This topic describes the architecture, resource model, and node-level Quality of Service (QoS) used to help you colocate latency-sensitive (LS) and best-effort (BE) workloads.
Background information
From the cluster perspective, colocation refers to deploying different types of workloads in the same cluster, and analyzing the characteristics of the workloads and predicting resource demand spikes to improve the utilization of cluster resources. From the node perspective, colocation refers to deploying multiple containers on the same node. These containers are used for different types of workloads, including LS workloads and BE workloads. Workloads can be classified into LS workloads and BE workloads based on their Service Level Objectives (SLOs). LS workloads usually have queries per second (QPS) or response time (RT) objectives and are assigned a high-priority QoS class. Most BE workloads are compute-intensive workloads with high fault tolerance. These workloads are usually assigned a low-priority QoS class.
The following section describes the focus of different roles throughout the colocation process:
Cluster resource administrator: wants to simplify cluster resource management and monitor the resource limits, resource allocation, and resource usage of each workload to improve the utilization of cluster resources and reduce IT costs.
LS workload administrator: focuses on the interference among containers of different workload types because colocation can easily cause resource contention. The workloads may respond with a 90th percentile latency or 99th percentile latency. This indicates that a specific number of requests are processed with a latency much higher than the average. As a result, the service quality is downgraded.
BE workload administrator: wants to use classified and reliable resource overcommitment to meet the SLOs of different workloads.
Container Service for Kubernetes (ACK) uses the following mechanisms to meet the preceding requirements in colocation scenarios:
Provides a QoS model for colocation and allows you to set resource priorities.
Provides stable and reliable resource overcommitment.
Supports fine-grained orchestration and isolation of Kubernetes resources.
Provides enhanced workload scheduling capabilities.
Architecture
ACK uses the ack-koordinator component to meet the SLOs of different workloads colocated in the same cluster. ack-koordinator consists of an SLO controller and an SLO agent. The SLO controller is a standard Kubernetes extension. The SLO controller is deployed by using a Deployment and the SLO agent is deployed by using a DaemonSet. The SLO agent supports all capabilities of the kubelet and provides various colocation capabilities.

The preceding figure shows the colocation architecture. The SLO-aware colocation solution of ACK defines multiple protocols. These protocols allow ACK to record the metrics of nodes, configurations of QoS policies, and enforcement of QoS policies by using custom resource definitions (CRDs), and record the amount of resources available for dynamic overcommitment by using standard extended resources. The components in the figure provide the following features:
SLO controller: monitors the loads of each node, and overcommits resources and guarantees SLOs based on resource profiles.
Recommender: provides the resource profiling feature and estimates the peak resource demand of workloads. Recommender simplifies the configuration of resource requests and limits for containers.
Koordlet: monitors the loads of each node, detects anomalies, dynamically isolates resources, and suppresses interference in a closed loop.
ACK scheduler: optimizes SLO-aware colocation. For example, the ACK scheduler can spread pods when resources are dynamically overcommitted.
Koordinator Descheduler: deployed as a Deployment and is used for rescheduling.

Resource model
The resource management mechanism used by Kubernetes requires containers to apply for resources based on resource requests and limits. To prevent resource contention, administrators usually set the resource requests and limits of containers to larger values for LS workloads. As a result, a large amount of resources is requested but the actual resource utilization is still low.
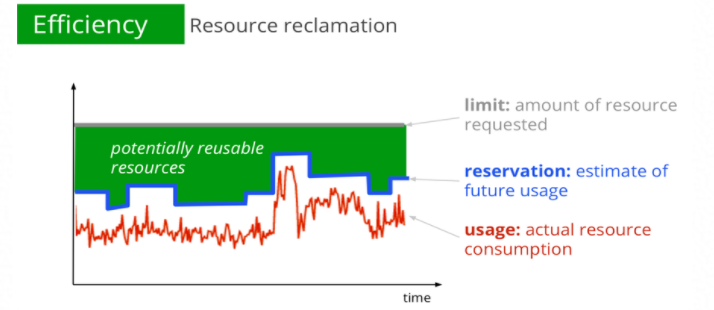
The green block in the following figure indicates the amount of resources that can be dynamically overcommitted. The resources are allocated to BE workloads to ensure that different workloads can meet their SLOs and improve the overall resource utilization.

