ApsaraDB for Cassandra of the high availability configuration does not require timeout detection and log playback, causing minimum impact (measured in milliseconds) on the system.
| QUORUM | High availability mechanism | Raft | Region | |
|---|---|---|---|---|
| Fault detection | Coordinator node and client retry, no need for timeout detection, log playback, or leader reelection | Client retry, timeout detection, and log playback | Client retry and leader reelection | Client retry, timeout detection, and log playback |
| Response time | milliseconds | 10 seconds to 10 minutes | 10 seconds to 10 minutes | 1 minute to 10 minutes |
| Typical system | Cassandra | RDS, MongoDB, and Redis of the primary/secondary architecture | N/A | HBase |
Recommended configuration
The basic requirements for high availability configurations are as follows:
Replication Factor: >= 3.
Cluster nodes: >= Replication Factor.
Write consistency level: LOCAL_QUORUM;
Read consistency level: ONE, LOCAL_ONE, LOCAL_QUORUM. During a LOCAL_QUORUM read, Cassandra returns a response reflecting the most recent updates from all prior successful write operations. ONE or LOCAL_ONE consistency level can improve the performance and availability of the read requests, but the response might not reflect the results of a recently completed write. If you need high availability, it should not config the consistency level that requiring all the data copies read successful, such as ALL, Three. Because when one node is failed, the read may fail.
Fault testing
Kill one node out of three nodes that each has 2 cores CPU and 4 GB of memory when intensive write operations are performed. The client operation status is as follows:
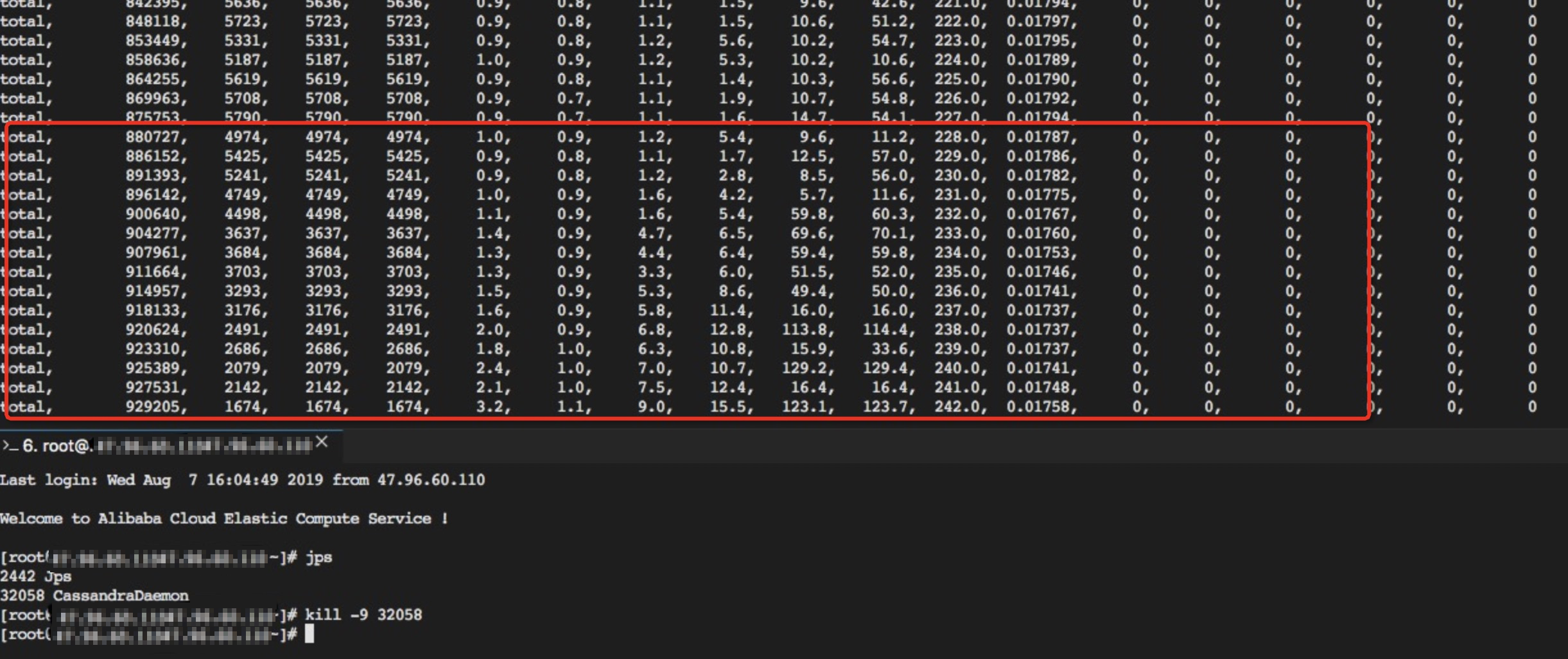
The Cassandra service is not affected when a node is killed.
</article></main>