ApsaraDB RDS for SQL Server provides incremental backup data migration to the cloud. You can store full backup files from a self-managed SQL Server instance in an Object Storage Service (OSS) bucket and restore them to your ApsaraDB RDS for SQL Server instance through the ApsaraDB RDS console. Then, you can import differential backup files or log backup files to implement incremental backup data migration to the cloud. This migration method reduces downtime to minutes.
Scenarios
The migration method in this topic is suitable for the following scenarios:
Migrate data to your RDS instance in physical mode rather than logical mode.
NotePhysical migration lets you migrate data using a physical backup file. Logical migration lets you write executed data manipulation language (DML) statements to your RDS instance.
Physical migration ensures 100% data consistency between the self-managed database and the destination database. Logical migration cannot ensure 100% data consistency. For example, index fragmentation and statistical information may change after migration.
Migrate data with minute-level downtime.
NoteIf your application is not sensitive to downtime (for example, it can tolerate a downtime of 2 hours) and the database is smaller than 100 GB, we recommend that you use full backup files for cloud migration.
Prerequisites
Your RDS instance meets the following requirements:
The RDS instance runs SQL Server 2012 or later, or SQL Server 2008 R2 with cloud disks.
The names of existing databases on your RDS instance are different from the name of the source database on the self-managed SQL Server instance.
The available storage of the RDS instance is greater than the size of the data files you want to migrate. If the available storage is insufficient, you must expand the storage capacity of the RDS instance before starting the migration.
The self-managed SQL Server instance uses the
FULLrecovery model.NoteTransaction log backups are required when migrating incremental backup data from a self-managed SQL Server instance to an RDS instance. If the self-managed SQL Server instance uses the SIMPLE recovery model, transaction logs cannot be backed up.
If the size of differential backup files is large, the time required to migrate the incremental backup data may increase.
If you use a Resource Access Management (RAM) user, the following conditions must be met:
The RAM user has the AliyunOSSFullAccess and AliyunRDSFullAccess permissions. For more information about how to grant permissions to a RAM user, see Manage OSS permissions using RAM and Manage ApsaraDB RDS permissions using RAM.
Your Alibaba Cloud account has granted the ApsaraDB RDS service account permissions to access your OSS resources.
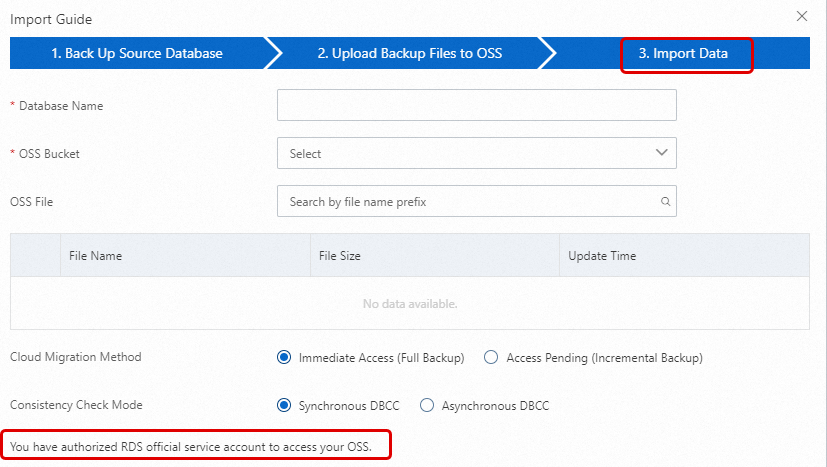
Go to the Backup and Restoration page of the ApsaraDB RDS instance and click Migrate OSS Backup Data to RDS.
In the Import Guide, click Next twice to proceed to step 3. Import Data.
The authorization is complete if the message You have authorized RDS official service account to access your OSS is displayed in the lower-left corner of the page. If not, click the Authorization URL on the page to grant authorization.
Your Alibaba Cloud account must manually create an access policy and then attach the policy to the RAM user.
Preparations
Execute the DBCC CHECKDB statement on the self-managed database and verify that no allocation errors or consistency errors occur. If no allocation errors or consistency errors occur, the following execution result is returned:
...
