If your cluster is large or requires fast resource delivery, node autoscaling may not meet your needs. Use the Node Instant Elasticity feature to improve resource elasticity and reduce O&M costs.
Before you begin
Before you use the Node Instant Elasticity feature, read Node scaling and make sure that you understand the following concepts:
How Node Instant Elasticity works
The benefits of Node Instant Elasticity and its applicable business scenarios
Precautions for using Node Instant Elasticity
During a scale-in, subscription instances are removed from the cluster but are not released. To avoid incurring unnecessary costs, we recommend that you use pay-as-you-go instances when you enable this feature.
Usage notes
This feature is available only for ACK managed clusters and ACK dedicated clusters that run Kubernetes version 1.24 or later. To upgrade a cluster, see Manually upgrade a cluster.
Make sure that the Auto Scaling service is activated.
Ensure that the vSwitches configured for the node pool where Node Instant Elasticity is enabled have a sufficient number of available IP addresses to prevent node creation failures. You can call the DescribeVSwitchAttributes operation to query the number of available IP addresses for a vSwitch.
If the number of available IP addresses is insufficient, see Use a secondary CIDR block to add CIDR blocks to a cluster.
If automatic scaling is enabled for a node pool and the Scaling Mode of the node pool is set to Standard, Node Instant Elasticity is compatible with the semantics and behavior of the original elastic node pool. You can seamlessly enable and use this feature for all types of applications. However, Node Instant Elasticity is not compatible with node pools whose Scaling Mode is set to Swift.
If the version of the Node Instant Elasticity component is earlier than v0.5.3, you must manually delete offline nodes. For more information, see FAQ.
The process involves the following steps:
Step 1: Enable Node Instant Elasticity: You must first enable node autoscaling for the cluster before the automatic scaling policy of the node pool can take effect.
Step 2: Configure a node pool for automatic scaling: The node autoscaling feature works only for node pools that are configured for automatic scaling. Therefore, you must also set the scaling mode of the specified node pool to automatic.
Step 1: Enable the Node Instant Elasticity feature
Before you can use the Node Instant Elasticity feature, you must enable and configure automatic cluster scaling on the node pool page to allow nodes to be scaled.
Log on to the ACK console. In the left navigation pane, click Clusters.
On the Clusters page, find the cluster to manage and click its name. In the left navigation pane, choose .
On the Node Pools page, click Enable next to Node Scaling.
If this is the first time you use the automatic cluster scaling feature, follow the on-screen instructions to activate the Auto Scaling service and grant the required permissions. If you have activated the service and granted the permissions, skip this step.
ACK managed clusters: Grant permissions to the AliyunCSManagedAutoScalerRole role.
