If your application encounters problems such as uneven traffic, instance failures, or slow interfaces, you can use Trace Explorer to quickly locate the faulty code. Trace Explorer also helps you with service traffic statistics and canary release monitoring. This topic describes how to use Trace Explorer in five scenarios.
Background information
The tracing technology of Application Real-Time Monitoring Service (ARMS) allows you to troubleshoot errors for a single request based on traces and use pre-aggregated trace metrics for service monitoring and alerting. In addition, the Trace Explorer feature is provided to help you analyze post-aggregated trace data. Compared with traces and pre-aggregated monitoring charts, Trace Explorer identifies issues and implements custom diagnostics in a more efficient and flexible manner.
Trace Explorer allows you to combine filter conditions and aggregation dimensions for real-time analysis based on stored full trace data. This can meet the custom diagnostics requirements in various scenarios. For example, you can view the time series charts of slow calls that take more than 3 seconds, the distribution of invalid requests on different instances, or the traffic changes of VIP customers.
Scenario 1: Uneven traffic distribution
Why does SLB route more traffic to some instances than others? What can I do to fix it?
Server Load Balancer (SLB) routes more traffic to some instances than others due to various reasons, such as invalid SLB configurations, node restarting failures caused by registry errors, and load factor errors of distributed hash tables (DHTs). Uneven traffic distribution may result in service unavailability.
If uneven traffic occurs, services become slower and errors are returned. When you troubleshoot the common issues in these cases, you may be unable to identify the issues in time.
Trace Explorer allows you to view trace data that is grouped by IP address, including the instances on which requests are distributed and the traffic distribution changes after an issue occurs. If a large number of requests are concentrated on one or a few instances, this may be caused by uneven traffic. You can troubleshoot the issue based on the traffic distribution changes and roll them back in time.
On the Trace Explorer page, group the trace data by IP address. Most of the traffic is concentrated on the opentelemetry-demo-frontend-XX instance, as shown in the following figure.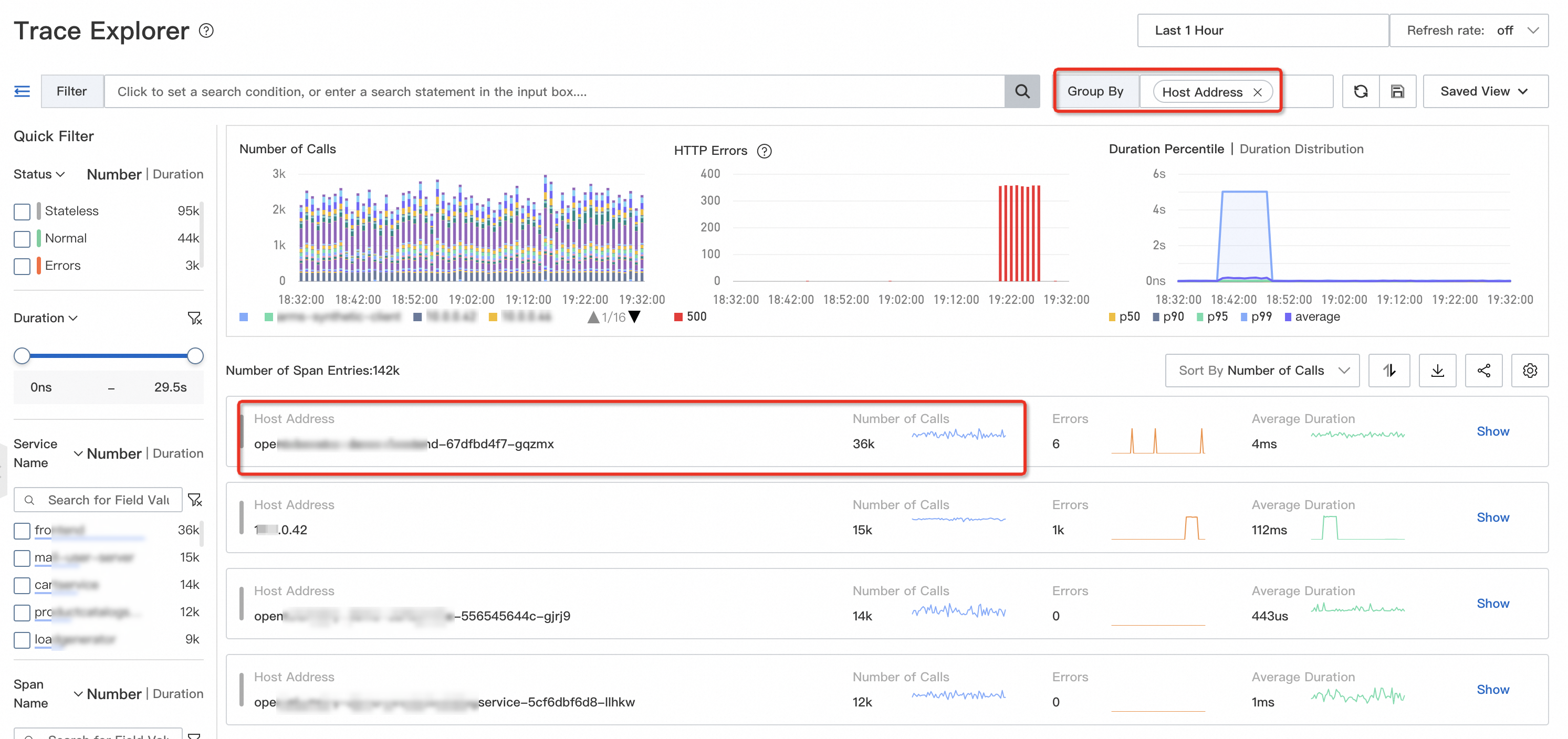
Scenario 2: Instance failures
How do I troubleshoot an instance failure?
