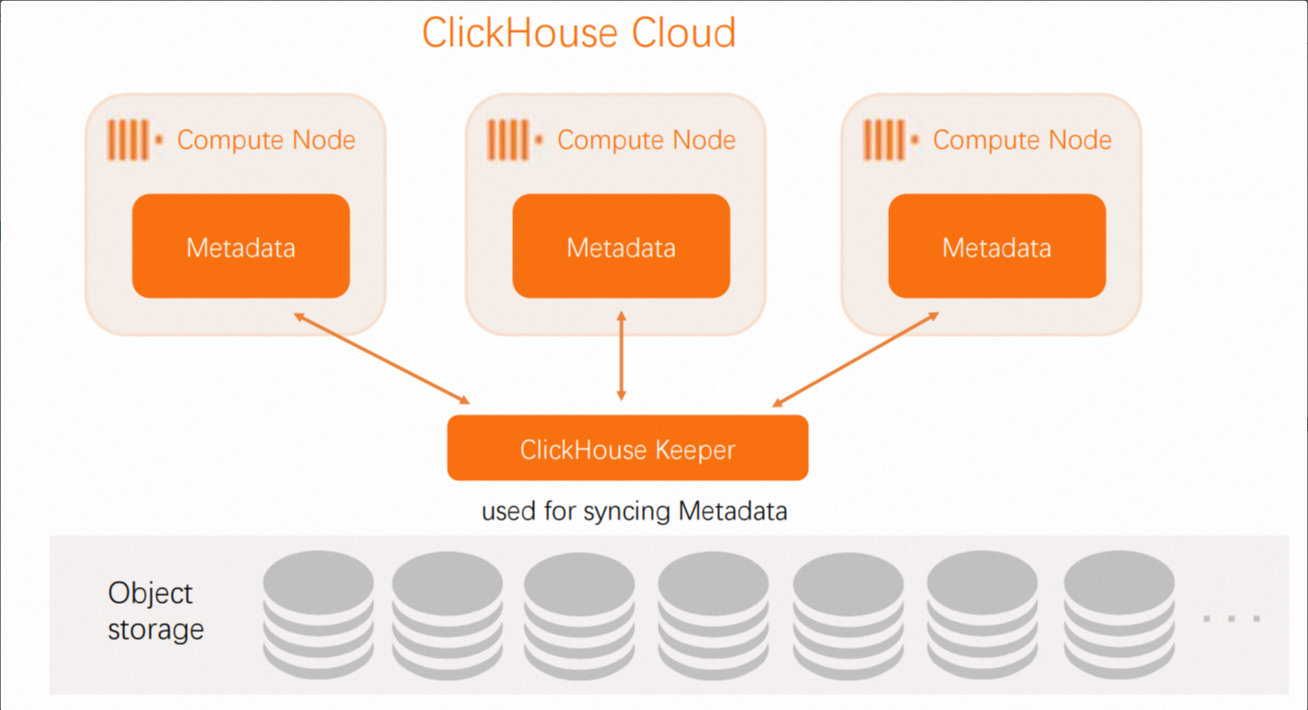
The preceding figure shows that the data stored in ReplicatedMergeTree is in object storage. However, the metadata still resides on each ClickHouse server. This indicates that the metadata needs to be replicated on all replicas for every replication.
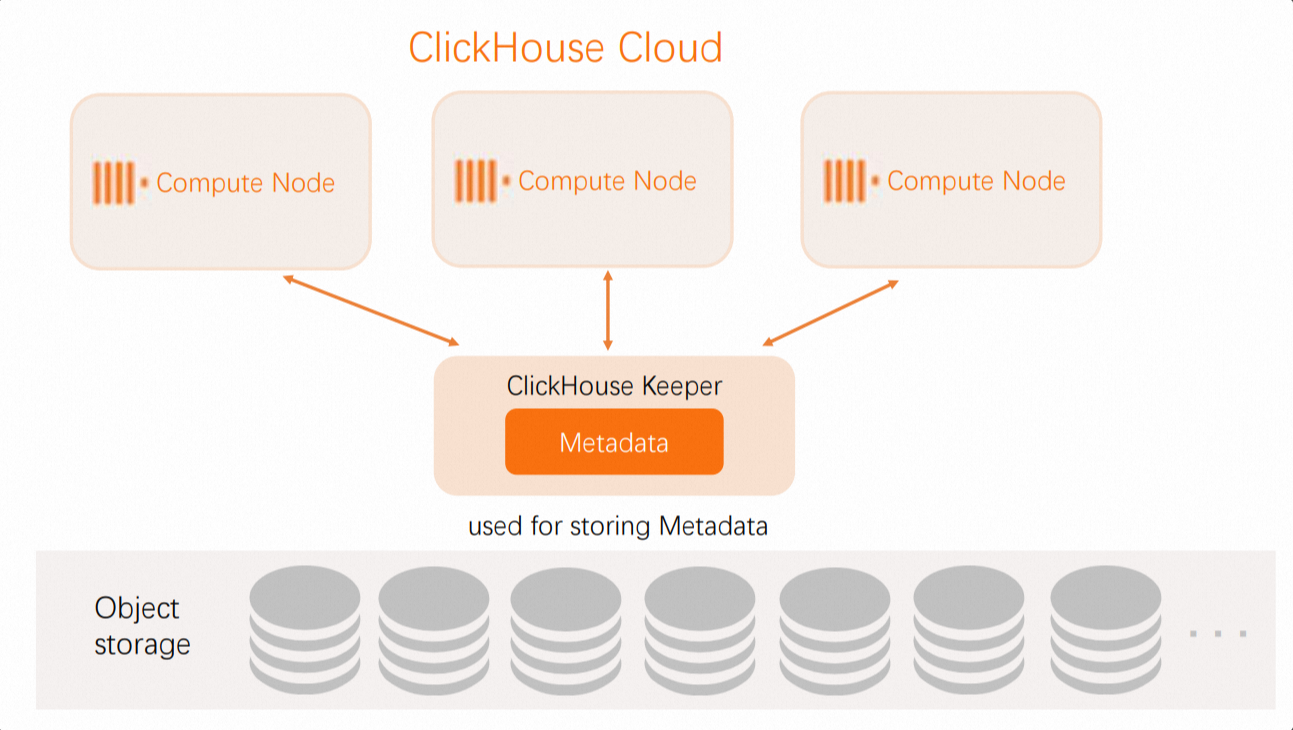 Unlike ReplicatedMergeTree, SharedMergeTree does not require replicas to communicate with each other. Instead, all communication happens by using the shared storage and ClickHouse Keeper. SharedMergeTree implements asynchronous leaderless replication and uses ClickHouse Keeper for coordination and metadata storage. This indicates that metadata does not need to be replicated as your service scales out. This leads to faster replication, modification, merging and scale-out operations. SharedMergeTree allows each table to have hundreds of replicas. This implements dynamic scale-outs without shards. This also indicates that a distributed query execution approach can be used in ApsaraDB for ClickHouse Enterprise Edition to utilize more computing resources for a query.
Unlike ReplicatedMergeTree, SharedMergeTree does not require replicas to communicate with each other. Instead, all communication happens by using the shared storage and ClickHouse Keeper. SharedMergeTree implements asynchronous leaderless replication and uses ClickHouse Keeper for coordination and metadata storage. This indicates that metadata does not need to be replicated as your service scales out. This leads to faster replication, modification, merging and scale-out operations. SharedMergeTree allows each table to have hundreds of replicas. This implements dynamic scale-outs without shards. This also indicates that a distributed query execution approach can be used in ApsaraDB for ClickHouse Enterprise Edition to utilize more computing resources for a query.
System monitoring
Most of the system tables of ReplicatedMergeTree used for system monitoring exist in SharedMergeTree, except for system.replication_queue and system.replicated_fetches. This is because the replication of data and metadata does not occur. However, SharedMergeTree has corresponding alternatives for the two tables.
system.virtual_parts: This table serves as an alternative of SharedMergeTree to
