Distributed systems are complex, which brings risks to the stability of infrastructure, application logic, and O&M. This may lead to failures in business systems. Therefore, it is important to build distributed systems with fault tolerance capabilities. This topic describes how to use Service Mesh (ASM) to configure the timeout processing, retry, bulkhead, and circuit breaking mechanisms to build distributed systems with fault tolerance capabilities.
Background information
Fault tolerance refers to the ability of a system to continue running during partial failures. To create a reliable and resilient system, you must make sure that all services in the system are fault-tolerant. The dynamic nature of the cloud environment requires services to proactively anticipate failures and gracefully respond to unexpected incidents.
Each service may have failed service requests. Appropriate measures must be prepared to handle the failed service requests. The interruption of a specific service may cause knock-on effects and lead to serious consequences for your business. Therefore, it is necessary to build, test, and use the resiliency of the system. ASM provides a fault tolerance solution that supports the timeout processing, retry, bulkhead, and circuit breaking mechanisms. The solution brings fault tolerance to applications without modifying the code of the applications.
Timeout processing
How it works
When a client sends a request to an upstream service, the upstream service may not respond. You can set a timeout period. If the upstream service does not respond to the request within the timeout period, the client considers the request a failure and no longer waits for a response from the upstream service.
After a timeout period is set, an application receives a return error if the backend service does not respond within the timeout period. Then, the application can take appropriate fallback actions. The timeout setting specifies the time that the requesting client waits for a service to respond to the request. The timeout setting does not affect the processing behavior of the service. Therefore, a timeout does not mean that the requested operation fails.
Solution
ASM allows you to configure a timeout policy for a route in a virtual service to set a timeout period. If a sidecar proxy does not receive a response within the timeout period, the request fails. After you set the timeout period for a route, the timeout setting applies to all requests that use the route.
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: httpbin
spec:
hosts:
- 'httpbin'
http:
- route:
- destination:
host: httpbin
timeout: 5stimeout: specifies the timeout period. If the requested service does not respond within the specified timeout period, an error is returned, and the requesting client no longer waits for a response.
Retry mechanism
How it works
If a service encounters a request failure, such as request timeout, connection timeout, or service breakdown, you can configure a retry mechanism to request the service again.
Do not retry frequently or for a long time. Otherwise, cascading failures may occur.
Solution
ASM allows you to create a virtual service to define a retry policy for HTTP requests. In this example, a virtual service is created to define the following retry policy: When a service in an ASM instance requests the httpbin application, the service requests the httpbin application again for a maximum of three times if the httpbin application does not respond or the service fails to establish a connection to the httpbin application. The timeout period for each request is 5 seconds.
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: httpbin
spec:
hosts:
- 'httpbin'
http:
- route:
- destination:
host: httpbin
retries:
attempts: 3
perTryTimeout: 5s
retryOn: connect-failure,resetYou can configure the following fields in the retries structure to customize the retry behavior of the sidecar proxy for requests.
Field | Description |
attempts | Specifies the maximum number of retries for a request. If both a retry mechanism and a timeout period for a service route are configured, the actual number of retries depends on the timeout period. For example, if a request does not reach the maximum number of retries but the total time spent on all retries exceeds the timeout period, the sidecar proxy stops retrying the request and returns a timeout response. |
perTryTimeout | Specifies the timeout period for each retry. Unit: milliseconds, seconds, minutes, or hours. |
retryOn | Specifies the conditions under which retries are performed. Separate multiple retry conditions with commas (,). For more information, see common retry conditions for HTTP requests and common retry conditions for gRPC requests. |
The following table provides common retry conditions for HTTP requests.
Retry condition | Description |
connect-failure | A retry is performed if a request fails because the connection to the upstream service fails (such as connection timeout). |
refused-stream | A retry is performed if the upstream service returns a REFUSED_STREAM frame to reset the stream. |
reset | A retry is performed if a disconnection, reset, or read timeout event occurs before the upstream service responds. |
5xx | A retry is performed if the upstream service returns a 5XX response code, such as 500 or 503, or the upstream service does not respond. Note The 5xx retry conditions include the retry conditions of connect-failure and refused-stream. |
gateway-error | A retry is performed if the upstream service returns a 502, 503, or 504 status code. |
envoy-ratelimited | A retry is performed if the x-envoy-ratelimited header is present in a request. |
retriable-4xx | A retry is performed if the upstream service returns a 409 status code. |
retriable-status-codes | A retry is performed if the status code returned by the upstream service indicates that retries are allowed. Note You can add valid status codes to the retryOn field to indicate that retries are allowed, such as |
retriable-headers | A retry is performed if the response headers returned by the upstream service contain a header that indicates retries are allowed. Note You can add |
gRPC uses HTTP/2 as its transfer protocol. Therefore, you can set the retry conditions of gRPC requests in the retryOn field of the retry policy for HTTP requests. The following table provides common retry conditions for gRPC requests.
