When you need to run multiple machine learning models to perform inference, you can use Model Service Mesh (ModelMesh) to roll out and manage a multi-model inference service. ModelMesh is implemented based on KServe ModelMesh and optimized for high-scale, high-density, and frequently-changing model use cases. ModelMesh intelligently loads and unloads models to and from memory to strike a balance between responsiveness and computing. This simplifies the deployment and O&M of a multi-model inference service and improves inference efficiency and performance.
Prerequisites
A Container Service for Kubernetes (ACK) cluster is added to your Service Mesh (ASM) instance and your ASM instance is of version 1.18.0.134 or later.
An ingress gateway is created for the cluster. For more information, see Create an ingress gateway.
In this example, an ASM ingress gateway is used as the gateway of the cluster. The default gateway name is ingressgateway, port 8008 is enabled, and the HTTP protocol is used.
Features
ModelMesh provides the following features.
Feature | Description |
Cache management |
|
Intelligent placement and loading |
|
Resiliency | Failed model loads are automatically retried in different pods. |
Operational simplicity | Rolling model updates are handled automatically and seamlessly. |
Step 1: Enable the ModelMesh feature in ASM
Log on to the ASM console. In the left-side navigation pane, choose Service Mesh > Mesh Management.
On the Mesh Management page, click the name of the ASM instance. In the left-side navigation pane, choose Ecosystem > KServe on ASM.
On the KServe on ASM page, click Enable KServe on ASM.
NoteKServe relies on CertManager, and the installation of KServe will automatically install the CertManager component. If you want to use a self-built CertManager, disable Automatically install the CertManager component in the cluster.
After KServe is enabled, use kubectl to connect to the ACK cluster based on the information in the kubeconfig file, and then run the following command to check whether a ServingRuntime resource is available:
kubectl get servingruntimes -n modelmesh-servingExpected output:
NAME DISABLED MODELTYPE CONTAINERS AGE mlserver-1.x sklearn mlserver 1m ovms-1.x openvino_ir ovms 1m torchserve-0.x pytorch-mar torchserve 1m triton-2.x keras triton 1mA ServingRuntime resource defines the templates for pods that can serve one or more particular model formats. Pods are automatically provisioned depending on the framework of the deployed model.
The following table describes the runtimes and model formats supported by ModelMesh. For more information, see Supported Model Formats. If these model servers cannot meet all of your specific requirements, you can create custom model serving runtimes. For more information, see Use ModelMesh to create a custom model serving runtime.
ServingRuntime
Supported model framework
mlserver-1.x
sklearn, xgboost, and lightgbm
ovms-1.x
openvino_ir, onnx
torchserve-0.x
pytorch-mar
triton-2.x
tensorflow, pytorch, onnx, and tensorrt
Step 2: Configure an ASM environment
Synchronize the modelmesh-serving namespace from the ACK cluster to the ASM instance. For more information, see Synchronize automatic sidecar proxy injection labels from a Kubernetes cluster on the data plane to an ASM instance. After synchronization, confirm that the modelmesh-serving namespace exists.
Create an Istio gateway for the ingress gateway.
Create a grpc-gateway.yaml file that contains the following content:
Use kubectl to connect to the ACK cluster (or ASM instance) based on the information in the kubeconfig file, and then run the following command to create an Istio gateway:
kubectl apply -f grpc-gateway.yaml
Create a virtual service.
Create a vs-modelmesh-serving-service.yaml file that contains the following content:
Use kubectl to connect to the ACK cluster (or ASM instance) based on the information in the kubeconfig file, and then run the following command to create a virtual service:
kubectl apply -f vs-modelmesh-serving-service.yaml
Configure the Google Remote Procedure Call (gRPC)-JSON transcoder.