ACK dedicated clusters: Grant permissions to the KubernetesWorkerRole role and the AliyunCSManagedAutoScalerRolePolicy system policy. The following figure shows the entries.
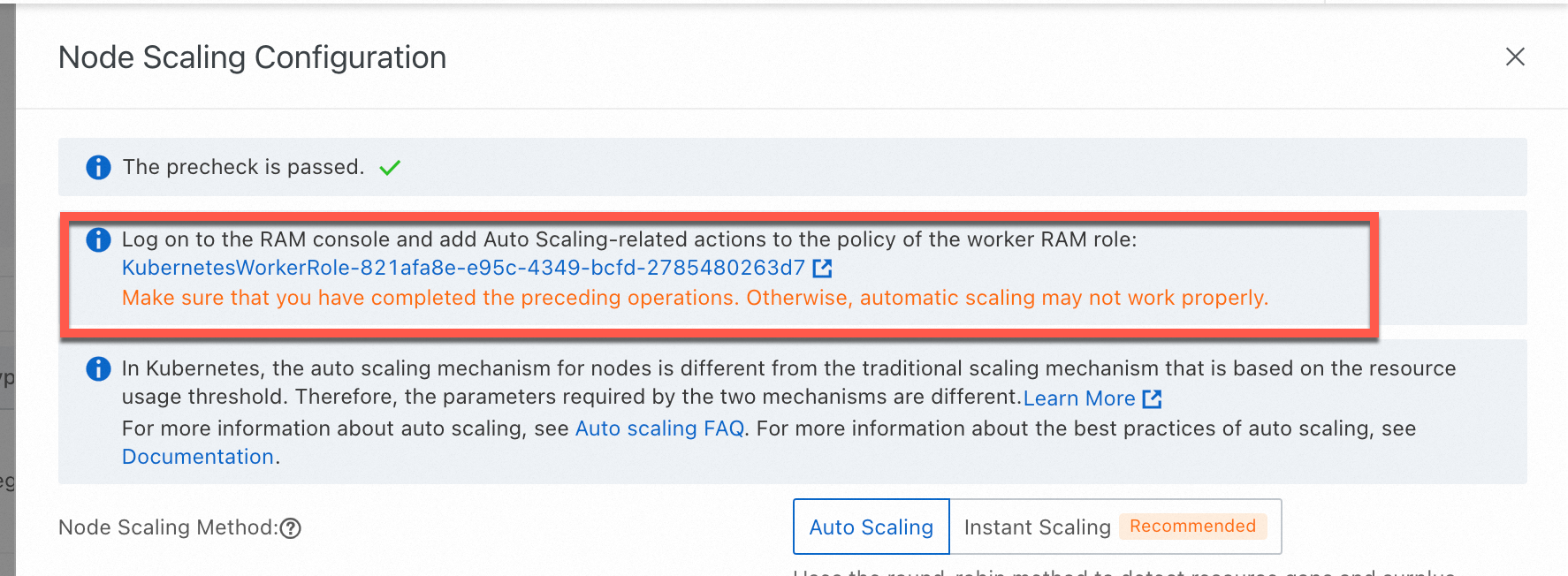
On the Node Scaling Configuration page, set Node Scaling Method to Instant Scaling, configure the scaling parameters, and then click OK.
When elastic scaling is performed, the scaling component automatically triggers a scale-out based on the scheduling status.
You can switch the node scaling solution after it is selected. To switch the solution, you can change it to Node Autoscaling. Carefully read the on-screen messages and follow the instructions. This feature is available only to users on the whitelist. To use this feature, submit a ticket.
Configuration item
Description
Scale-in Threshold
The ratio of the requested resources of a single node to the resource capacity of the node in a node pool for which node autoscaling is enabled.
A node can be scaled in only when the ratio is lower than the configured threshold. This means the CPU and memory resource utilization of the node is lower than the Scale-in Threshold.
GPU Scale-in Threshold
The scale-in threshold for GPU-accelerated instances.
A GPU-accelerated node can be scaled in only when the ratio is lower than the configured threshold. This means the CPU, memory, and GPU resource utilization of the node is lower than the GPU Scale-in Threshold.
Defer Scale-in For
The interval between when a scale-in is required and when the scale-in is performed. Unit: minutes. Default value: 10 minutes.
ImportantThe scaling component can perform a scale-in only after the conditions specified by Scale-in Threshold and Defer Scale-in For are met.
Step 2: Configure a node pool for automatic scaling
Node Instant Elasticity scales nodes only in node pools for which automatic scaling is enabled. Therefore, after you configure Node Instant Elasticity, you must also configure at least one node pool for automatic scaling.
Create a node pool and enable automatic scaling for it. For more information, see Create a node pool.
Configure an existing node pool to enable automatic scaling. For more information, see Edit a node pool.
Expand the range of available instance types for the node pool. For example, you can configure multiple instance types, specify instance attributes, or configure multiple zones for the node pool. This helps ensure a sufficient inventory of instance types and successful scaling activities.
(Optional) Step 3: Verify the result
After you complete the preceding steps, the Node Instant Elasticity feature is enabled. The node pool shows that automatic scaling is enabled, and the Node Instant Elasticity component is automatically installed in the cluster.
Automatic scaling is enabled for the node pool
On the Node Pools page, the node pool list shows the node pools for which automatic scaling is enabled.
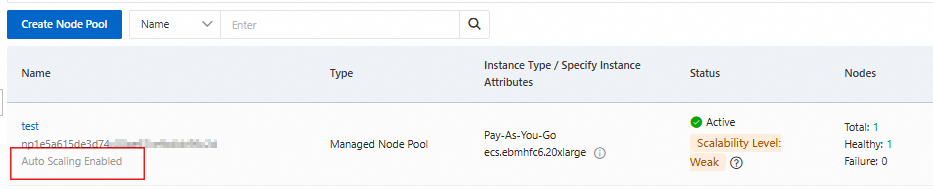
The Node Instant Elasticity component is installed
On the Clusters page, find the one you want to manage and click its name. In the left navigation pane, click Add-ons.
On the Add-ons page, find the ACK GOATScaler component. The status of the component is Installed.
Key events of Node Instant Elasticity
Node Instant Elasticity involves the following key events. You can view these events to check the internal status when Node Instant Elasticity is triggered.
Event Name | Event Object | Description |
ProvisionNode | pod | Node Instant Elasticity successfully triggers a node scale-out. |
ProvisionNodeFailed | pod | Node Instant Elasticity fails to trigger a node scale-out. |
ResetPod | pod | Node Instant Elasticity re-adds pods that meet the conditions, have triggered a scale-out, but are still unschedulable to the scope where scale-outs can be triggered. |
InstanceInventoryStatusChanged | ACKNodePool | The supply status of an instance type in a zone changes. The format is For more information, see View the health status of Node Instant Elasticity. |
Identifiers of Node Instant Elasticity
Node Instant Elasticity maintains the following identifiers. Do not manually modify them. Otherwise, exceptions may occur.
Node Label
node label | Description |
goatscaler.io/managed:true | Identifies nodes that are managed by Node Instant Elasticity. For nodes with this label, Node Instant Elasticity periodically checks whether the scale-in conditions are met. |
k8s.aliyun.com: true | Identifies nodes that are managed by Node Instant Elasticity. For nodes with this label, Node Instant Elasticity periodically checks whether the scale-in conditions are met. |
goatscaler.io/provision-task-id:{task-id} | Identifies the task ID of the task that is used by Node Instant Elasticity to scale out nodes. This lets you trace the trigger source for node creation. |
Node Taint
Node Taint | Description |
goatscaler.io/node-terminating | Nodes with this taint are scaled in by Node Instant Elasticity. |
Pod Annotation
Pod Annotation | Description |
goatscaler.io/provision-task-id | Identifies the task ID of the node that is scaled out by Node Instant Elasticity for this pod. For pods with this annotation, Node Instant Elasticity waits for the node to start and does not repeatedly trigger scale-outs. |
goatscaler.io/reschedule-deadline | Identifies the period of time that Node Instant Elasticity waits for a pod to be scheduled to a node. If the pod is still unschedulable after this period, Node Instant Elasticity re-adds the pod to the scope where scale-outs can be triggered. |
FAQ
Category | Subcategory | Issue |
Scaling behavior of node instant scaling | ||
Custom scaling behavior | How does node instant scaling use pods to control node scale-in activities? | |
Related operations
View the health status of Node Instant Elasticity
The node instant scaling feature dynamically selects instance types and zones based on the inventory of Elastic Compute Service (ECS) instances. To monitor the inventory health of instance types, obtain optimization suggestions for the node pool's instance configuration, and ensure that node scaling activities succeed, check the node pool's inventory health ConfigMap. This lets you assess whether the current node pool inventory is healthy and adjust the instance type configuration in advance.
For more information, see View the health status of Node Instant Elasticity.
Enable log collection for Node Instant Elasticity
If you use an ACK managed cluster, you can collect the component logs for Node Instant Elasticity on the Control Plane Component Logs page.
Log on to the ACK console. In the left navigation pane, click Clusters.
On the Clusters page, find the cluster you want and click its name. In the left-side pane, choose .
Click the Control Plane Component Logs tab, click Update Component in the upper-right corner, and then select the Node Instant Elasticity component as prompted.

Wait for the component to be updated. After the update is complete, you can select the Node Instant Elasticity component from the component drop-down list to view its logs.

Upgrading node instant elasticity components
Upgrade the Node Instant Elasticity component in a timely manner to use its latest features and optimizations. For more information, see Manage components.
Skip inventory check when you use a private pool to supply resources
If you use a private pool to ensure resource inventory, you must enable SkipInventoryCheck. This allows the Node Instant Elasticity component to skip the inventory check for resources that are not in the private pool during a scale-out and directly use the reserved resources in the private pool.
On the Clusters page, find the one you want to manage and click its name. In the left navigation pane, click Add-ons.
In the Core Components section, find the ACK GOATScaler component and click Configuration on the component card.
SkipInventoryCheck is supported only by component versions v0.3.0-582e405-aliyun and later. If the component version does not meet the requirement, upgrade the component first.
Follow the on-screen instructions to set SkipInventoryCheck to true.