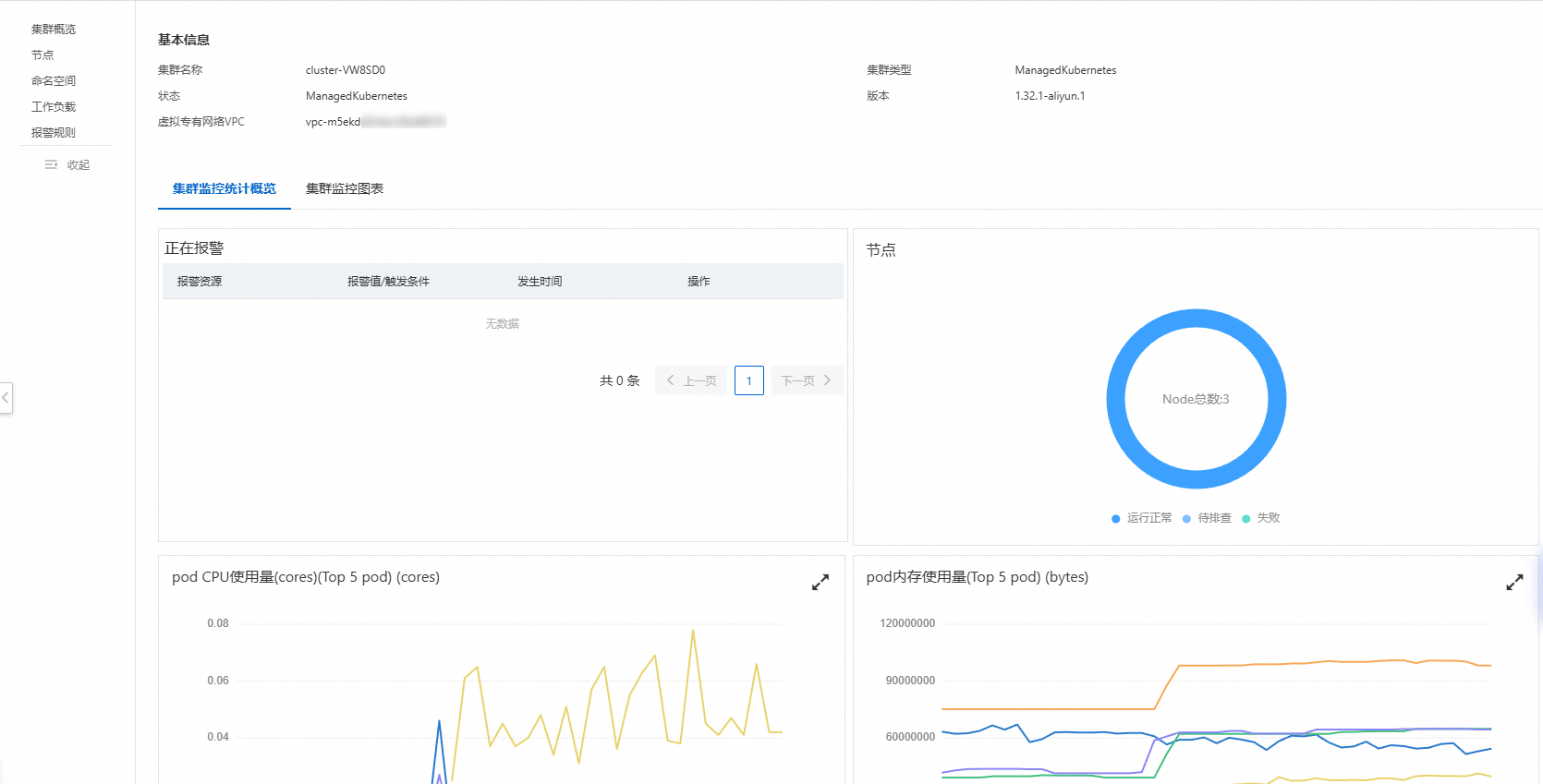
资源监控是Kubernetes中最常见的监控方式,您可以在ACK集群中使用云监控Kubernetes监控功能,快速查看工作负载的CPU、内存、网络等基础资源的使用情况和健康状态,确保集群稳定运行。
云监控的Kubernetes容器监控功能逐步下线中,详情请参见云监控 Kubernetes 容器监控功能变更通知,推荐您使用阿里云可观测监控 Prometheus 版作为替代方案,该方案涵盖了与云监控相同的功能。
功能特性
云监控会自动获取您当前阿里云账号下容器服务Kubernetes版的所有集群,实现跨地域、集中化和全局化监控容器服务。详细信息,请参见概览。
提供全集群视角的指标。
提供例如报警提醒、节点数量、Pod内存和CPU的使用量、节点内存和CPU的使用率等指标、让您更快捷地洞悉集群概况。
更专业的监控与报警能力。
升级旧版本云监控容器监控功能,提供更加专业的容器场景基础监控能力。从集群命名空间、节点、工作负载及Pod等原生Kubernetes概念视角提供关键指标监控能力。升级报警功能,支持Kubernetes场景下不同视角配置对应报警规则。
更合适的容器场景指标。
在宿主机基础设施层、容器PaaS层及Kubernetes调度层不同场景下使用最合适的指标。例如,容器中影响Kubernetes调度的内存指标,会使用容器工作内存的专用指标,与宿主机的内存Usage区分。
前提条件
集群的metrics-server组件为v0.3.8.5及以上版本。如需升级组件,请参见如下说明进行升级。
ACK托管集群的组件升级操作,请参见管理组件。
ACK专有集群且集群版本为v1.12及以下的低版本集群组件升级,请参见升级Kubernetes集群的metrics-server组件。
如果metrics-server组件未能升级到V0.3.8.5及以上版本,请使用旧版资源监控。具体操作,请参见旧版资源监控。
开启云监控Kubernetes监控功能
如何开启云监控Kubernetes监控功能,请参见开启容器服务Kubernetes版集群的云监控功能。
查看资源监控数据
配置指标报警的场景
场景 | 场景描述 | 指标报警配置 |
集群水位健康状况,以集群或节点配置水位报警。 | 当集群或集群节点发生水位等指标异常时,将上报集群资源异常,避免影响业务。此场景推荐以集群或集群节点的方式配置水位报警规则。 | 配置报警规则时,选择资源范围为集群或节点,配置以整个集群或集群任一节点出现指标异常时的报警规则。选择节点时配置全部节点,则当该集群的任一节点出现规则描述中的指标异常时,将触发报警。 |