CHECKDB found 0 allocation errors and 0 consistency errors in database 'xxx'.
DBCC execution completed. If DBCC printed error messages, contact your system administrator.Usage notes
Migration level: The migration method in this topic supports the migration of only a single database. If you want to migrate multiple or all databases, see Migrate data from a self-managed SQL Server instance to an ApsaraDB RDS for SQL Server instance.
Version compatibility: Migration from a later SQL Server version to an earlier SQL Server version is not supported.
Permission management: After you authorize the service account of ApsaraDB RDS to access the OSS bucket, a role named
AliyunRDSImportRoleis created in Resource Access Management (RAM). Do not modify or delete this role. Otherwise, the migration fails. If you modify or delete this role, you must re-authorize the service account using the migration wizard.Account management: After the migration is complete, you cannot use the accounts of the self-managed SQL Server instance. You must create accounts for the RDS instance in the ApsaraDB RDS console.
OSS file retention: Before the migration is complete, do not delete the backup files from the OSS bucket. Otherwise, the migration fails.
Backup file requirements:
Filename restrictions: The names of the backup files cannot contain special characters (such as
!@#$%^&*()_+-=). Otherwise, the migration fails.File suffixes: The names of backup files must be suffixed with
.bak(full backup files),.diff(differential backup files),.trn, or.log(log backup files). The system cannot identify other file types.NoteIn actual business scenarios, a backup file may be stored in a different format. For example, a file suffixed with
.bakcan be a full backup file, a differential backup file, or a log backup file.If the backup file is a log backup file of the self-managed SQL Server instance and downloaded in the ApsaraDB RDS console (instead of a
.bakbackup file generated by the official script in Step 1 of this topic), the default format of the downloaded backup file is.zip.log. The downloaded backup file can be used for cloud migration after you convert the file format.Processing method: Change the extension of the file to
.zipfor decompression, rename the decompresseddatabase_name.lbakfile to a file suffixed with.bak, and then upload the.bakfile to an OSS bucket as an incremental log backup file for cloud migration.
Operation flow examples
Migration phase | Step | Description |
Full Data Migration Stage | Step1. Before 00:00 | Complete the following preparations:
|
Step2. 00:01 | Perform a full backup on the source database. Time required: about 1 hour. | |
Step3. 02:00 | Upload the full backup file to the OSS bucket. Time required: about 1 hour. | |
Step4. 03:00 | Restore data from the full backup file to your RDS instance in the ApsaraDB RDS console. Time required: about 19 hours. | |
Incremental Phase | Step5. 22:00 | Perform a log backup on the source database. Time required: about 20 minutes. |
Step6. 22:20 | Upload the log backup file to the OSS bucket. Time required: about 10 minutes. | |
Step6. 22:30 |
| |
Database opening | Step8. 22:34 | The incremental upload of the last LOG backup file to the cloud is complete, which took 4 minutes. Now starting to bring the database online. |
Step9. 22:35 | Open the destination database on your RDS instance. If you execute the DBCC statement in asynchronous mode, the destination database can be opened in 1 minute. |
The preceding migration provides an example of how to minimize downtime. Your application can continue to run, and you do not need to stop your application until the last log backup. In this example, the downtime of your application does not exceed 5 minutes.
1. Back up the source database
Download the backup script, and open it using SQL Server Management Studio (SSMS).
Configure the following parameters:
Parameter
Description
@backup_databases_list
The name of the source database that you want to back up. If you specify multiple databases, separate the names of these databases with semicolons (;) or commas (,).
@backup_type
The type of the backup. Valid values:
FULL: full backup
DIFF: differential backup
LOG: log backup
@backup_folder
The directory that is used to store backup files on the self-managed database. If the specified directory does not exist, the system automatically creates one.
@is_run
Specifies whether to perform a backup or a check. Valid values:
1: performs a backup.
0: performs a check only.
Execute the backup script.
After execution, a
.bakfile is automatically generated regardless of the backup type you specified.
2. Upload backup files to OSS
Before uploading backup files to OSS, you need to create a bucket in OSS.