ack-koordinator can quantify resources that can be dynamically overcommitted, calculate the amount of reclaimed resources in real time, and synchronize the information as standard extended resources to the Kubernetes node metadata.
The following sample code provides an example of the YAML template of the node:
status:
allocatable:
# milli-core
kubernetes.io/batch-cpu: 50000
# bytes
kubernetes.io/batch-memory: 50000
capacity:
kubernetes.io/batch-cpu: 50000
kubernetes.io/batch-memory: 100000The priority of BE pods is lower than that of LS pods. To configure a BE pod to use reclaimed resources, you need to only add the qos and batch fields to the YAML template of the BE pod. qos: LS indicates the high priority and qos: BE indicates the low priority. batch-cpu and batch-memory indicate the amount of resources requested by the pod. For more information, see Enable dynamic resource overcommitment.
The following sample code provides an example of the YAML template of the BE pod:
metadata:
labels:
koordinator.sh/qosClass: "BE" # Set the QoS class to BE or LS.
spec:
containers:
- resources:
limits:
kubernetes.io/batch-cpu: 1000
kubernetes.io/batch-memory: 2048
requests:
kubernetes.io/batch-cpu: 1000
kubernetes.io/batch-memory: 2048Node-level QoS
CPU QoS
To reserve CPU resources for LS pods and prevent BE pods from competing for resources, you can use the CPU QoS feature provided by the ack-koordinator component. The CPU QoS feature is based on Alibaba Cloud Linux. The ack-koordinator component allows you to use the group identity feature to configure Linux scheduling priorities for pods. In an environment in which LS pods and BE pods are colocated, you can set the priority of LS pods to high and the priority of BE pods to low to prevent resource contention. The LS pods are prioritized to use the limited CPU resources. This ensures the service quality of the LS workloads.
The following benefits are available after you enable the CPU QoS feature:
The wake-up latency of tasks for LS workloads is minimized.
Waking up tasks for BE workloads does not adversely affect the performance of LS pods.
Tasks for BE workloads cannot use the simultaneous multithreading (SMT) scheduler to share CPU cores. This further reduces the impact on the performance of LS pods.
CPU Suppress
In the resource model of colocation, the total amount of resources that can be dynamically overcommitted varies based on the resource usage of LS pods. The resources can be allocated to BE pods. To ensure sufficient CPU resources for the LS pods on a node, you can use the CPU Suppress feature of ack-koordinator to limit the resource usage of the BE pods on the node. The CPU Suppress feature can limit the amount of CPU resources that can be used by BE pods when the overall resource usage of the node is below the threshold. This ensures that the containers on the node have sufficient resources to stably run.
In the following figure, CPU Threshold indicates the CPU usage threshold of a node. Pod (LS).Usage indicates the CPU usage of LS pods. CPU Restriction for BE indicates the CPU usage of BE pods. The amount of CPU resources that can be used by BE pods is adjusted based on the fluctuation of the CPU usage of LS pods. This allows BE pods to exploit idle resources and improves the throughput of BE workloads. This also prevents BE pods from competing for resources when the loads of LS workloads increase.