system.replication_queue. The table stores information about the most recent set of current data parts and future data parts in progress such as merges, modifications, and partition deletions.system.shared_merge_tree_fetches: This table serves as an alternative of SharedMergeTree to system.replicated_fetches. The table contains information about the primary keys and checksums that are being loaded into the memory.
Use SharedMergeTree
The SharedMergeTree-based table engines are the default table engines in ApsaraDB for ClickHouse Enterprise Edition. For clusters that support the SharedMergeTree table engine family, you do not need to make any additional changes. You can create a table the same way as you did before and a SharedMergeTree-based table engine is automatically used. The engine corresponds to the engine specified in your CREATE TABLE statement.
You can create a table named
my_tableby using the SharedMergeTree table engine.CREATE TABLE my_table( key UInt64, value String ) ENGINE = MergeTree ORDER BY keyYou do not need to set the value of
ENGINEto MergeTree because the value ofdefault_table_engineis MergeTree in ApsaraDB for ClickHouse Enterprise Edition. The following query is identical to the preceding query:CREATE TABLE my_table( key UInt64, value String ) ORDER BY keyIf you use the ReplacingMergeTree, CollapsingMergeTree, AggregatingMergeTree, SummingMergeTree, VersionedCollapsingMergeTree, and GraphiteMergeTree table engines, they will be automatically converted into the corresponding SharedMergeTree-based table engine.
CREATE TABLE myFirstReplacingMT ( `key` Int64, `someCol` String, `eventTime` DateTime ) ENGINE = ReplacingMergeTree ORDER BY key;You can execute the SHOW CREATE TABLE statement to query the corresponding CREATE TABLE statement.
SHOW CREATE TABLE myFirstReplacingMT;CREATE TABLE default.myFirstReplacingMT ( `key` Int64, `someCol` String, `eventTime` DateTime ) ENGINE = SharedReplacingMergeTree('/clickhouse/tables/{uuid}/{shard}', '{replica}') ORDER BY key SETTINGS index_granularity = 8192
Engine configurations
You need to pay attention to the following engine configuration changes:
insert_quorum: All inserts to SharedMergeTree are quorum inserts (data written to the shared storage). Therefore, this parameter is not required if a SharedMergeTree-based table engine is used.insert_quorum_parallel: All inserts to SharedMergeTree are quorum inserts (data written to the shared storage).select_sequential_consistency: Quorum inserts are not required. Additional requests are sent to ClickHouse Keeper in SELECT queries.