Alibaba Cloud Knative can integrate with the Horizontal Pod Autoscaler (HPA) to enable auto scaling based on resource load. Although Knative natively supports auto scaling based on the number of requests, integrating with HPA allows for fine-grained scaling using additional metrics such as CPU and memory usage.
Prerequisites
Knative is deployed in the cluster. For more information, see Deploy Knative in an ACK cluster.
A kubectl client is connected to the ACK cluster. For more information, see Obtain the kubeconfig file of a cluster and use kubectl to connect to the cluster.
To view Knative monitoring data on the Knative dashboard, make sure that Knative is connected to Managed Service for Prometheus. For more information, see View the Knative dashboard in Managed Service for Prometheus.
Step 1: Deploy a Knative Service
Log on to the ACK console. In the left-side navigation pane, click Clusters.
On the Clusters page, find the cluster that you want to manage and click its name. In the left-side pane, choose .
On the Services tab of the Knative page, select default from the Namespace drop-down list, click Create from Template, copy the following YAML content to the code editor, and then click Create.
The following sample code creates a Knative Service named
helloworld-go-hpa:apiVersion: serving.knative.dev/v1 kind: Service metadata: name: helloworld-go-hpa # Specify the name of the Knative Service. spec: template: metadata: labels: app: helloworld-go-hpa annotations: autoscaling.knative.dev/class: "hpa.autoscaling.knative.dev" # Specify HPA as the scaler. autoscaling.knative.dev/metric: "cpu" # The metrics supported by HPA include CPU utilization and memory utilization. In this example, HPA is configured to work based on CPU utilization. autoscaling.knative.dev/target: "30" # Specify the threshold of CPU utilization. HPA automatically scales pods for the Knative Service when the threshold is exceeded. autoscaling.knative.dev/minScale: "1" # Specify the minimum number of pods that must be guaranteed. autoscaling.knative.dev/maxScale: "4" # Specify the maximum number of pods that are allowed. spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/autoscale-go:v1024 resources: requests: cpu: '200m'Run the following command to check whether the Knative Service runs as expected:
kubectl get ksvcExpected output:
NAME URL LATESTCREATED LATESTREADY READY REASON helloworld-go-hpa http://helloworld-go-hpa.default.example.com helloworld-go-hpa-00001 helloworld-go-hpa-00001 TrueIf
Trueis displayed in theREADYcolumn, the Knative Service runs as expected.
Step 2: Send requests to test auto scaling based on CPU usage
Install the load testing tool hey.
For more information about hey, see Hey.
Run the following command to perform a load test by sending 100 queries per second (QPS) for 60 seconds:
NoteReplace
121.XX.XX.10with the IP address or domain name of the gateway.hey -z 60s -q 100 -host "helloworld-go-hpa.default.example.com" "http://121.XX.XX.10?prime=40000000" # 121.199.XXX.XXX is the IP address or domain name of the gateway.During the load test, you can run the following command to check whether pods are scaled in real time:
kubectl get pods --watchExpected output:
NAME READY STATUS RESTARTS AGE # The pod is running as expected and containers are in the ready state. helloworld-go-hpa-00001-deployment-67cc8f979b-fxfl5 2/2 Running 0 101m # The number of pods is scaled out to four. The READY column displays 0/2 for each pod and the STATUS column displays Pending for each pod. This means that the pods are pending and resources are not allocated to the pods. helloworld-go-hpa-00001-deployment-67cc8f979b-kv6rj 0/2 Pending 0 0s helloworld-go-hpa-00001-deployment-67cc8f979b-fxq85 0/2 Pending 0 0s helloworld-go-hpa-00001-deployment-67cc8f979b-kv6rj 0/2 Pending 0 0s helloworld-go-hpa-00001-deployment-67cc8f979b-fxq85 0/2 Pending 0 0s # The READY column displays 0/2 for each pod and the STATUS column displays ContainerCreating for each pod. This means that the containers in the pods are being created. helloworld-go-hpa-00001-deployment-67cc8f979b-kv6rj 0/2 ContainerCreating 0 0s helloworld-go-hpa-00001-deployment-67cc8f979b-fxq85 0/2 ContainerCreating 0 0s helloworld-go-hpa-00001-deployment-67cc8f979b-kv6rj 0/2 ContainerCreating 0 0s helloworld-go-hpa-00001-deployment-67cc8f979b-fxq85 0/2 ContainerCreating 0 0s # The READY column displays 1/2 for two pods and 2/2 for two pods, and the STATUS column displays Running for each pod. This means that at least one container is created and runs as expected for each pod. helloworld-go-hpa-00001-deployment-67cc8f979b-kv6rj 1/2 Running 0 1s helloworld-go-hpa-00001-deployment-67cc8f979b-kv6rj 2/2 Running 0 1s helloworld-go-hpa-00001-deployment-67cc8f979b-fxq85 1/2 Running 0 1s helloworld-go-hpa-00001-deployment-67cc8f979b-fxq85 2/2 Running 0 1sThe output shows that HPA can automatically scale pods for the Knative Service. When the load increases, HPA scales the number of pods from one to four to improve the processing capability and throughput of the Knative Service.
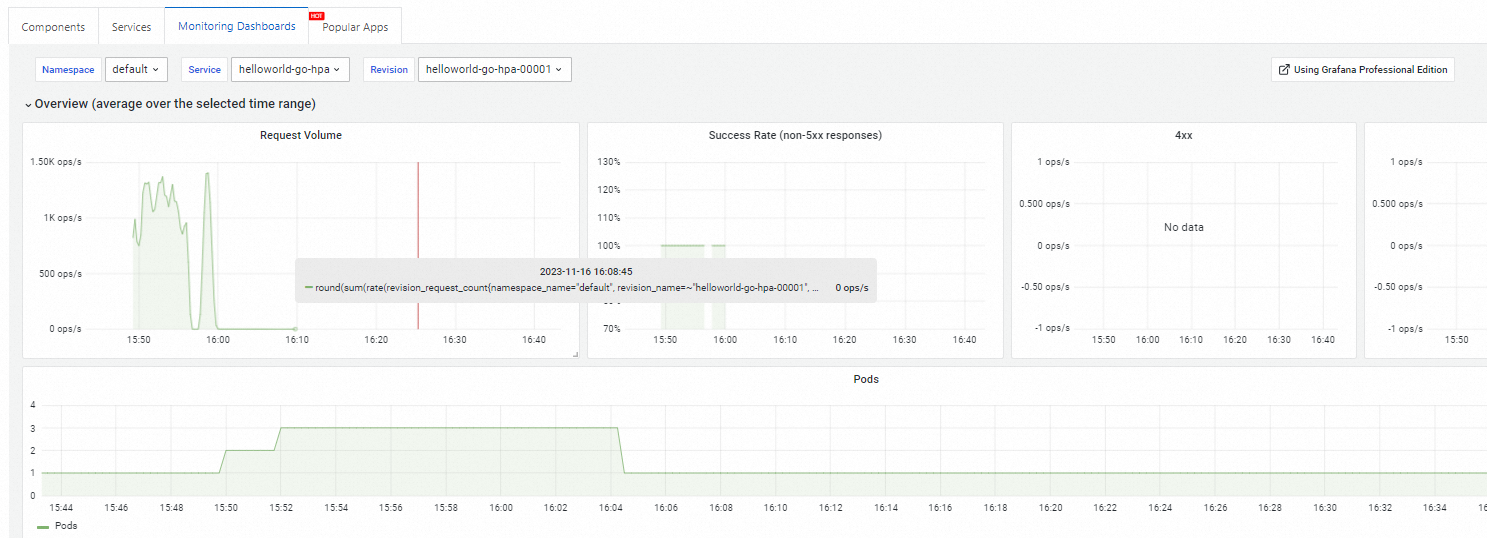
(Optional) Step 3: View the Knative dashboard
Knative provides out-of-the-box observability features for Knative Services. You can view the Knative dashboard on the Monitoring Dashboards tab of the Knative page. For more information about the Knative dashboard, see View the Knative dashboard in Managed Service for Prometheus.
References
Alibaba Cloud Knative implements a Kubernetes-based serverless framework by integrating the creation of containers (or functions), workload management (auto scaling), and event models. For more information about Alibaba Cloud Knative, see Knative overview.
For more information about the features of Alibaba Cloud Knative, see Comparison between Alibaba Cloud Knative and open source Knative.