By Yuriy Yuzifovich, Head of Security Innovation Lab (SIL) of Alibaba Cloud,
Thanh Nguyen, Principal Data Scientist at SIL, and
Anastasia Poliakova, Sr. Security Engineer, SIL
Cyber-attacks are becoming more sophisticated, and more automated. With modular code reuse and minor file tampering to generate different binary files to bypass rule-based or signature-based methods, the number of malware samples keeps accelerating and making it very difficult for the cybersecurity community to detect, track, and report these variations. In some extreme cases of highly-variable malware, these variations are purely random simply to generate random hash values, and as such each of these individual variants is not worth of even tracking since it will never repeat in a different machine. The industry has multiple solutions to this problem, from behavioral analysis to tracking and finding anomalies in machine access (zero trust), to name a few.
At Security Innovation Labs (SIL), we use multiple behavioral AI methods, including analysis of traffic (DNS, HTTP, IP connections), automated reasoning combining multiple data points, and various types of anomalies. Recently, we had breakthrough results with fuzzy hashing, that at the massive scale of Alibaba Cloud produced insights that were never possible to achieve with other methods. In this series of blog entries, we will describe fuzzy hashing in the context of malware detection and classification in Alibaba Cloud.

We also strongly believe in the power of the cybersecurity community to share both direct threat intelligence data, as well as the techniques that makes us, cybersecurity industry, stronger against the bad actors. This is why we presented our findings at BotConf in April 2022 in Nantes, France, and then followed up with publishing our paper "Detecting emerging malware in the cloud before VirusTotal can see it" in The Journal on Cybercrime & Digital Investigations
Following up on the successful presentation, and to respond to a number of questions we received during the conference about our work, we decided to create this series of blog postings to talk about our ssdeep-based validation progress we made. To keep the audience properly entertained, we will supply a number of visualizations, as visual representation of the cybersecurity information is a powerful, yet underappreciated tool of data exploration and decision making.
In this article, we will describe the limitations of classical hashes, provide a brief overview of fuzzy hashing and our choice, ssdeep, and show results with XOR.DDoS detection, a popular Linux Trojan malware. In the subsequent entries, we dive deeper into distances between fuzzy hashes, engineering challenges we overcame, how we built our graph, and what results we were able to achieve. The Data Insights in Cybersecurity blog series will not stop there; observing the malware at the cloud scale never leaves at the lack of the insights to share.
In a perfect world, we can easily keep malicious binaries intact, create pairwise similarities between the binaries, and using the perfect distance metric, connect highly similar binaries together, effectively building a graph. We could also easily detect a new variant by comparing a suspect against the whole database of existing binaries to find a close match, thus enabling immediate detection of most popular malware families.
But the high volume of the unknown binaries makes this idea impossible to implement. Malware can morph, creating a unique binary for every infected machine, and such a full library of binaries will have a lot of noise, not to mention a lot of resources it will consume, and will carry little value compared to the investment. Can we reduce the binaries to a small digital signature that uniquely represent it but without consuming too much disk space? This is where cryptographic hashes come in, and SHA256 hash is one of the most widely used to keep track of the new malware.
The cryptographic hash algorithms are widely used for integrity check and allow to verify if two binary files are identical without directly comparing them. The very nature of a good cryptographic hash, and SHA256 is certainly good, is that the value of the hash does not communicate anything about the hashed information. This wonderful property makes it impossible to compare binaries using hashes, other than declaring if it's exactly the same binary or not. Even a change of a single byte makes it a completely different SHA value.
The graph below is a sample visualization of what the connectivity between binaries, represented as hash values, and process names, looks like in the wild, as observed in the cloud (we replaced actual process names and sha256 values to improve visibility of the graph shapes). As you can see, one SHA256 value (binary) might have different paths of the process referring to it (on different cloud machines). Sometimes the same process path can correspond to different SHA256 values, but this happens much less often, not surprisingly, as changing the name is easier than generating a new binary.
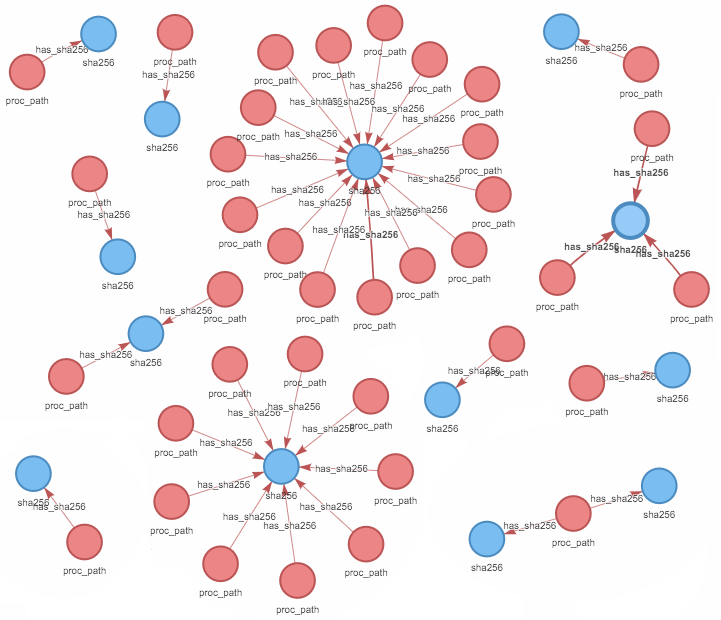

Fuzzy hash in natural habitat
Fuzzy hashing in general, and ssdeep in particular as one of the most widely used fuzzy hash, is designed to preserve certain information from the original binary in a hash value. Ssdeep uses context triggered piecewise hashing (CTPH) and similar file fragments manifest themselves into lexically similar portions of the resulting hash, thus enabling the use of similarity algorithms developed to compare human language fragments. We used Levenshtein edit distance to calculate the distance between ssdeep values for the purposes of finding the similarity between the binaries, which allowed us to create an end-to-end pipeline converting binaries into the connected graph of ssdeep values. In the next installment, we will go into more details about the ssdeep, Levenshtein edit distance, and the graph construction. Less patient readers can proceed straight to the published paper mentioned in the Introduction.

Many teams attempted to solve the same problem at Alibaba Cloud and Group Security, and they created and over time accumulated a large database of suspicious binaries. When we started our ssdeep work, this library had hundred million samples, with small files retained for analysis as intact binaries while larger ones reduced to hash values to save storage costs. Given the scale of the monumental task of sorting through this data set, only a small portion of the data was properly processed. A pairwise similarity required comparing 100 million against 100 million – a task of 10 to the power of 16 comparisons. It's almost as many as the number of ants on earth (2*1016). This is way beyond direct computability even at such a large cloud provider as Alibaba Cloud.
Our Security Innovation Lab team of seasoned security researchers, data scientists, and engineers solved many problems that were considered impossible in the past, and we approached this task with the we-can-do attitude. Not only we were able to compute pairwise similarity for this data set, we also reduced it to true malicious binaries of 10 million with pairwise similarities computed which resulted in a connected graph of binaries with confirmed maliciousness. 10 to the power of 14 is still a very large number, and a more detailed insight into how we were able to achieve this Herculean feat with relatively modest computational investment will be described in our third installment of this series, "Fuzzy optimizations".
While we were successful in initial processing of 100 million samples to create our graph, this was just the beginning. Our security product, Cloud Security Center, has the functionality of detecting new suspicious binaries and we added our anomaly detection to narrow down the binaries that we would like to compare to our growing ssdeep graph. SIL-build general anomaly detection (GAD) is a modular, general-purpose engine that can detect anomalies among the IPs, domain names, hashes, malicious behavior, and access privileges on the scale of the cloud and generates IoC candidates for further AI-driven validation.
The GAD can also have components that can detect anomalies for a limited set of customers within similar digital assets (such as ECS machines and containers), which we effectively used in business risk functionality SIL developed from the ground up for our largest customers, which we will describe in more depth in a separate blog. Anomaly detection engine, with its multi-stage data reduction pipeline, successfully lowered computing costs by a factor of x100 to where we could manage these variations without asking for higher computing budget.
Alibaba Cloud employs dozens of models to detect potentially malicious activity, making our cloud-native security products perform with high precision and good coverage. Our ssdeep model was designed to complement these other methods, so that the alerts thrown to SIEM had higher precision and confidence levels. This cross-validation is one of the hallmark features of our cloud data processing techniques to find rare events in trillions of data points of noise. In one of the subsequent blogs we will describe some of these automated and AI-driven validation techniques SIL put in production over the last few years.
Over a few days of observing the performance of our ssdeep detection, we calculated the overlap between this model and other anomaly engines and malware detection techniques. Our analysis showed that of the 3,924 ECS machines flagged by the ssdeep detection, 3,856 machines had one or more of other types of suspicious events detected (for example, unusual internet connection or a login). Not only we showed that ssdeep alone produced a net gain of 68 machines, it also improved the confidence of the decisions that are based on other types of anomalies.
While in this blog we focus on a more straightforward case of high similarity to attribute a new binary to an existing malware family and on XOR.DDoS in particular, the capabilities of the graphs are not ending here. We collaborated with DAMO Academy, a research arm of Alibaba Cloud Intelligence, for an analysis approach using graph pattern-learning to discover the subgraph patterns to predict the newly emerging sample's behavior by its topological neighbors.
XOR.DDoS is a self-evolving trojan and one of the most popular and prolific Linux malware families. It is named after the way the malware encrypts its communication with command and controls with a XOR-based cypher. When it was discovered in 2014, this malware had the original purpose of creating a bot-based infrastructure to launch DDoS attacks on Linux servers. Over time, Windows was added its list of supported platforms, and the malware writers stayed up-to-date with adopting Docker service exploitation and added a detection evasion mechanism.
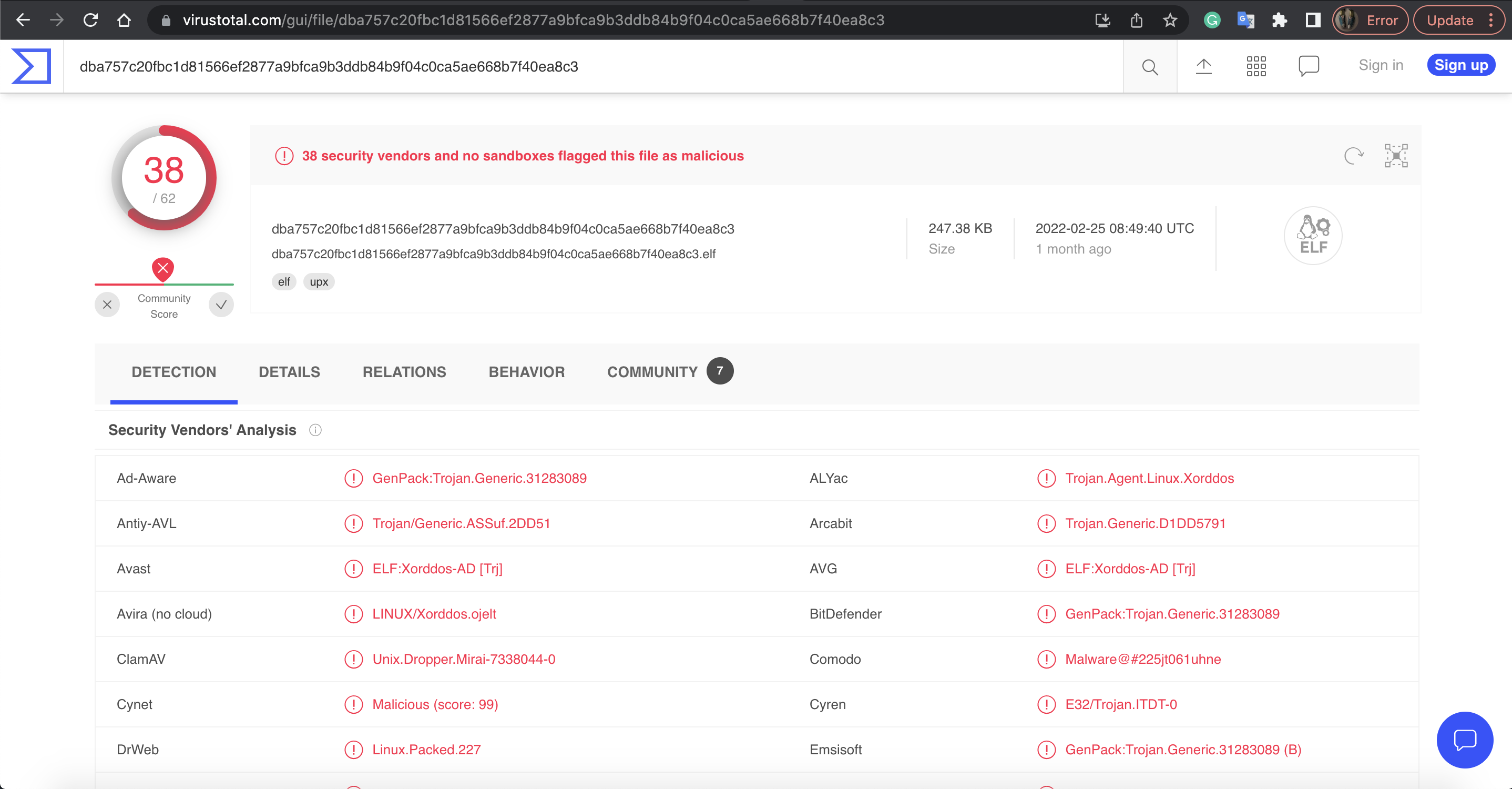
One of the original XOR.DDoS file we had access to was an ELF executable file of the size of 247KB:
MD5: d6a6dee6afa6879b729a0af3cde7ff33
SHA1: 47ed693d195558507e4258527f7d4d 4968d34f38
SHA256: dba757c20fbc1d81566ef2877a9bfca9b3ddb84b9f04c0ca5ae668b7f40ea8c3
Ssdeep: 6144:3SDFOrnwRgUbMisI6sdkH+M6hWOcy5KOZW7U6NCEqPdf/mqYG:2ZRgUY/fsJcO1KOiXfqPdeGThis binary was identified, not surprisingly, as malicious by VirusTotal:
We then found a new suspicious binary with the following MD5 by our anomaly detection model: MD5: 6a749f 7b071e713affdcd759bc90707e.
The similarity score that we calculate for ssdeep hashes can range from 0 (binaries share no common code) to 100 (binaries are identical). It was 97 when compared with the known XOR.DDoS sample above, indicating a high similarity. Even though VirusTotal did not have this MD5 in the database at the time of our detection and classification, our pipeline labeled this new binary as XOR.DDoS, as the similarity was above the threshold we selected.
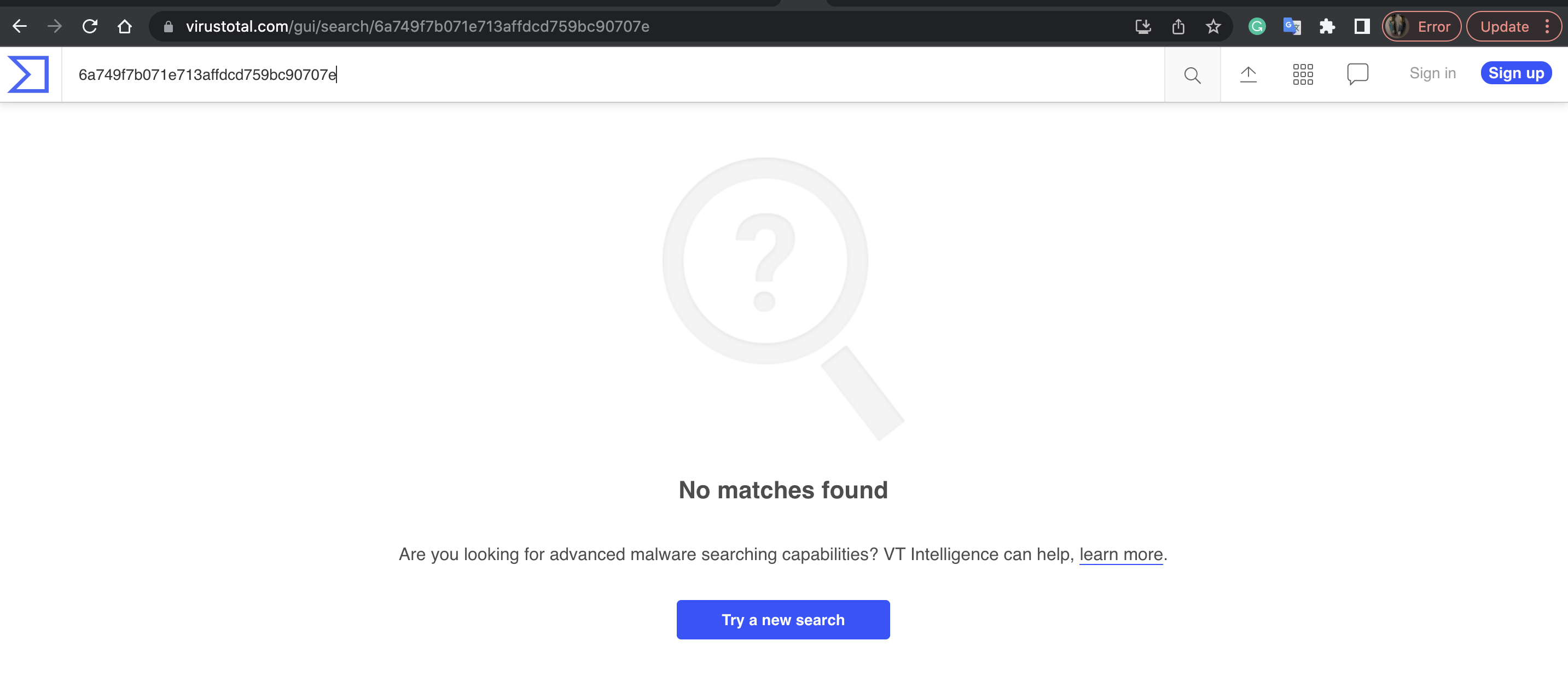
Effectively, our automated pipeline discovered this new variant earlier than the 3rd party vendors we checked against, including VirusTotal. While we showed here only one binary as an example, our detection and classification engine routinely finds thousands of new variants that are not present in any of the 3rd party threat intelligence databases. The ssdeep-flagged samples that do show up in other engines just confirm the continued effectiveness of our in-house detection.
XOR.DDoS not only tries to morph the binary to avoid hash-based detection, but also generates a random directory name under /usr/bin/ with ten random letters:
/usr/bin/gsqykkwuag
/usr/bin/tldpjssjet
/usr/bin/nrhfapuwjp
/usr/bin/kgpeplprzq
/usr/bin/uhflpmyerdThe behavioral pattern of the directory name generation can be used as a secondary feature to confirm XOR.DDoS classification in addition to the close Levenshtein edit distance.
Since this malware family updates its binary content to create a unique SHA hash for each sample, and its filename is also different, it is challenging for existing threat intelligence security feeds to have information about every mutation and to have correct attribution. The malware name also seems to mutate from one security vendor to another, taking different aliases: Trojan.Linux.GenericA.18093, Linux.Agent.253320, Linux.Packed.227, Linux.Agent.9!c, etc., to create further confusion. Ssdeep block size (for example, a block size of 12288) is a strong feature for validation we used in conjunction with other methods to confirm that the similarity we observe is indeed not a false-positive.