If a bucket already exists in OSS, make sure that the bucket meets the following requirements:
The storage class of the bucket is Standard. The storage class cannot be Standard, Infrequent Access (IA), Archive, Cold Archive, or Deep Cold Archive.
Data encryption is not enabled for the bucket.
If no bucket exists in OSS, you need to create one. (Make sure that you have activated OSS)
Log on to the OSS console, click Buckets, and then click Create Bucket.
Configure the following parameters. Retain the default values for other parameters.
ImportantThe bucket is primarily used for this data migration, you only need to configure the key parameters. After the migration is complete, you can delete the bucket to prevent data breaches and avoid related costs.
Do not enable data encryption when creating the bucket.
Parameter
Description
Example
Bucket Name
The name of the OSS bucket. The name is globally unique and cannot be modified after it is configured.
Naming rules:
The name can contain only lowercase letters, digits, and hyphens (-).
The name must start and end with a lowercase letter or digit.
The name must be 3 to 63 characters in length.
migratetest
Region
The region of the OSS bucket. If you want to upload data to the OSS bucket from an Elastic Compute Service (ECS) instance over an internal network and then restore the data to the RDS instance over the internal network, make sure that the OSS bucket, ECS instance, and RDS instance reside in the same region.
China (Hangzhou)
Storage Class
Select Standard. The cloud migration operations described in this topic cannot be performed in buckets of other storage classes.
Standard
Upload backup files to the OSS bucket.
After the self-managed database is backed up, upload the backup files to an OSS bucket that resides in the same region as your RDS instance. If the OSS bucket and the RDS instance reside in the same region, they can communicate with each other over an internal network. This prevents the generation of Internet traffic fees and accelerates data uploads. You can use one of the following methods:
Download ossbrowser.
For example, if your operating system is Windows x64, decompress the downloaded
oss-browser-win32-x64.zippackage, and double-click theoss-browser.exeapplication.Use AK as the logon method, configure the AccessKeyId and AccessKeySecret parameters, retain the default values of other parameters, and then click Log On.
NoteAn AccessKey is used for identity verification to ensure data security. Keep your AccessKey secure.

Click the target bucket to go to the storage space.

Click
 , select the backup file you want to upload, and then click Open to upload the local file to OSS.
, select the backup file you want to upload, and then click Open to upload the local file to OSS.
NoteIf the size of the backup file is less than 5 GB, we recommend that you upload the backup file in the OSS console.
Log on to the OSS console.
Click Buckets, and then click the name of the target bucket.
In the Objects section, click Upload Object.
You can drag and drop the backup file to the Files to Upload section, or click Select Files to select the backup file you want to upload.
Click Upload Object at the bottom of the page to upload the local backup file to OSS.
3. Create a cloud migration task
Go to the Instances page. In the top navigation bar, select the region in which the RDS instance resides. Then, find the RDS instance and click the ID of the instance.
In the navigation pane on the left, click Backup And Restoration.
Click Migrate OSS Backup Data to RDS at the top of the page.
In the Import Guide wizard, click Next twice to import data.
NoteIf this is the first time you use the OSS-based migration wizard, you must authorize the account of ApsaraDB RDS to access the OSS bucket. In this case, you must click Authorization and complete the authorization. Otherwise, the OSS Bucket drop-down list in the Import Data step is empty.
Configure the following parameters and click OK.
Wait until the migration task is complete. You can click Refresh to view the most recent status of the migration task. If the migration task fails, troubleshoot the issue based on the error message. For more information, see Common errors in this topic.
Parameter
Description
Database Name
Enter the name of the destination database on your RDS instance. The destination database is used to store the data that is migrated from the source database on the self-managed SQL Server instance. The name of the destination database must meet the requirements of open source SQL Server.
ImportantBefore migration, you must make sure that the names of the databases on the destination RDS instance are different from the name of the database that you want to restore using the specified backup file. In addition, make sure that database files with the same name as the database that you want to restore using the specified backup file are not added to the databases on the destination RDS instance. If both preceding requirements are met, you can restore the database using a database file in the backup set. Note that the database file must have the same name as the database that you want to restore.
If a database with the same name as the database specified in the backup file already exists on the destination instance, or if there are unattached database files with the same name, the restoration operation will fail.
OSS Bucket
Select the OSS bucket that stores the full backup file.
OSS File
Click the magnifying glass button on the right to search for backup files using fuzzy matching based on the prefix of the backup filename. The system displays the name, size, and update time of each backup file. Select the backup file that you want to migrate to the cloud.
Cloud Migration Method
Select Access Pending (Incremental Backup).
Immediate Access (Full Backup): This method is suitable for full data migration to the cloud. If you want to migrate only a full backup file, select this migration method. In this case, the following parameter settings take effect in the CreateMigrateTask operation:
BackupMode = FULLandIsOnlineDB = True.Access Pending (Incremental Backup): This method is suitable for incremental data migration to the cloud. If you want to migrate a full backup file and a log or differential backup file, select this migration method. In this case, the following parameter setting takes effect in the CreateMigrateTask operation:
BackupMode = UPDFandIsOnlineDB = False.
4. Import the log or differential backup file
After the full backup file of the source database on the self-managed SQL Server instance is imported into the destination database on your RDS instance, you must import the log or differential backup file.
Go to the Instances page. In the top navigation bar, select the region in which the RDS instance resides. Then, find the RDS instance and click the ID of the instance.
In the navigation pane on the left, click Backup And Restoration. On the page that appears, click the Cloud Migration Records Of Backup Data tab.
Find the destination database and click Upload Incremental Files in the Task Actions column. Select the incremental file and click OK.
NoteIf you have multiple log backup files, you must use the same method to upload the log backup files one by one.
Make sure that the size of the last log or differential backup file does not exceed 500 MB. This minimizes the time required to complete the migration.
Before the last log or differential backup file is generated, you must stop data writes to the self-managed database. This ensures data consistency between the self-managed database and the destination database on your RDS instance.
5. Open the database
After you import all the backup files into the destination database on your RDS instance, the destination database is in the In Recovery or Restoring state. If your RDS instance runs RDS High-availability Edition, the destination database is in the In Recovery state. If your RDS instance runs RDS Basic Edition, the destination database is in the Restoring state. In these cases, you cannot perform read or write operations on the destination database. Before you can perform read and write operations, you must open the destination database.
Go to the Instances page. In the top navigation bar, select the region in which the RDS instance resides. Then, find the RDS instance and click the ID of the instance.
In the navigation pane on the left, click Backup And Restoration. On the page that appears, click the Cloud Migration Records Of Backup Data tab.
Find the destination database and click Open Database in the Task Actions column.
Select a consistency check mode and click OK.
NoteApsaraDB RDS provides the following consistency check modes:
Asynchronous DBCC: The DBCC CHECKDB statement is executed after the destination database is opened. This reduces the time required to open the destination database and minimizes the downtime of your application. If the destination database is large, a long period of time is required to execute the DBCC CHECKDB statement. If your application is sensitive to downtime but is not sensitive to the result of the DBCC CHECKDB statement, we recommend that you select this consistency check mode. In this case, the following parameter setting takes effect in the CreateMigrateTask operation:
CheckDBMode = AsyncExecuteDBCheck.Synchronous DBCC: The DBCC CHECKDB statement is executed at the same time when the destination database is opened. If you want to identify consistency errors between the self-managed database and the destination database based on the result of the DBCC CHECKDB statement, we recommend that you select this consistency check mode. However, the time required to open the destination database increases. In this case, the following parameter setting takes effect in the CreateMigrateTask operation:
CheckDBMode = SyncExecuteDBCheck.
6. View details of the imported backup files
Go to the Backup And Restoration page from the navigation pane on the left of the RDS instance. On the page that appears, click the Cloud Migration Records Of Backup Data tab to view the backup migration records. Click View File Details in the Task Actions column of the corresponding task to view the details of all backup files associated with that task.
After the cloud migration is complete, the system backs up the data based on the backup time specified in the automatic backup policy of the RDS instance. The generated backup set includes the data migrated to the cloud. You can view the details on the Backup And Restoration page of the RDS instance. You can manually adjust the backup time.
