AnalyticDB for MySQL provides the vector search feature to help you implement similarity search on unstructured data. This topic describes the vector search feature and how to create and use vector indexes.
Prerequisites
An AnalyticDB for MySQL cluster of V3.1.4.0 or later is created.
To use the vector search feature, we recommend that you use the following minor versions: 3.1.5.16, 3.1.6.8, 3.1.8.6, and later.
If your cluster is not of the preceding versions, we recommend that you set the CSTORE_PROJECT_PUSH_DOWN and CSTORE_PPD_TOP_N_ENABLE parameters to false before you use the vector search feature.
For information about how to query the minor version of an AnalyticDB for MySQL cluster, see How do I query the version of an AnalyticDB for MySQL cluster? To update the minor version of a cluster, contact technical support.
Background information
Overview
You can use AI algorithms to extract features from unstructured data, encode the features into feature vectors, and then store the feature vectors in AnalyticDB for MySQL. When you use feature vectors to identify unstructured data, the distance between vectors can be used to measure the similarity between different unstructured data. AnalyticDB for MySQL provides the efficient vector search feature for scenarios such as image-based search, voiceprint matching, facial recognition, and text search.
Architecture
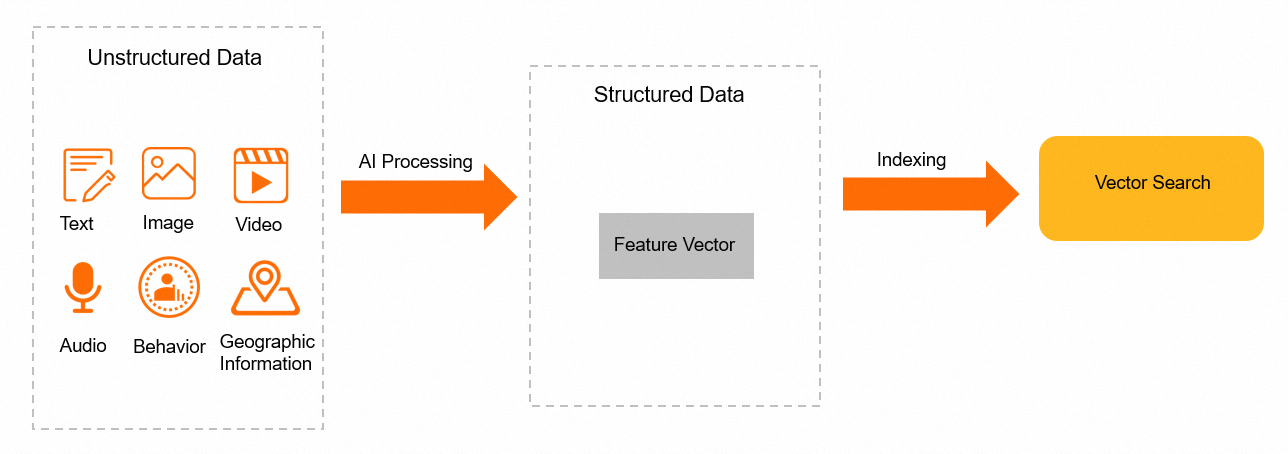
Benefits
High dimensionality, high performance, and high recall for vector data
In this example, a 512-dimensional vector that represents a human face is used. AnalyticDB for MySQL can provide a 99% recall for 10 billion entries of vector data in scenarios that require 100 queries per second (QPS) and a 50-millisecond response time or for 0.2 billion entries of vector data in scenarios that require 1,000 QPS and a 1-second response time.
Integrated query of structured and unstructured data
AnalyticDB for MySQL supports integrated query by using k-nearest neighbor (KNN) and radius nearest neighbor (RNN) algorithms. For example, you can compare the similarity between two sets of vectors.
Real-time updates
AnalyticDB for MySQL supports high-concurrency real-time writes and updates. You can query data immediately after the data is written.
Real-time search
AnalyticDB for MySQL uses a massively parallel processing (MPP) architecture to provide millisecond-level data search and improve search efficiency.
Ease of use
AnalyticDB for MySQL supports standard SQL statements to simplify the development process without the need for additional complex configurations.
Terms
Create a vector index
Syntax
You can create a vector index when you create a table by using the following syntax:
ANN INDEX [index_name] (column_name)] [algorithm=HNSW_PQ ] [distancemeasure=SquaredL2]Parameters
ANN INDEX: the keyword of the vector index.
index_name: the name of the index. For information about the naming conventions of indexes, see the "Naming limits" section of the Limits topic.
column_name: the name of the vector column. For information about the naming conventions of columns, see the "Naming limits" section of the Limits topic. Only the following data types are supported:
ARRAY<FLOAT>,ARRAY<BYTE>, andARRAY<SMALLINT>.algorithm: the algorithm that is used to calculate the vector distance. Set the value to
HNSW_PQ.distancemeasure: the formula that is used to calculate the vector distance. Set the value to
SquaredL2. Calculation formula ofSquaredL2:(x1 - y1)2 + (x2 - y2)2 + ...(xn - yn)2.