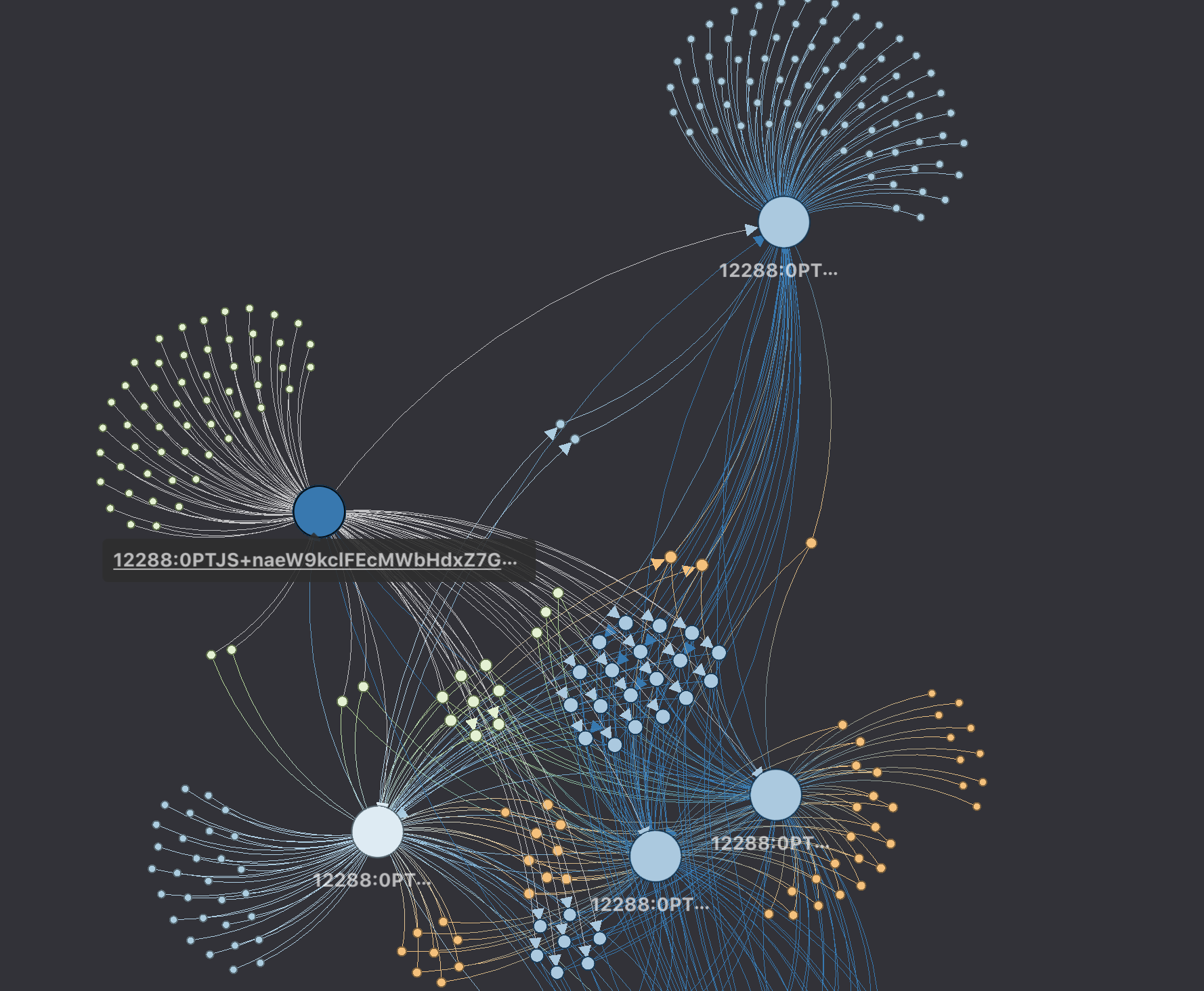
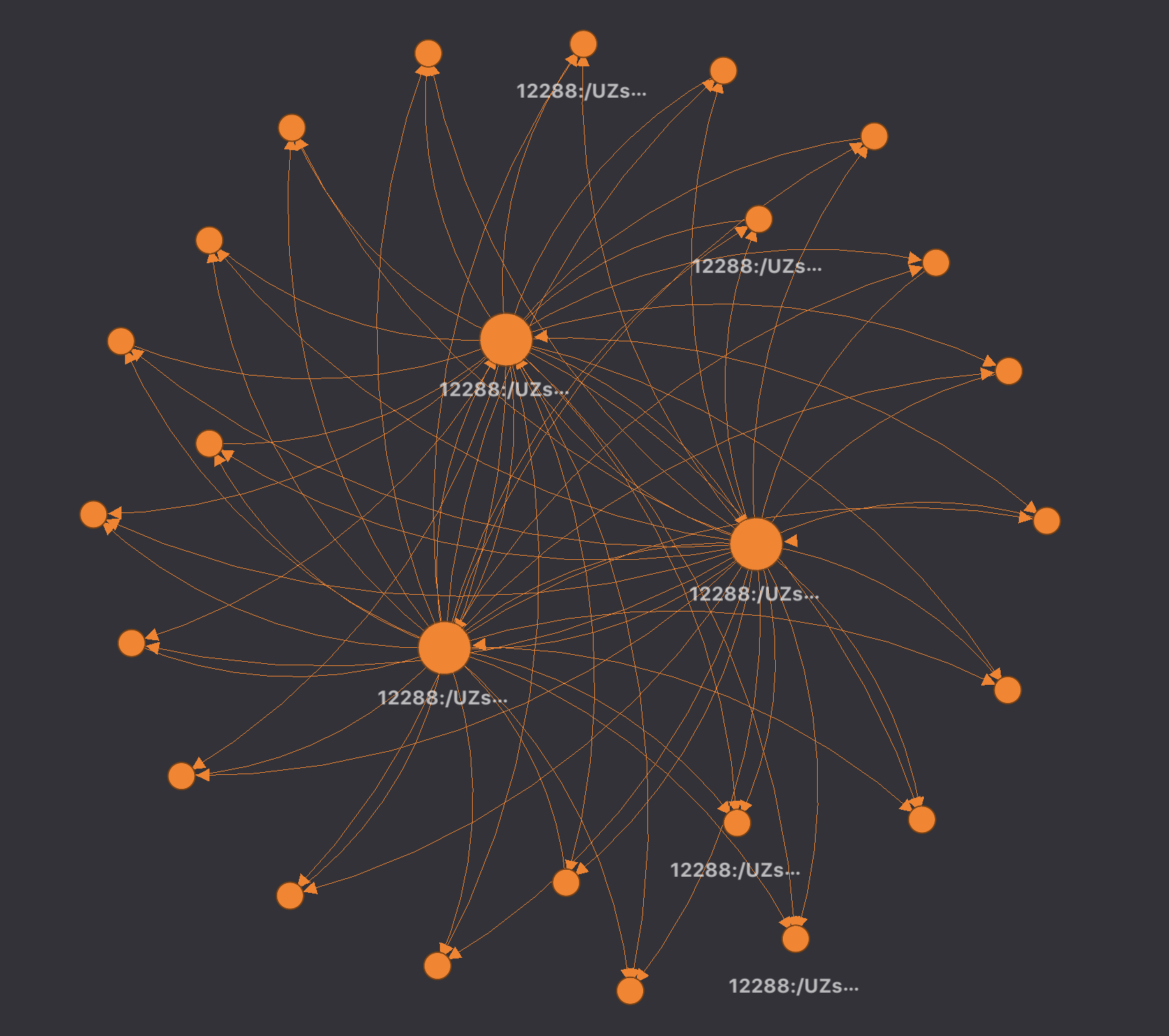
Our graph-based approach builds the similarity without a predefined knowledge, such as known vendor classifications. Using only binary similarity above a threshold, we visualized the whole XOR.DDoS subgraph that started from the original, known binary seed. In fact, our graph-based approach can find similarities between 3 rd party threat intelligence vendor classifications, which can be useful for internal IoC management.

XOR.DDoS binary similarity graphs with 10,000 samples. Larger circles indicate more connections to particular variants.

XOR.DDoS binary similarity graph, a different view.
