This topic describes how to optimize grouping and aggregation queries in AnalyticDB for MySQL.
Grouping and aggregation process
AnalyticDB for MySQL is a distributed data warehousing service. By default, AnalyticDB for MySQL performs the following steps to execute a grouping and aggregation query:
Perform partial aggregation on data.
Partial aggregation nodes use only a small amount of memory. The aggregation process is stream-based, which prevents data from piling up on partial aggregation nodes.
After the partial aggregation is complete, redistribute data among nodes based on the GROUP BY fields and then perform final aggregation.
Partial aggregation results are transmitted over networks to the nodes of a downstream stage. For more information, see Factors that affect query performance. Partial aggregation reduces the amount of data that needs to be transmitted over networks. As a result, the network pressure is reduced. After the data is redistributed, final aggregation is performed. On the final aggregation node, the values and aggregation state data of a group must be maintained in the memory until all data is processed. This ensures that no new data needs to be processed for a specific group value. In this case, the final aggregation node may occupy a large amount of memory.
For example, execute the following SQL statement to perform grouping and aggregation:
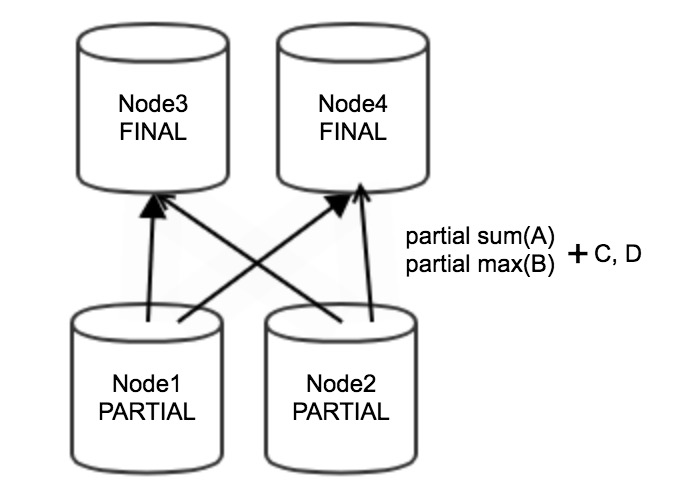
SELECT sum(A), max(B) FROM tb1 GROUP BY C,D;When the preceding statement is executed to perform grouping and aggregation, partial aggregation is first performed on Node 1 and Node 2 of the upstream stage. Partial aggregation results are partial sum(A), partial max(B), C, and D. The partial aggregation results are transmitted over networks to Node 3 and Node 4 of the downstream stage for final aggregation, as shown in the following figure.
Use hints to optimize grouping and aggregation
Scenarios
In most scenarios, two-step aggregation can strike a good balance between memory and network resources. However, in special scenarios that involve a large number of unique values in GROUP BY fields, two-step aggregation may not be the best choice.
For example, you want to group data by mobile number or user ID. If you use the two-step aggregation method, only a small amount of data can be aggregated, but the partial aggregation step is performed with multiple operations, such as calculating hash values of groups, deduplication, and executing aggregation functions. In this example, a large number of groups are involved. As a result, the partial aggregation step does not reduce the amount of data to be transmitted over networks but consumes large amounts of computing resources.
Solution
To resolve the preceding issue of a low aggregation rate, you can add the
/*+ aggregation_path_type=single_agg*/hint to skip partial aggregation and directly perform final aggregation when you execute a query. This reduces unnecessary computing overheads.NoteIf the
/*+ aggregation_path_type=single_agg*/hint is used in an SQL statement, all grouping and aggregation queries in the SQL statement use the specified optimization process. We recommend that you analyze the characteristics of aggregation operators in the original execution plan, evaluate the benefits of the hint, and then determine whether to use this optimization scheme.Optimization description
If the aggregation rate is low, the partial aggregation that is performed on Node 1 and Node 2 of the upstream stage does not reduce the amount of data to be transmitted over networks but consumes large amounts of computing resources.
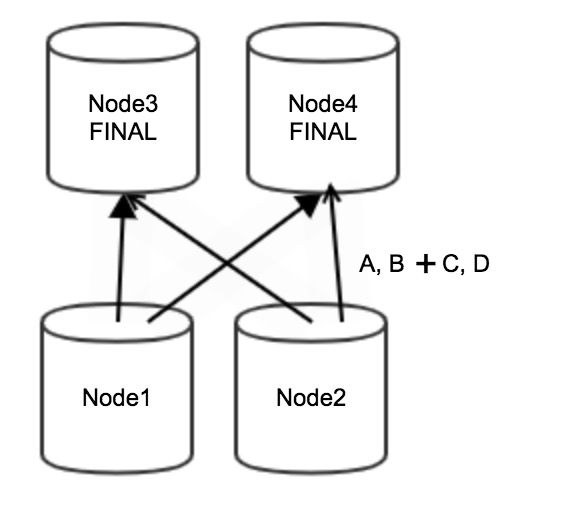
After optimization, partial aggregation is not performed on Node 1 and Node 2. All data (A, B, C, and D) is directly aggregated on Node 3 and Node 4 of the downstream stage, which reduces the amount of required computing resources, as shown in the following figure.
 Note
NoteThis optimization may not optimize memory usage. If the aggregation rate is low, large amounts of data are accumulated in memory for deduplication and aggregation to ensure that all data for a specific group value is processed.