异常容器水位状况,以对应集群下的任一Pod统一报警。 | 当集群发生资源水位异常情况时,通常需要分解问题,找到具体的Pod。此场景推荐以该集群中的任一Pod的方式配置水位报警规则。 | 配置报警规则时,选择资源范围为容器组(Pod),选择命名空间及容器组Pod为全部,则当该集群的任一Pod出现规则描述中的指标异常时,将触发报警。 |
按命名空间多租户使用集群场景,针对对应集群下的指定命名空间的Pod设置报警。 | 通常一个集群会被多个应用共享,通过命名空间来拆分应用是一种Kubernetes的常用应用多租户方式。当应用所在的命名空间发生水位异常时,您可通过报警感知异常。此场景推荐以指定命名空间下任一Pod的方式配置水位报警规则。 | 配置报警规则时,选择资源范围为容器组Pod,选择命名空间为对应应用所在命名空间,选择容器组Pod为全部,则当该命名空间下的任一Pod出现规则描述中的指标异常时,触发报警。 |
应用指标水位状况预警,针对对应集群下指定命名空间的指定应用(工作负载)的所属Pod设置报警。 | 通常一个集群会被多个应用共享,通过工作负载来拆分应用是一种Kubernetes的常用应用多租户方式,例如一个应用对应一个Deployment。当应用所对应的Deployment发生水位异常时,您可以通过报警感知异常。此场景推荐以指定工作负载下任一Pod的方式配置水位报警规则。 | 配置报警规则时,选择资源范围为容器组Pod,选择命名空间为对应应用所在命名空间,选择应用的工作负载类型。目前支持的Kubernetes工作负载类型有:无状态(Deployment)、有状态(StatefulSet)、守护进程集(DaemonSet)、任务(Job)、定时任务(CronJob)。选择容器组(Pod)中的任一Pod,则当该工作负载下的任意Pod出现规则描述中的指标异常时,触发报警。 |
配置指标报警规则
步骤一:创建报警联系人并关联报警联系组
登录云监控控制台。
在控制台左侧导航栏中,选择。
创建联系人,并添加到对应的报警联系组。
具体操作,请参见创建报警联系人或报警联系组。
步骤二:创建指标报警规则
登录云监控控制台。
在控制台左侧导航栏中,单击Kubernetes容器监控。
在Kubernetes容器监控页面,单击目标集群对应操作列的报警规则。
在报警规则页面,单击创建报警规则。
在创建报警规则面板,设置报警规则相关参数。
参数
描述
资源范围
报警规则的作用范围。取值:
集群:报警规则作用于目标集群。您需要选择集群名称。
节点:报警规则作用于目标集群的全部节点或指定节点。您需要选择集群及其节点。
容器组(pod):报警规则作用于目标集群的指定命名空间下应用中的全部容器组或指定容器组。您需要先选择集群及其命名空间,再从无状态、有状态、守护进程集、任务或定时任务页签中选择部署应用和容器组(pod)。
说明在容器组页签,您仅需选择容器组(pod)。
规则描述
报警规则的主体。当监控数据满足指定条件时,触发报警规则。
配置具体报警指标、阈值及报警级别。关于容器组指标的监控项,请参见容器服务Kubernetes版(新版)。
通道沉默周期
报警发生后未恢复正常,间隔多久触发一次同级别的告警。取值:5分钟、15分钟、30分钟、60分钟、3小时、6小时、12小时和24小时。
某监控指标达到报警阈值时发送报警,在通道沉默周期内如果触发的告警级别不变,该规则不会再次发送报警通知;当告警级别发生变化(恢复正常也算级别变化)或者间隔时间超过通道沉默周期,该规则才会再次触发告警。
说明报警历史有两种状态,一种是通道沉默周期,表示同一个资源在通道沉默周期内不发送通知的状态。另一个是通知沉默,表示不同资源在通道沉默周期内不发送通知的状态
生效时间
报警规则的生效时间。报警规则只在生效时间内才会检查监控数据是否需要报警。
报警回调
公网可访问的URL,用于接收云监控通过POST请求推送的报警信息。目前仅支持HTTP协议。关于如何设置报警回调,请参见使用阈值报警回调。
说明建议您填写公网可访问的URL。
报警联系组
发送报警的联系人组。
应用分组的报警通知会发送给该报警联系人组中的报警联系人。报警联系人组是一组报警联系人,可以包含一个或多个报警联系人。
关于如何创建报警联系人和报警联系人组,请参见创建报警联系人或报警联系人组。
单击确定,完成报警规则配置。
在报警规则页面,可以看到已创建的报警规则。关于报警规则的更多信息,请参见管理报警规则。
结果验证
在控制台左侧导航栏中,选择。
在报警历史页面可查看报警历史趋势及报警记录。
旧版资源监控
若容器服务Kubernetes版集群的metrics-server组件未升级到V0.3.8.5及以上版本,可按以下操作进入旧版资源监控页面。
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
选择所需的Deployment,单击右侧的监控,进入到云监控的相应的监控视图页面。
您可以单击部署应用、容器组列表、容器组热点页签查看监控数据。
可选:如需设置告警,您可以在左侧导航栏选择。
分组级别的指标以group开头,实例级别的指标以pod开头。
常见问题
云监控的Kubernetes集群为什么没有数据?
如果查看容器监控数据为空,相关排查操作请参见如何处理云监控中容器服务Kubernetes版集群无数据问题?。