Instance failures such as network interface controller damages, CPU overcommitment, and overloaded disk usage may occur at any time. Instance failures do not cause severe service unavailability. However, they cause a few request failures or timeouts, which continuously affect user experience and increase the cost of technical support. If you identify an instance failure, you must fix it at your earliest opportunity.
Instance failures are divided into two types: host failures and container failures. If you use a Kubernetes environment, instance failures include node failures and pod failures. CPU overcommitment and hardware damages are host failures, which affect all containers. Container failures such as overloaded disk usage and memory leaks affect only a single container. Therefore, you can troubleshoot an instance failure based on the host IP addresses and container IP addresses.
To check whether an instance failure occurs, you can query failed or timed out requests by using Trace Explorer, and then perform aggregation analysis based on host IP addresses or container IP addresses. If invalid requests are concentrated on a single instance, you can use another instance for quick recovery, or check the system parameters of the instance, such as the disk usage and CPU steal time. If invalid requests are scattered across multiple instances, this is not an instance failure. The downstream services or program logic may have errors.
On the Trace Explorer page, query failed or timed out requests and group the requests by IP address. If these requests are concentrated on a specific instance, the instance may fail.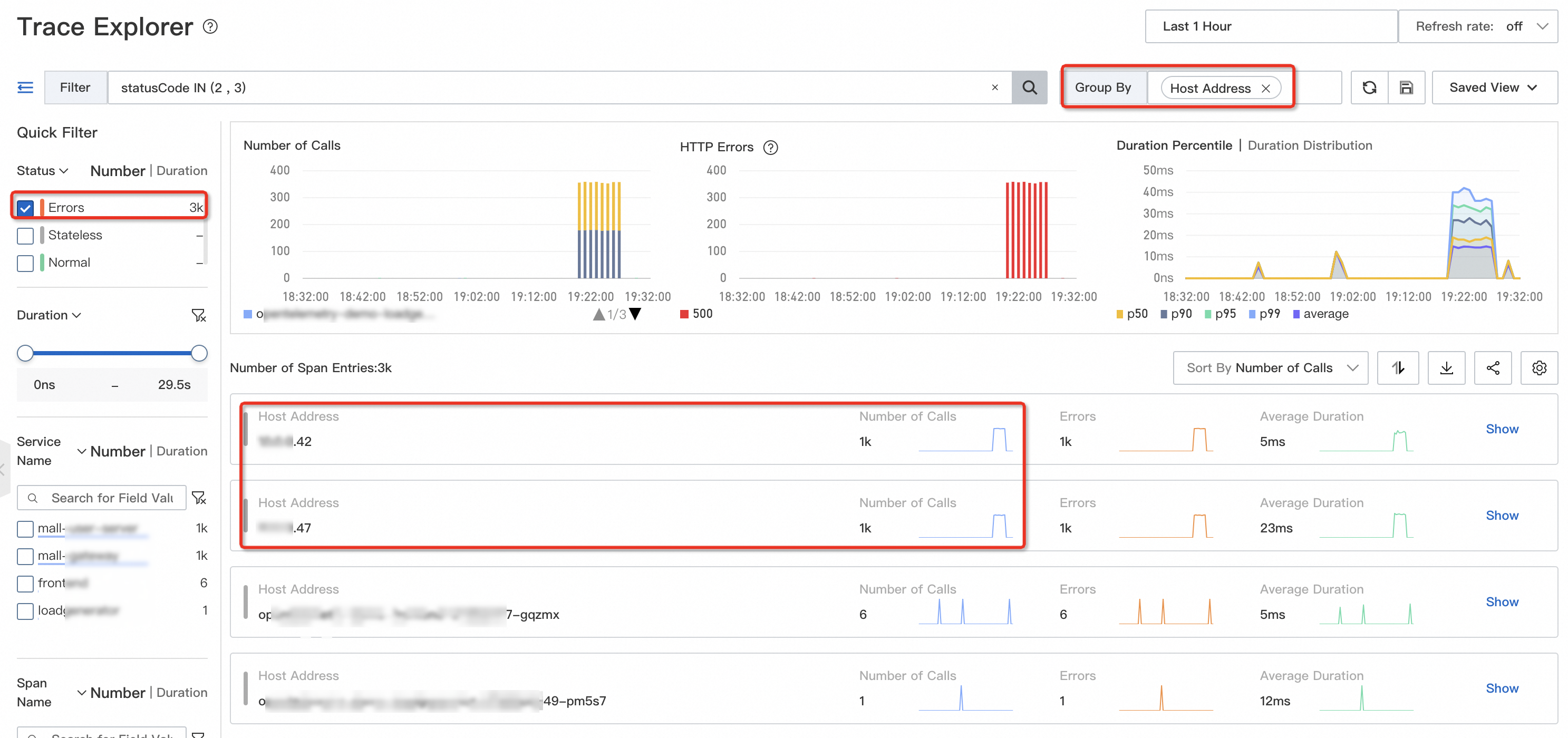
Scenario 3: Slow interfaces
How do I query slow interfaces before I release an application or implement a promotion?
Comprehensive performance optimization is required before an application is released or a promotion is implemented. You must first identify the performance bottlenecks and query the list and frequency of slow interfaces.
To troubleshoot slow interfaces, you can use Trace Explorer to query the interfaces that consume more time than a specific value, and group them by name.
Then, you can analyze the reasons of slow interfaces based on the traces, method stacks, and thread pool. Slow interfaces may occur due to the following reasons:
The connection pool of the database or microservice is too small and a large number of requests are waiting for connections. You can increase the maximum number of threads in the connection pool.
External requests and internal requests are sent at a time. You can merge these requests to reduce the time consumed for network transmission.
A single request contains a large amount of data. In this case, the network transmission and deserialization may take a long time and cause full garbage collections (GCs). You can replace the full query with a paged query.
The efficiency of synchronous logging is low. You can replace synchronous logging with asynchronous logging.
On the Trace Explorer page, query the slow interfaces that take more than 5 seconds and group them by IP address.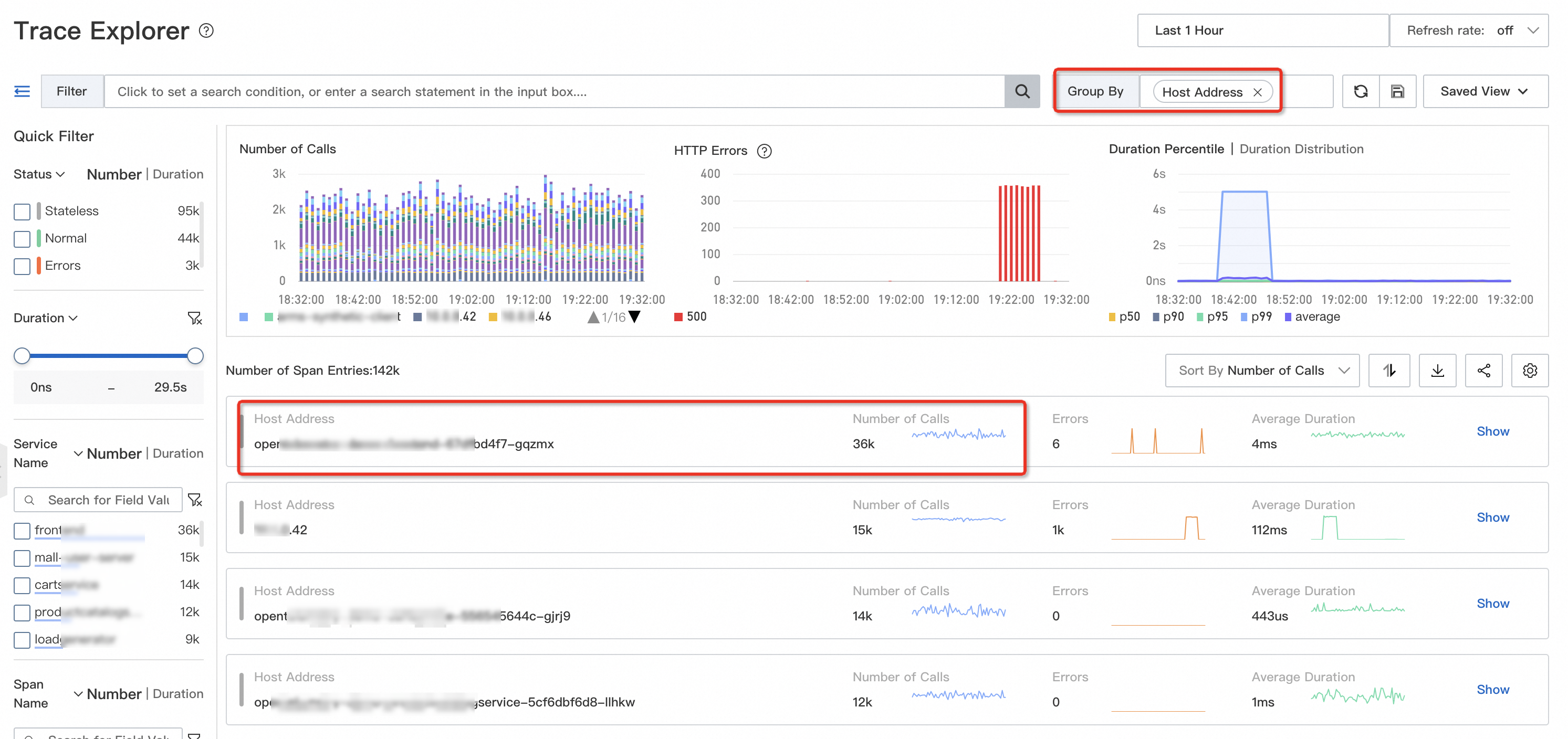
Scenario 4: Service traffic statistics
How do I analyze the traffic changes and service quality of major customers or stores?
A service is complicated and refined. If you need to analyze a service, you may need to consider various dimensions, such as category, store, and user. For example, for a physical retail store, a wrong order or broken POS machine may cause a public relations (PR) crisis. Physical stores have higher service level agreement (SLA) requirements than online stores. Therefore, you may need to monitor the traffic changes and service quality of physical retail stores.
You can query and analyze trace data by setting attributes as filter conditions. For example, you can specify the attribute {"attributes.channel": "offline"} for offline orders. You can also specify other attributes to differentiate stores, users, and categories. You can query the traces whose attributes channel is set to offline, and group the traces by the number of requests, time, and error rate. This way, you can analyze the traffic changes and service quality of customers or stores.
Scenario 5: Canary release monitoring
I want to release 500 instances in 10 batches. How do I identify errors after the first batch?
To ensure application stability, you can implement canary release, monitoring, and rollback. Canary release is a key method to ensure application stability. If you identify errors after you release a few batches of instances, you must roll back the release. The lack of effective canary release monitoring may cause service failures.