If the specified backup time does not arrive but you require a backup file in the cloud, you can trigger a manual backup.
Common errors
For more information about the common errors that may occur during the migration of full backup data, see Common errors in the topic about migrating full backup data.
During the migration of incremental backup data, you may encounter the following errors:
The destination database cannot be opened
Error message: Failed to open database xxx.
Cause: Some advanced features are enabled for the self-managed SQL Server instance. However, these advanced features are not supported by your RDS instance. For example, the self-managed SQL Server instance runs an Enterprise Edition of SQL Server and your RDS instance runs a Web edition of SQL Server. If the data compression and partition features are enabled for the self-managed SQL Server instance, this error is reported when you open the destination database on the RDS instance.
Solution:
Disable the advanced features for the self-managed SQL Server instance, back up data again, and then migrate the data using OSS.
Purchase an RDS instance that runs the same SQL Server edition as the self-managed SQL Server instance. For more information about how to purchase, see Create and use an ApsaraDB RDS for SQL Server instance.
NoteFor more information, see Features of ApsaraDB RDS instances that run different SQL Server versions and RDS editions.
The log sequence numbers (LSNs) in the backup chain are not consecutive
Error message: The log in this backup set begins at LSN XXX, which is too recent to apply to the database.RESTORE LOG is terminating abnormally.
Cause: The LSNs in the log or differential backup file are different from the LSNs in the previous backup file that is used for the restoration.
Solution: Select the corresponding LSN backup file to upload the incremental backup file. You can perform the incremental uploads in chronological order based on the time of each backup operation.
The DBCC CHECKDB statement cannot be executed in asynchronous mode
Error message: asynchronously DBCC checkdb failed: CHECKDB found 0 allocation errors and 2 consistency errors in table 'XXX' (object ID XXX).
Cause: After data is restored to your RDS instance with the Asynchronous DBCC consistency check mode selected, ApsaraDB RDS executes the DBCC CHECKDB statement. If the destination database fails the consistency check, consistency errors occur in the self-managed database.
Solution:
Execute the following statement on the destination database:
DBCC CHECKDB (DBName,REPAIR_ALLOW_DATA_LOSS)ImportantIf you execute this statement to fix the error, your data may be lost.
Execute the following statement on the self-managed database to fix the error and then migrate data again:
DBCC CHECKDB (DBName,REPAIR_ALLOW_DATA_LOSS)
The selected backup file is a full backup file
Error message: Backup set (xxx) is a Database FULL backup, we only accept transaction log or differential backup.
Cause: After the data is restored to your RDS instance using a full backup file, you can select only a log or differential backup file. If you select a full backup file again, this error is reported.
Solution: Select a log or differential backup file.
The number of specified source databases exceeds the upper limit
Error message: The database (xxx) migration failed due to databases count limitation.
Cause: If the number of specified source databases exceeds the upper limit, this error is reported.
Solution: Migrate the data of source databases to another RDS instance. Otherwise, delete unnecessary databases.
The RAM user does not have the required permissions
Q1: When you perform Step 5 of Create a cloud migration task, all parameter values are correctly configured, but the OK button is dimmed?
A1: The button may be dimmed because you are using a RAM user that does not have the required permissions. See the Prerequisites section of this topic to make sure that the required permissions are granted.
Q2: How do I resolve the
no permissionerror when I use a RAM user to grant theAliyunRDSImportRolepermission?A2: Use your Alibaba Cloud account to temporarily grant the
AliyunRAMFullAccesspermission to the RAM user. For more information about how to grant permissions to a RAM user, see Use RAM to manage ApsaraDB RDS permissions.
Related API operations
API | Description |
Restores a backup file from OSS to an ApsaraDB RDS for SQL Server instance and creates a data migration task. | |
Opens the database of an ApsaraDB RDS for SQL Server data migration task. | |
Queries the list of data migration tasks for an ApsaraDB RDS for SQL Server instance. | |
Queries the file details of an ApsaraDB RDS for SQL Server data migration task. |