The XUANWU analytical storage engine provides highly reliable and highly available enterprise-class data storage capabilities with high performance at low costs. This helps AnalyticDB for MySQL implement high-throughput, real-time data writes and high-performance, real-time queries.
XUANWU analytical storage engine (XUANWU)
High-throughput real-time data write
AnalyticDB for MySQL uses a three-layer architecture to provide high throughput capabilities. The access node layer, storage node layer, and persistent distributed storage layer can be scaled out in parallel. AnalyticDB for MySQL supports the hybrid row-column storage format and the asynchronous migration of incremental data to implement high-throughput, high-concurrency, real-time data writes.
AnalyticDB for MySQL uses the Raft consensus protocol and the apply method to synchronously write data. This allows you to query data immediately after the data is written and ensures write consistency. The XUANWU engine uses the mark-for-delete technology to allow you to update and delete data in real time with high throughput, and uses the multiversion concurrency control (MVCC) technology to ensure data atomicity and integrity.

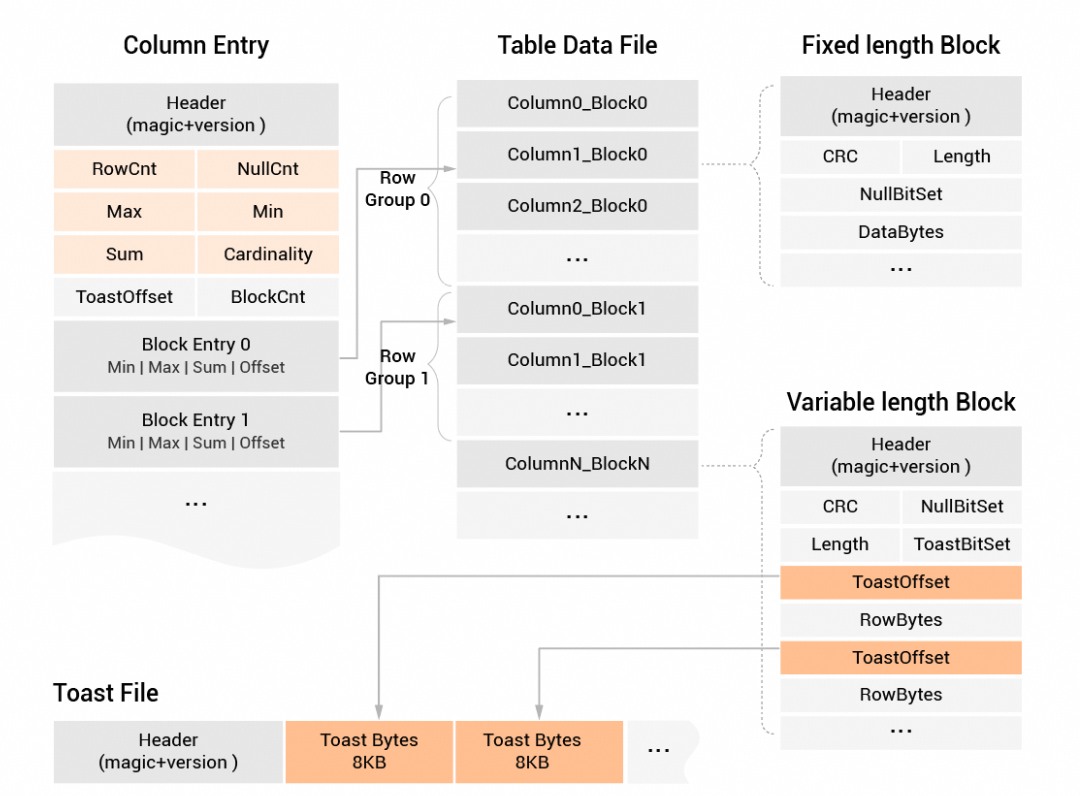
Hybrid row-column storage
The XUANWU engine supports the hybrid row-column storage format, which is similar to the Optimized Row Columnar (ORC) or Parquet format in Apache Hadoop. The hybrid row-column storage format supports analytical column pruning, high-throughput data scanning, and row alignment to implement high-performance, random queries, especially in scenarios that involve multidimensional index filtering.
The following figure shows the hybrid row-column storage format.
Adaptive indexing
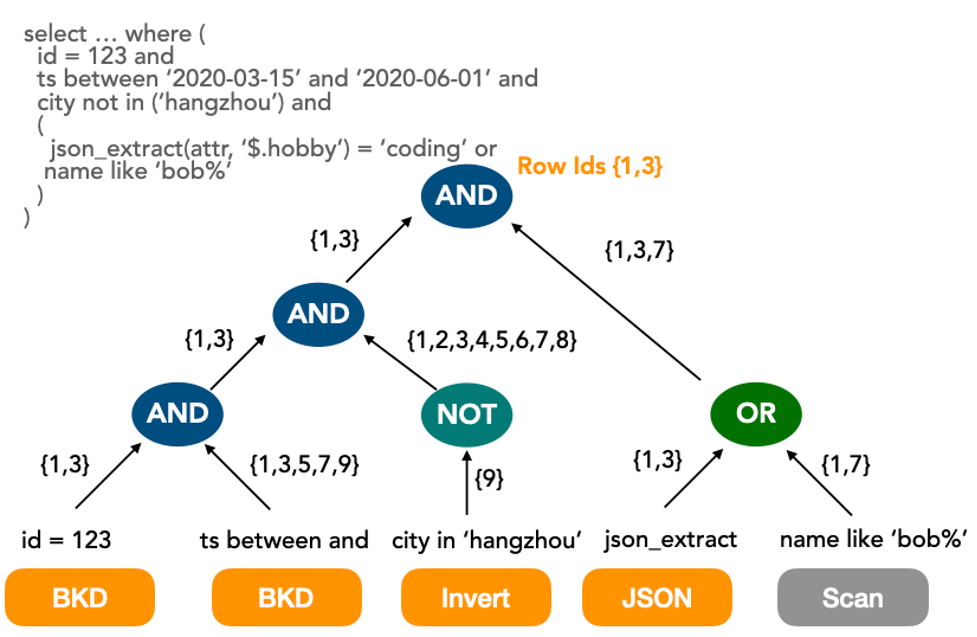
In online analytical processing (OLAP) scenarios, multidimensional queries are required, but traditional single-column or combined indexes in online transaction processing (OLTP) scenarios cannot meet the requirements. The XUANWU engine uses adaptive indexing on columns to automatically configure the index data structure for column types such as STRING, NUMBER, TEXT, JSON, and VECTOR. Additionally, The XUANWU engine uses column-level indexes to implement multidimensional combined retrieval and multiway merges in a progressive streaming manner. This greatly improves the data filtering performance.
The following types of indexes are supported: inverted indexes, BKD-tree indexes, and bitmap indexes. The index performance varies based on data distribution characteristics, such as the cardinality and the number of table records for range queries. In specific scenarios, indexing overheads are higher than scanning overheads. Example: a query that involves the conditions age > 0 and age <100. The XUANWU engine determines whether to index or scan data based on cost-based optimization (CBO).
The following figure shows how to use multiway merges for different types of indexes.
Fusion of structured and unstructured indexes
The index manager of the XUANWU engine manages structured and unstructured indexes at the storage layer in a centralized manner. The indexes include BKD indexes of numerical values, inverted indexes of strings, unstructured JSON and vector indexes, and full-text indexes of text data. The index manager provides a unified expression for the compute layer, which allows the SQL logic of the compute layer to be compatible with different data types and accelerates queries. AnalyticDB for MySQL performs correlation analysis between full-text data and structured tables to support complex SQL logic. Example:

The preceding query performs an association analysis on the result set obtained from the full-text searches in the subqueries, sorts the analyzed results in descending order based on the scores, and returns the first 10,000 rows.
XUANWU analytical storage engine V2 (XUANWU_V2)
The XUANWU_V2 engine is the next-generation storage engine that is developed based on the XUANWU engine for AnalyticDB for MySQL.
Efficient data organization
The XUANWU_V2 engine optimizes the data organization method. Data is written to the real-time engine in append mode and then flushed to the read-friendly full-data engine. Then, compaction tasks compact data within or between the levels of the full-data engine, ensuring that data below the L0 level is partitionally ordered and physically organized based on fixed sizes.
The following figure shows how data is organized.

This data organization method ensures that the real-time engine can construct data for the read-friendly full-data engine in a timely manner and improve query performance. In addition, this method significantly alleviates the read amplification issue during compaction, which further reduces CPU and I/O consumption. The XUANWU_V2 engine can use this method to adaptively split and compact partition files that are excessively large or small. You do not need to be troubled by the selection of partition keys.
Efficient storage format
The XUANWU_V2 engine uses a file format that organizes I/O blocks by fixed size on top of the original file format that organizes column-level I/O blocks by the fixed number of rows. The new I/O block organization method not only optimizes I/O and memory management and resolves issues caused by row alignment and inconsistencies in I/O size, but also improves memory reuse efficiency and reduces overheads of memory application and reclamation. The new I/O block organization method aligns memory and I/O operations, which further reduces read amplification and I/O costs.

Better horizontal scaling elasticity
The XUANWU_V2 engine stores all data in Object Storage Service (OSS), which significantly reduces user storage costs and greatly improves the efficiency of horizontal scaling and node migration. The XUANWU_V2 engine uses Enterprise SSDs (ESSDs) as the query cache and allows you to execute DDL statements to prefetch data in specific partitions and query automatically cached data. This effectively improves query performance.