Retry condition | Description |
cancelled | A retry is performed if the gRPC status code in the response header of the upstream gRPC service is cancelled (1). |
unavailable | A retry is performed if the gRPC status code in the response header of the upstream gRPC service is unavailable (14). |
deadline-exceeded | A retry is performed if the gRPC status code in the response header of the upstream gRPC service is deadline-exceeded (4). |
internal | A retry is performed if the gRPC status code in the response header of the upstream gRPC service is internal (13). |
resource-exhausted | A retry is performed if the gRPC status code in the response header of the upstream gRPC service is resource-exhausted (8). |
Configure the default retry policy for HTTP requests
By default, services in ASM adopt a default retry policy for HTTP requests when they access other HTTP services, even if no retry policy is defined for HTTP requests by using a virtual service. The number of retries in this default retry policy is two, and no timeout period is set for a retry. The default retry conditions are connect-failure, refused-stream, unavailable, cancelled, and retriable-status-codes. You can configure the default retry policy for HTTP requests on the Basic Information page in the ASM console. After the configuration, the new default retry policy overrides the original default retry policy.
This feature is available only for ASM instances whose versions are 1.15.3.120 or later. For more information about how to update an ASM instance, see update an ASM instance.
Log on to the ASM console. In the left-side navigation pane, choose .
On the Mesh Management page, click the name of the ASM instance. In the left-side navigation pane, choose .
In the Config Info section of the Base Information page, click Edit next to Default HTTP retry policy.
In the Default HTTP retry policy dialog box, configure the related parameters, and click OK.
Parameter
Description
Retries
Corresponds to the attempts field described previously. In the default retry policy for HTTP requests, this field can be set to 0, which indicates that HTTP request retries are disabled by default.
Timeout
Corresponds to the perTryTimeout field described previously.
Retry On
Corresponds to the retryOn field described previously.
Bulkhead pattern
How it works
A bulkhead pattern limits the maximum number of connections and the maximum number of access requests that a client can initiate to a service to avoid excessive access to the service. If a specified threshold is exceeded, new requests are disconnected. A bulkhead pattern helps isolate resources that are used in services and prevent cascading system failures. The maximum number of concurrent connections and the timeout period for each connection are common connection settings that are valid for both TCP and HTTP. The maximum number of requests per connection and the maximum number of request retries are valid only for HTTP1.1, HTTP2, and Google Remote Procedure Call (gRPC) connections.
Solution
ASM allows you to create a destination rule to configure a bulkhead pattern. In this example, a destination rule is created to define the following bulkhead pattern: When a service requests the httpbin application, the maximum number of concurrent connections is 1, the maximum number of requests per connection is 1, and the maximum number of request retries is 1. In addition, the service receives a 503 error if no connection to the httpbin application is established within 10 seconds.
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: httpbin
spec:
host: httpbin
trafficPolicy:
connectionPool:
http:
http1MaxPendingRequests: 1
maxRequestsPerConnection: 1
tcp:
connectTimeout: 10s
maxConnections: 1http1MaxPendingRequests: specifies the maximum number of request retries.
maxRequestsPerConnection: specifies the maximum number of requests per connection.
connectTimeout: specifies the timeout period for each connection.
maxConnections: specifies the maximum number of concurrent connections.
Circuit breaking
How it works
The circuit breaking mechanism works in the following way: If Service B does not respond to a request from Service A, Service A stops sending new requests but checks the number of consecutive errors that occur within a specified period of time. If the number of consecutive errors exceeds the specified threshold, the circuit breaker disconnects the current request. All subsequent requests fail until the circuit breaker is closed.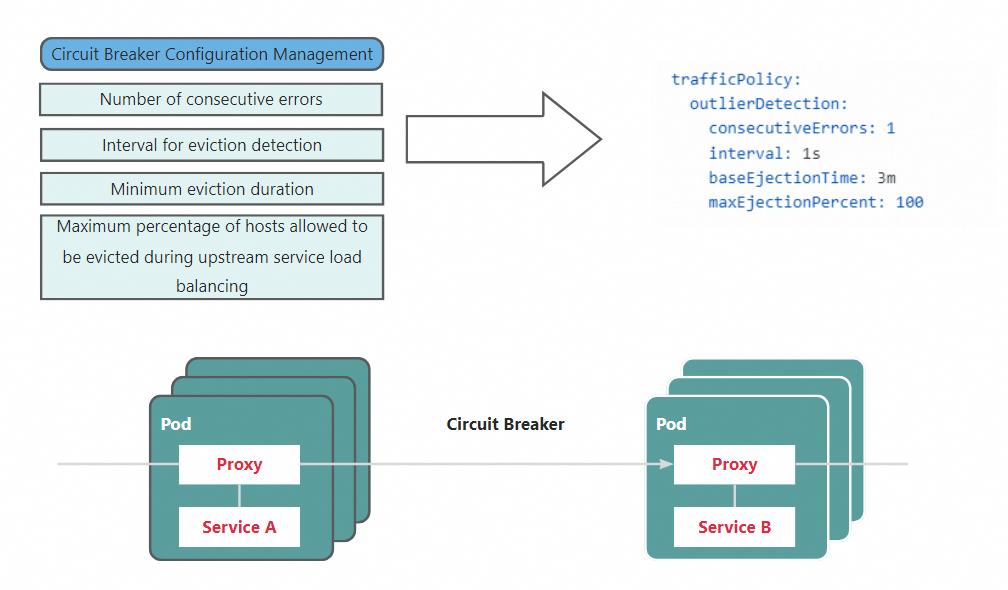
Solution
ASM allows you to create a destination rule to configure a host-level circuit breaking mechanism. In this example, a destination rule is created to define the following circuit breaking mechanism: If a service fails to request the httpbin application for three consecutive times within 5 seconds, requests from this service to the same host of the httpbin application are not allowed in 5 minutes.