CPU Burst
Kubernetes allows you to use resource limits to manage Kubernetes resources. You can set a CPU limit to allow the OS kernel to limit the amount of CPU resources that can be used by a container within a time period. For example, you can specify CPU Limit=2. The OS kernel limits the CPU time slices that the container can use to 200 milliseconds within each 100-millisecond period.
The following figure shows the thread allocation of a web application container that runs on a node with four vCores. The CPU limit of the container is set to 2. The overall CPU utilization within the last second is low. However, Thread 2 cannot be resumed until the third 100-millisecond period starts because CPU throttling is enforced somewhere in the second 100-millisecond period. This increases the response time (RT) and causes long-tail latency issues in containers.
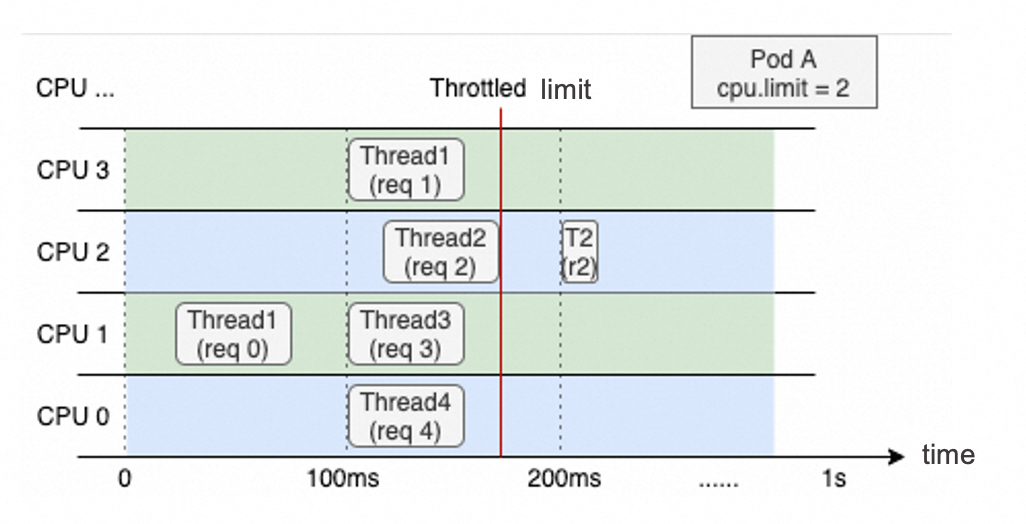
The CPU Burst feature can efficiently resolve the long-tail latency issue in LS workloads. This feature allows containers to collect CPU time slices when the containers are idle. These CPU time slices can be used to handle resource demand spikes and improve the performance of containers. ACK allows you to use all kernel versions that support CPU Burst. For kernel versions that do not support CPU Burst, ACK monitors CPU throttling and dynamically adjusts the CPU limits of containers to optimize container performance in a similar manner as CPU Burst.

Memory QoS
The following memory limits apply to containers:
The memory limit of the container. If the amount of memory that a container uses, including the memory used by the page cache, is about to reach the memory limit of the container, the memory reclaim mechanism of the OS kernel is triggered. As a result, the application in the container may not be able to request or release memory resources as expected.
The memory limit of the node. If the memory limit of a container is greater than the memory request of the container, the container can overcommit memory resources. In this case, the available memory on the node may become insufficient. This causes the OS kernel to reclaim memory from containers. In extreme cases such as colocation, the performance of your application is greatly downgraded.
To improve the performance of runtimes and the stability of nodes, ack-koordinator works together with Alibaba Cloud Linux to enable the memory QoS feature for pods. ack-koordinator automatically configures the memcg based on the container configuration, and allows you to enable the memcg QoS feature, the memcg backend asynchronous reclaim feature, and the global minimum watermark rating feature for containers. This optimizes the performance of memory-sensitive applications while ensuring fair memory scheduling among containers.
Memory QoS provides the following features:
If the memory used by a pod is about to reach the memory limit of the pod, the memcg asynchronously reclaims a specific amount of memory. This prevents the system from reclaiming all the memory used by the pod and therefore minimizes the adverse impact on the application performance caused by directly reclaiming memory resources.
Memory can be reclaimed more fairly from pods. When the node does not have sufficient memory resources, memory is reclaimed from pods whose memory usage is greater than memory request. This helps prevent performance degradation caused by pods that overcommit memory resources.
The memory requests of LS pods are prioritized. This way, LS pods are less likely to trigger the memcg to reclaim all memory resources on the node, The following figure shows an example.

memory.limit_in_bytes: the upper limit of memory that can be used by a pod.
memory.high: the memory throttling threshold.
memory.wmark_high: the memory reclaim threshold.
memory.min: the memory lock threshold.
Resource isolation based on the L3 cache and MBA
When the containers of different workloads are colocated on a node, the containers share the L3 cache (last-level cache) of the node. The memory bandwidth distributed across these workloads is controlled by Memory Bandwidth Allocation (MBA). ECS bare metal instances provide the last-level cache (LLC) feature to dynamically adjust the CPU cache that can be used by pods and the MBA feature to control the distribution of memory bandwidth. In addition, ack-koordinator limits the resources used by BE pods in a fine-grained manner to ensure the performance of LS pods.
What to do next
You can refer to Getting started and use ack-koordinator to build an environment in which LS and BE workloads are colocated. For more information about the features of colocation see the following topics: