The table partitioning feature is supported for Object Storage Service (OSS) foreign tables. If the WHERE clause of a query statement contains a partition column, you can improve query efficiency by scanning less data from OSS.
Precautions
To use the partitioning feature of OSS foreign tables, make sure that the object directory is in the following format: oss://bucket/partcol1=partval1/partcol2=partval2/. In this directory, partcol1 and partcol2 indicate the partition columns, and partval1 and partval2 indicate the values in the preceding partition columns.
For example, assume that a table is partitioned based on the year column and then subpartitioned based on the month column. If the value in the year column is 2022 and the value in the month column is 07, the associated partition is stored in the oss://bucket/year=2022/month=07 directory.
Create an OSS server and a user mapping to the OSS server
Before you use OSS foreign tables, you must create an OSS server and a user mapping to the OSS server.
- For more information about how to create an OSS server, see the "Create an OSS server" section of the Use OSS foreign tables for data lake analysis topic.
- For more information about how to create a user mapping to the OSS server, see the " Create a user mapping to the OSS server" section of the Use OSS foreign tables for data lake analysis topic.
Create a partitioned table
You can execute a CREATE FOREIGN TABLE statement to create a partitioned OSS foreign table. The syntax used to create a partitioned OSS foreign table is the same as that used to create a standard partitioned table. For more information, see Define table partitioning.
For more information about CREATE FOREIGN TABLE, see Create an OSS foreign table.
OSS foreign tables support only list partitions.
Create a partitioned table named
ossfdw_parttableand specify a partition template. Example:CREATE FOREIGN TABLE ossfdw_parttable( key text, value bigint, pt text, -- Define a partition key. region text -- Define a subpartition key. ) SERVER oss_serv OPTIONS (dir 'PartationDataDirInOss/', format 'jsonline') PARTITION BY LIST (pt) -- Use the pt field to partition the table. SUBPARTITION BY LIST (region) -- Use the region field to subpartition the table. SUBPARTITION TEMPLATE ( -- Specify a subpartition template. SUBPARTITION hangzhou VALUES ('hangzhou'), SUBPARTITION shanghai VALUES ('shanghai') ) ( PARTITION "20170601" VALUES ('20170601'), PARTITION "20170602" VALUES ('20170602'));Create a partitioned table named
ossfdw_parttable1without specifying a partition template. Example:CREATE FOREIGN TABLE ossfdw_parttable1( key text, value bigint, pt text, -- Define a partition key. region text -- Define a subpartition key. ) SERVER oss_serv OPTIONS (dir 'PartationDataDirInOss/', format 'jsonline') PARTITION BY LIST (pt) -- Use the pt field to partition the table. SUBPARTITION BY LIST (region) -- Use the region field to subpartition the table. ( -- The following partitions contain different subpartitions: VALUES('20181218') ( VALUES('hangzhou'), VALUES('shanghai') ), VALUES('20181219') ( VALUES('nantong'), VALUES('anhui') ) );
Adjust the schema of a partitioned OSS foreign table
You can execute an ALTER TABLE statement to adjust the schema of a partitioned OSS foreign table. AnalyticDB for PostgreSQL allows you to create or delete partitions and subpartitions in OSS foreign tables.
Create partitions and subpartitions
Create a partition
Create a partition in the
ossfdw_parttabletable. The system automatically generates corresponding subpartitions based on the partition template specified when you create the table. Example:ALTER TABLE ossfdw_parttable ADD PARTITION VALUES ('20170603');The following figure shows the change to the table schema.
