As one of the most widely used middleware products, ACM has been adopted extensively to manage configurations of Alibaba’s internal applications since 2008. ACM has a wide range of use cases in many core scenarios. This topic describes a few typical scenarios where ACM is used.
Configuration management under the microservice application architecture
Under the microservice architecture, configuration management (such as DB_URL access information, service connection pool, and internal cache size of services) becomes cumbersome as the number of applications and machines increases. In this case, configuration distribution across multiple machines in a single application, and application-to-application configuration dependency can be great challenges.
In traditional architecture, the entire application must be re-packaged and published again even though only one configuration item is modified. This process is complex and error-prone, as shown in the following figure.

In an ACM-based microservice scenario, important application configuration information is published to ACM. The release of new configurations does not require configuration packaging. The applications take effect immediately after the new configurations are released, as shown in the following figure.

The use of ACM as a configuration center brings microservices the following benefits:
- All configurations are centralized, which makes it easier to manage the configurations of large amount of applications.
- Configuration publishing is not dependent on version updates, making it more flexible to modify configurations.
- ACM supports gray release and rollback, improving the security of configuration updates in a microservice architecture.
Service governance under the distributed architecture
Under various distributed architectures, it is critical to optimize service governance based on a certain RPC framework (such as RESTful, HSF, and Dubbo). Service administration functions including service routing, rate limiting, service downgrading, and service authentication can all be done using the configuration center.
Take request throttling and service degradation as an example. During Alibaba’s Double 11 events, each operation related to request throttling or service degradation requires response within seconds. This can be achieved using ACM.
In this process, the server of each RPC listens for the service rate limiting information by registering listeners through ACM. When an application requires rate throttling, the administrator performs request control in the service governance console. Then, the service governance system pushes the throttling information through ACM to the target application server to enable the corresponding configuration to take appropriate throttling action.

ACM brings the following benefits to service governance under distributed architectures:
- Good performance. Listens for service governance information through configuration push without compromising performance.
- Quick response. Service governance information can be pushed in seconds.
- Quick error correction. When service rate throttling or degradation information is pushed incorrectly, configuration can be rolled back in seconds.
Dynamic configuration push in business scenarios
Other typical use cases of ACM include speeding up the rollout of web pages in marketing activities, so as to reduce development costs and improve marketing efficiency.
Take e-commerce operations as an example. By embedding the ACM configuration (such as the third-party library version number and the static resource URL) in the frontend Javascript, operation staff can modify ACM configuration rules using operation tools to bring frontend Javascript presentation into effect when running promotional activities.
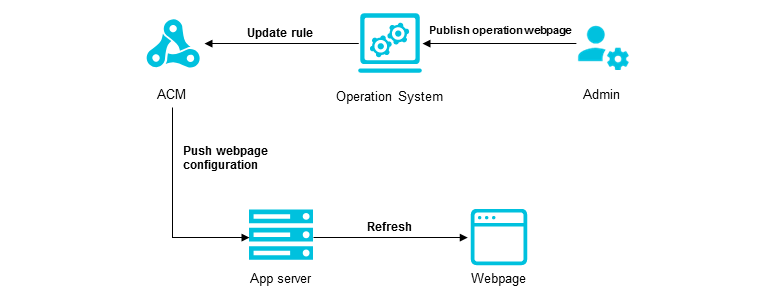
ACM brings the following benefit to configuration push in business scenarios:
- Decoupling static business code from business scenarios using configurations to greatly optimize the operation-related application publishing process.
Algorithm adjustment for real-time big data computing
In real-time big data computing, calculation parameters are adjusted dynamically to obtain the most accurate real-time calculation results.
Take an APM monitoring system in Alibaba as an example. The monitoring system dynamically adjusts the threshold values of businesses to control the real-time computing system and create business alarms. The threshold value modification must be completed in real time without application downtime. The calculated threshold values of the monitoring system are pushed under ACM rules.
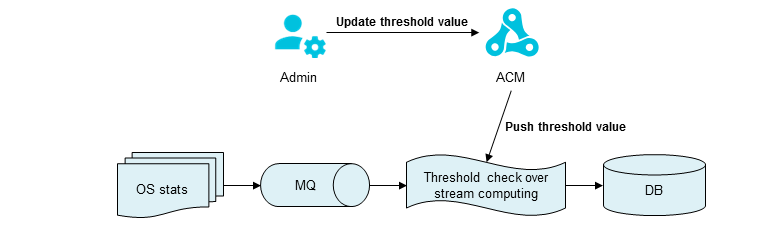
ACM brings the following benefit to real-time big data computing scenarios:
- Dynamic configuration of calculation parameters, which can take effect quickly with little impact on performance.
Multi-Site High Availability architecture in enterprise Internet architectures
Multi-Site High Availability solution is an advanced disaster recovery architecture in enterprise Internet architectures. Compared with the traditional disaster recovery architecture, it features quick business recovery, low capacity requirements, and effective and simple maintenance. Currently, the Multi-Site High Availability architecture has been widely used in companies like Alibaba and Ele.me.
At Alibaba, the core algorithms, ID shards and relevant routing rules of the Multi-Site High Availability architecture are all pushed by ACM dynamically. The related clients and servers, such as RPC, MQ, and DB are embedded with the routing path. During a disaster recovery drill test or when a real disaster occurs, the administrator only needs to dynamically push the rules, and these rules will have an affect on every architecture component. This is shown in the following figure.

The use of ACM brings the applications in the remote Multi-Site High Availability architecture the following benefits:
- The infrastructure and the disaster recovery logic are decoupled. The specific routing logic is determined by the disaster recovery switching rules.
- Theoretically, disaster recovery switching rules can be pushed to hundreds of thousands of machines and take effect in seconds.