For example, if the registry of a microservice fails, you cannot register the microservice on the instances that you need to restart or release. However, you are unable to identify the error due to the lack of canary release monitoring. This is because the overall traffic or duration of the service does not have unexpected changes. You cannot register the microservice on all batches of the instances. In this case, the service becomes unavailable.
In the preceding example, you can specify the attribute {"attributes.version": "v1.0.x"} for different versions of instances, and use Trace Explorer to query the traces by attributes.version. This way, you can differentiate the traffic changes and service quality of different instance versions before and after the release. Therefore, you can monitor canary release in real time.
Limits
Trace Explorer can meet the requirements of custom diagnostics in different scenarios. However, it has the following limitations:
The cost of analysis based on detailed trace data is high.
To ensure analysis accuracy, you need to upload full trace data to Trace Explorer. However, this may incur high storage costs. To reduce storage costs, especially the storage costs incurred across networks, you can deploy edge nodes in user clusters to temporarily cache and process data. You can also separately store hot data and cold data on the server. Then, use Trace Explorer to analyze hot data. For cold data, you can analyze only the slow and invalid traces.
Post-aggregation analysis is not suitable for alerting because it has high performance overhead and low concurrency.
Trace Explorer scans full data and generates statistics in real time. The query performance overhead is much greater than the pre-aggregated statistics. Therefore, Trace Explorer is not suitable for alerting, which requires high concurrency. You need to customize metrics and execute post-aggregation analysis statements on the client to generate trace statistics. This way, you can customize alerts and dashboards.
Trace Explorer requires you to manually specify attributes.
Trace Explorer is different from common pre-aggregated metrics of application monitoring. To differentiate business scenarios and perform accurate analysis, you need to manually specify various attributes.
References
You can configure alerting for one or more interfaces. This way, alert notifications are sent to the O&M team when exceptions occur. For more information, see Application Monitoring alert rules.