Example
In this example, a table named vector is created. The table contains two vector columns: float_feature and short_feature. The float_feature column is of the ARRAY<FLOAT> type and contains four-dimensional data. The short_feature column is of the ARRAY<SMALLINT> type and contains four-dimensional data. When the table is created, vector indexes are created on the two columns.
CREATE TABLE vector (
xid bigint not null,
cid bigint not null,
uid varchar not null,
vid varchar not null,
wid varchar not null,
float_feature array < float >(4),
short_feature array < smallint >(4),
ANN INDEX idx_short_feature(short_feature),
ANN INDEX idx_float_feature(float_feature),
PRIMARY KEY (xid, cid, vid)
) DISTRIBUTED BY HASH(xid);Add a vector index
Syntax
You can add a vector index after you create a table by using the following syntax:
ALTER TABLE table_name ADD ANN INDEX [index_name] (column_name) [algorithm=HNSW_PQ ] [distancemeasure=SquaredL2]Example
The vector table is created by executing the following statement:
CREATE TABLE vector (
xid BIGINT not null,
cid BIGINT not null,
uid VARCHAR not null,
vid VARCHAR not null,
wid VARCHAR not null,
float_feature array < FLOAT >(4),
short_feature array < SMALLINT >(4),
PRIMARY KEY (xid, cid, vid)
) DISTRIBUTED BY HASH(xid);Create vector indexes for the float_feature and short_feature columns in the vector table.
ALTER TABLE vector ADD ANN INDEX idx_float_feature(float_feature);
ALTER TABLE vector ADD ANN INDEX idx_short_feature(short_feature);Query vector data
You can add a distance calculation function to a SELECT statement to abstract the relationship between entities into the distance between vectors in a vector space. Example: L2_DISTANCE.
Example
Insert data
Insert data into the vector table.
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (1,2,'A','B','C','[1,1,1,1]','[1.2,1.5,2,3.0]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (2,1,'e','v','f','[2,2,2,2]','[1.5,1.15,2.2,2.7]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (0,6,'d','f','g','[3,3,3,3]','[0.2,1.6,5,3.7]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (5,4,'j','b','h','[4,4,4,4]','[1.0,4.15,6,2.9]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (8,5,'Sj','Hb','Dh','[5,5,5,5]','[1.3,4.5,6.9,5.2]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (5,4,'x','g','h','[3,4,4,4]','[1.0,4.15,6,2.9]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (5,4,'j','r','k','[6,6,4,4]','[1.0,4.15,6,2.9]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (5,4,'s','i','q','[2,2,4,4]','[1.0,4.15,6,2.9]');Query data
Query the top three entries in the short_feature column that have the shortest distance to the vector
'[1,1,1,1]'.SELECT xid, l2_distance(short_feature, '[1,1,1,1]') as dis FROM vector ORDER BY 2 LIMIT 3;Sample result:
+-------+--------------+ | xid | dis | +-------+--------------+ | 1 | 0.0 | +-------+--------------+ | 2 | 4.0 | +-------+--------------+ | 0 | 16.0 | +-------+--------------+Query the top four entries in the short_feature column that have the shortest distance to the vector
'[1,1,1,1]'when xid is 5 and cid is 4.SELECT uid, l2_distance(short_feature, '[1,1,1,1]') as dis FROM vector WHERE xid = 5 AND cid = 4 ORDER BY 2 LIMIT 4;Sample result:
+-------+--------------+ | uid | dis | +-------+--------------+ | s | 20.0 | +-------+--------------+ | x | 31.0 | +-------+--------------+ | j | 36.0 | +-------+--------------+ | j | 68.0 | +-------+--------------+Query the top three entries in the short_feature column that have the shortest distance to the vector
'[1,1,1,1]'when the distance is less than or equal to 50 and xid is 5.SELECT uid, l2_distance(short_feature, '[1,1,1,1]') as dis FROM vector WHERE l2_distance(short_feature, '[1,1,1,1]') < 50.0 AND xid = 5 ORDER BY 2 LIMIT 3;Sample result:
+-------+---------------+ | uid | dis | +-------+---------------+ | s | 20.0 | +-------+---------------+ | x | 31.0 | +-------+---------------+ | j | 36.0 | +-------+---------------+