Create a grpcjsontranscoder-for-kservepredictv2.yaml file that contains the following content:
apiVersion: istio.alibabacloud.com/v1beta1 kind: ASMGrpcJsonTranscoder metadata: name: grpcjsontranscoder-for-kservepredictv2 namespace: istio-system spec: builtinProtoDescriptor: kserve_predict_v2 isGateway: true portNumber: 8008 workloadSelector: labels: istio: ingressgatewayUse kubectl to connect to the ACK cluster (or ASM instance) based on the information in the kubeconfig file, and then run the following command to deploy the gRPC-JSON transcoder:
kubectl apply -f grpcjsontranscoder-for-kservepredictv2.yamlCreate a grpcjsontranscoder-increasebufferlimit.yaml file that contains the following content, and set the
per_connection_buffer_limit_bytesparameter to increase the size of the response.Use kubectl to connect to the ACK cluster (or ASM instance) based on the information in the kubeconfig file, and then run the following command to deploy an Envoy filter:
kubectl apply -f grpcjsontranscoder-increasebufferlimit.yaml
Step 3: Deploy a sample model
Create a StorageClass. For more information, see Mount a dynamically provisioned NAS volume.
Log on to the ACK console. In the left-side navigation pane, click Clusters.
On the Clusters page, find the cluster that you want to manage and click its name. In the left-side pane, choose .
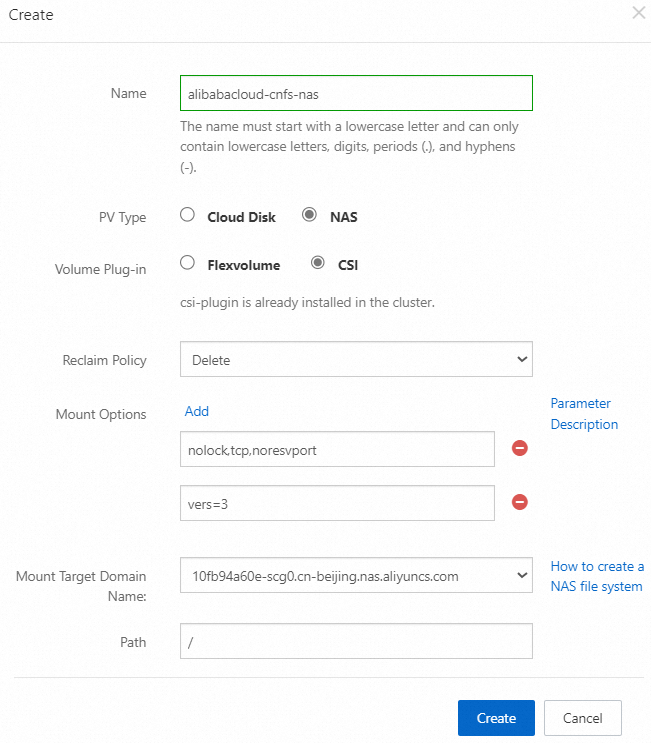
In the upper-right corner of the StorageClasses page, click Create, set the parameters shown in the following figure, and then click Create.
Create a persistent volume claim (PVC).
Create a my-models-pvc.yaml file that contains the following content:
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: my-models-pvc namespace: modelmesh-serving spec: accessModes: - ReadWriteMany resources: requests: storage: 1Gi storageClassName: alibabacloud-cnfs-nas volumeMode: FilesystemUse kubectl to connect to the ACK cluster based on the information in the kubeconfig file, and then run the following command to create a PVC:
kubectl apply -f my-models-pvc.yamlRun the following command to view the PVC in the modelmesh-serving namespace:
kubectl get pvc -n modelmesh-servingExpected output:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE my-models-pvc Bound nas-379c32e1-c0ef-43f3-8277-9eb4606b53f8 1Gi RWX alibabacloud-cnfs-nas 2h
Create a pod to access the PVC.
To use the new PVC, you must mount it as a volume to a Kubernetes pod, and then use that pod to upload the model files to a persistent volume.
Create a pvc-access.yaml file that contains the following content.