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: httpbin
spec:
host: httpbin
trafficPolicy:
outlierDetection:
consecutiveErrors: 3
interval: 5s
baseEjectionTime: 5m
maxEjectionPercent: 100consecutiveErrors: specifies the number of consecutive errors.
interval: specifies the time interval for ejection detection.
baseEjectionTime: specifies the minimum ejection duration.
maxEjectionPercent: specifies the maximum percentage of hosts that can be ejected from a load balancing pool.
View metrics related to host-level circuit breaking
In a host-level circuit breaking scenario, the sidecar proxy of a client detects the error rate of each host of an upstream service separately and ejects a host from the load balancing pool of the service if the host encounters consecutive errors. This host-level circuit breaking mechanism is different from the circuit breaking mechanism defined by using ASMCircuitBreaker fields.
Host-level circuit breaking can generate a series of relevant metrics. This helps you determine whether circuit breaking occurs. The following table describes some relevant metrics.
Metric | Type | Description |
envoy_cluster_outlier_detection_ejections_active | Gauge | The number of hosts that are ejected |
envoy_cluster_outlier_detection_ejections_enforced_total | Counter | The number of times that host ejection occurs |
envoy_cluster_outlier_detection_ejections_overflow | Counter | The number of times that host ejection was abandoned because the maximum ejection percentage was reached |
ejections_detected_consecutive_5xx | Counter | The number of consecutive 5xx errors detected on a host |
You can configure proxyStatsMatcher of a sidecar proxy to enable the sidecar proxy to report metrics related to circuit breaking. After the configuration, you can use Prometheus to collect and view metrics related to circuit breaking.
You can use proxyStatsMatcher to configure a sidecar proxy to report metrics related to circuit breaking. After you select proxyStatsMatcher, select Regular Expression Match and set the value to
.*outlier_detection.*. For more information, see the proxyStatsMatcher section in Configure sidecar proxies.Redeploy the Deployment for the httpbin application. For more information, see the "(Optional) Redeploy workloads" section in Configure sidecar proxies.
Configure metric collection and alerts for host-level circuit breaking
After you configure metrics related to host-level circuit breaking, you can configure a Prometheus instance to collect the metrics. You can also configure alert rules based on key metrics. This way, alerts are generated when circuit breaking occurs. The following section describes how to configure metric collection and alerts for host-level circuit breaking. In this example, Managed Service for Prometheus is used.
In Managed Service for Prometheus, connect the ACK cluster on the data plane to the Alibaba Cloud ASM component or upgrade the Alibaba Cloud ASM component to the latest version. This ensures that the circuit breaking metrics can be collected by Managed Service for Prometheus. For more information about how to integrate components into ARMS, see Manage components. (If you have integrated a self-managed Prometheus instance to collect metrics of the ASM instance by referring to Monitor ASM instances by using a self-managed Prometheus instance, you do not need to perform this step.)
Create an alert rule for host-level circuit breaking. For more information, see Use a custom PromQL statement to create an alert rule. The following table describes how to specify key parameters for configuring an alert rule. For more information about other parameters, see the preceding documentation.
Parameter
Example
Description
Custom PromQL Statements
(sum (envoy_cluster_outlier_detection_ejections_active) by (cluster_name, namespace)) > 0
In the example, the envoy_cluster_outlier_detection_ejections_active metric is queried to determine whether a host is being ejected in the current cluster. The query results are grouped by the namespace where the service resides and the service name.
Alert Message
Host-level circuit breaking is triggered. Some workloads encounter errors repeatedly and the hosts are ejected from the load balancing pool. Namespace: {$labels.namespace}}, Service where the host ejection occurs: {{$labels.cluster_name}}. Number of hosts that are ejected: {{ $value }}
The alert information in the example shows the namespace of the service that triggers the circuit breaking, the service name, and the number of hosts that are ejected.