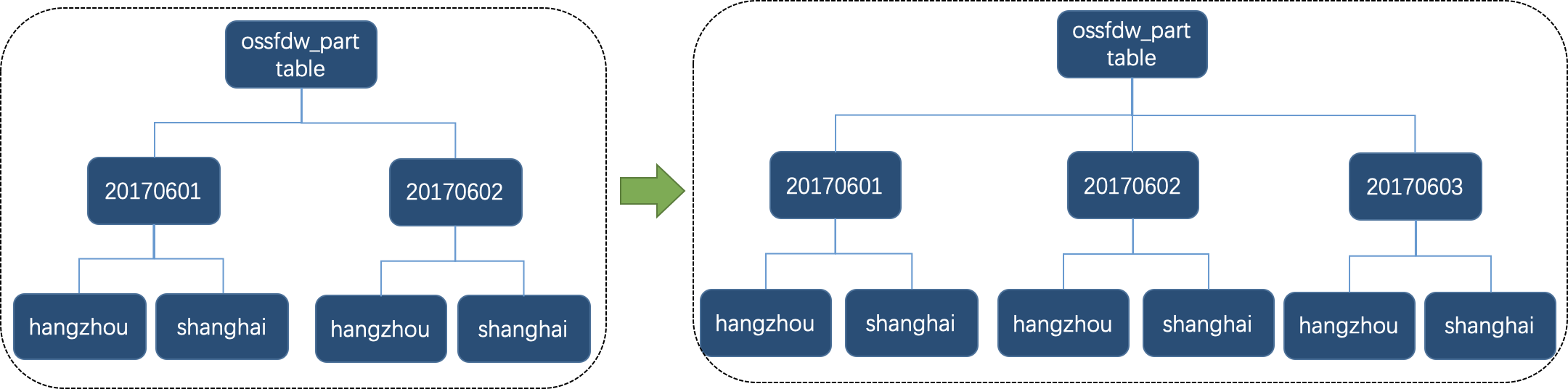
Create a partition in the
ossfdw_parttable1table. You must specify subpartitions in the partition because no partition template is specified when you create the table. Example:ALTER TABLE ossfdw_parttable1 ADD PARTITION VALUES ('20181220') ( VALUES('hefei'), VALUES('guangzhou') );
Create a subpartition
Create a subpartition in the
20170603partition of theossfdw_parttabletable. Example:ALTER TABLE ossfdw_parttable ALTER PARTITION FOR ('20170603') ADD PARTITION VALUES('nanjing');The following figure shows the change to the table schema.

Delete partitions and subpartitions
Delete a partition. Example:
ALTER TABLE ossfdw_parttable DROP PARTITION FOR ('20170601');Delete a subpartition. Example:
ALTER TABLE ossfdw_parttable ALTER PARTITION FOR ('20170602') DROP PARTITION FOR ('hangzhou');
Delete a partitioned table
You can execute a DROP FOREIGN TABLE statement to delete a partitioned table.
Delete a partitioned table. Example:
DROP FOREIGN TABLE ossfdw_parttable;Use OSS foreign tables to access log data shipped by Log Service
Partitioned OSS foreign tables can be used when you access log data shipped by Log Service. If you use an appropriate object path when you write data from Log Service to OSS, you can create a partitioned OSS foreign table.
For more information about Log Service, see What is Simple Log Service?
Ship log data from Simple Log Service to OSS.
In the OSS LogShipper panel, we recommend that you set Shard Format to
date=%Y%m/userlogin. An example of the generated OSS object path is in the following format:oss://testBucketName/adbpgossfdw ├── date=202002 │ ├── userlogin_158561762910654****_647504382.csv │ └── userlogin_158561784923220****_647507440.csv └── date=202003 └── userlogin_158561794424704****_647508762.csvCreate a partitioned OSS foreign table based on the key fields of log data shipped by Log Service. Example:
CREATE FOREIGN TABLE userlogin ( uid integer, name character varying, source integer, logindate timestamp without time zone, "date" int ) SERVER oss_serv OPTIONS ( dir 'adbpgossfdw/', format 'text' ) PARTITION BY LIST ("date") ( VALUES ('202002'), VALUES ('202003') )Query and analyze the execution plan of a SELECT statement on the log data shipped by Log Service.
For example, assume that you want to query the total number of user logons in February 2022.
EXPLAIN SELECT uid, count(uid) FROM userlogin WHERE "date" = 202002 GROUP BY uid;The following information is returned:
QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------------------------------------------- Gather Motion 3:1 (slice2; segments: 3) (cost=5135.10..5145.10 rows=1000 width=12) -> HashAggregate (cost=5135.10..5145.10 rows=334 width=12) Group Key: userlogin_1_prt_1.uid -> Redistribute Motion 3:3 (slice1; segments: 3) (cost=5100.10..5120.10 rows=334 width=12) Hash Key: userlogin_1_prt_1.uid -> HashAggregate (cost=5100.10..5100.10 rows=334 width=12) Group Key: userlogin_1_prt_1.uid ->t; Append (cost=0.00..100.10 rows=333334 width=4) -> Foreign Scan on userlogin_1_prt_1 (cost=0.00..100.10 rows=333334 width=4) Filter: (date = 202002) Oss Url: endpoint=oss-cn-hangzhou-zmf-internal.aliyuncs.com bucket=adbpg-regress dir=adbpgossfdw/date=202002/ filetype=plain|text Oss Parallel (Max 4) Get: total 0 file(s) with 0 bytes byte(s). Optimizer: Postgres query optimizer (13 rows)The returned information shows that only data in the date=202002 directory needs to be scanned. The less data scanned, the higher the query efficiency.