The following YAML file indicates that a pvc-access pod is created and the Kubernetes controller is required to claim the previously requested PVC by specifying
"my-models-pvc".apiVersion: v1 kind: Pod metadata: name: "pvc-access" spec: containers: - name: main image: ubuntu command: ["/bin/sh", "-ec", "sleep 10000"] volumeMounts: - name: "my-pvc" mountPath: "/mnt/models" volumes: - name: "my-pvc" persistentVolumeClaim: claimName: "my-models-pvc"Use kubectl to connect to the ACK cluster based on the information in the kubeconfig file, and then run the following command to create a pod:
kubectl apply -n modelmesh-serving -f pvc-access.yamlVerify that the pvc-access pod is running.
kubectl get pods -n modelmesh-serving | grep pvc-accessExpected output:
pvc-access 1/1 Running 0 51m
Store the model on the persistent volume.
Add the AI model to the persistent volume. In this example, the MNIST handwritten digit character recognition model trained with scikit-learn is used. A copy of the mnist-svm.joblib model file can be downloaded from the kserve/modelmesh-minio-examples repository.
Use kubectl to connect to the ACK cluster based on the information in the kubeconfig file, and then run the following command to copy the mnist-svm.joblib model file to the
/mnt/modelsfolder in the pvc-access pod:kubectl -n modelmesh-serving cp mnist-svm.joblib pvc-access:/mnt/models/Run the following command to verify that the model exists on the persistent volume:
kubectl -n modelmesh-serving exec -it pvc-access -- ls -alr /mnt/models/Expected output:
-rw-r--r-- 1 501 staff 344817 Oct 30 11:23 mnist-svm.joblib
Deploy an inference service.
Create a sklearn-mnist.yaml file that contains the following content:
Use kubectl to connect to the ACK cluster based on the information in the kubeconfig file, and then run the following command to deploy the sklearn-mnist inference service:
kubectl apply -f sklearn-mnist.yamlWait dozens of seconds (the length of waiting time depends on the image pulling speed), and then run the following command to check whether the sklearn-mnist inference service is deployed:
kubectl get isvc -n modelmesh-servingExpected output:
NAME URL READY sklearn-mnist grpc://modelmesh-serving.modelmesh-serving:8033 True
Perform an inference.
Run the
curlcommand to send an inference request to the sklearn-mnist model. The data array indicates the grayscale values of the 64 pixels in the image scan of the digit to be classified.MODEL_NAME="sklearn-mnist" ASM_GW_IP="IP address of the ingress gateway" curl -X POST -k "http://${ASM_GW_IP}:8008/v2/models/${MODEL_NAME}/infer" -d '{"inputs": [{"name": "predict", "shape": [1, 64], "datatype": "FP32", "contents": {"fp32_contents": [0.0, 0.0, 1.0, 11.0, 14.0, 15.0, 3.0, 0.0, 0.0, 1.0, 13.0, 16.0, 12.0, 16.0, 8.0, 0.0, 0.0, 8.0, 16.0, 4.0, 6.0, 16.0, 5.0, 0.0, 0.0, 5.0, 15.0, 11.0, 13.0, 14.0, 0.0, 0.0, 0.0, 0.0, 2.0, 12.0, 16.0, 13.0, 0.0, 0.0, 0.0, 0.0, 0.0, 13.0, 16.0, 16.0, 6.0, 0.0, 0.0, 0.0, 0.0, 16.0, 16.0, 16.0, 7.0, 0.0, 0.0, 0.0, 0.0, 11.0, 13.0, 12.0, 1.0, 0.0]}}]}'The following code block shows the JSON response. It can be inferred that the scanned digit is
8.{ "modelName": "sklearn-mnist__isvc-3c10c62d34", "outputs": [ { "name": "predict", "datatype": "INT64", "shape": [ "1", "1" ], "contents": { "int64Contents": [ "8" ] } } ] }
References
When you deploy multiple models that require different runtime environments, or when you need to improve model inference efficiency or control resource allocation, you can use ModelMesh to create custom model serving runtimes. The fine-tuned configurations of custom model serving runtimes ensure that each model runs in the most appropriate environment. For more information, see Use ModelMesh to create a custom model serving runtime.
When you need to process large amounts of natural language data or want to build complex language understanding systems, you can use a large language model (LLM) as an inference service. For more information, see Use an LLM as an inference service.
When you encounter pod errors, you can troubleshoot them by referring to Pod troubleshooting.