Below are a few smaller sub-graphs where branching activity of the XOR.DDoS is more visible:
Our XOR.DDoS detection is robust across time, as the malware continues its minor mutation without major changes to the binary. This chart shows continuing ssdeep-based detection across several days for a single seed:
192:vbOzawOs81elJHsc45CcRZOgtShcWaOT2QLrCqw+45Y04/CFxyNhoy5t:vbLwOs8AHsc4sMfwhKQLro/L4/CFsrd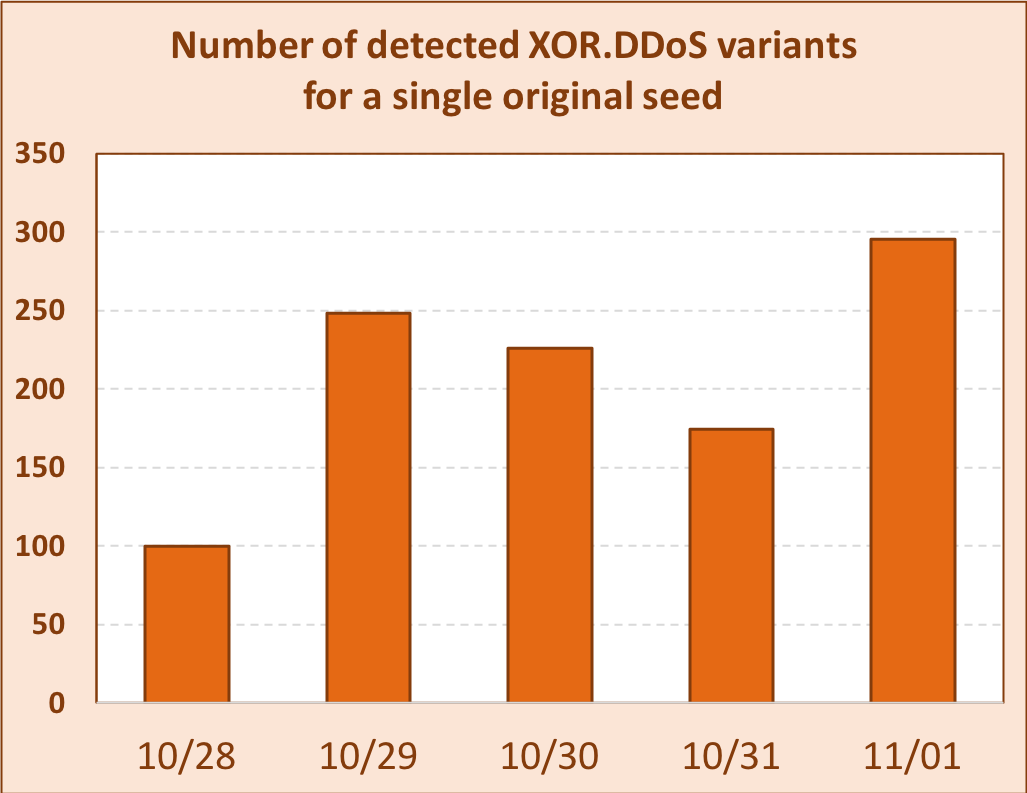
We continue to improve ssdeep pipeline. Recent improvements include implementation of a more effective connection between different flavors of XOR.DDoS that are farther away from each other, distance-wide, than a random variation by a few bytes.
Using our newly constructed graph based on ssdeep fuzzy matching, we started comparing suspicious binaries with our repository. Over just three months since our production pipeline became fully operational in late July 2022, 7 million new samples were flagged as potentially suspicious by other in-house Alibaba Cloud algorithms and 3rd party threat intelligence vendors. Half of these 7 million, 3.5 million binaries showed strong connection to our graph of classified malicious samples. Since we have been continuously improving our ssdeep-based detection and classification engine for better coverage and more precise attribution.
According to Microsoft 365 Defender Research Team, "Its evasion capabilities include obfuscating the malware's activities, evading rule-based detection mechanisms and hash-based malicious file lookup, as well as using anti-forensic techniques to break process tree-based analysis." At Alibaba Cloud, we successfully addressed one of these evasion techniques, "hash-based malicious file lookup", with our ssdeep-based approach.
Not only we confirmed maliciousness of these new binaries, and determined what malware class each belonged to, we also kept updating our graph with these binaries using our new binary anomaly detection, further improving detection going forward. While using ssdeep similarity is a well-known technique to compare malicious binaries, our work on calculating pairwise similarity for the warehouse of 100 million binary samples, along with creating an ongoing pipeline to process new binaries represents the scale that was not attempted before Security Innovation Labs of Alibaba Cloud successfully solved it.
In the next blog, we will provide a more comprehensive overview of the fuzzy hashing, provide details on the Levenshtein edit distance, and explain our graph construction technique. We will also include the visuals of the connected graphs for another popular malware type - miners.

1 posts | 2 followers
FollowYuriy Yuzifovich - November 8, 2022
Alibaba Clouder - March 22, 2019
Alibaba Clouder - June 21, 2019
Alibaba Cloud Community - September 21, 2021
Data Geek - February 27, 2025
Alibaba Cloud Community - August 3, 2023
1 posts | 2 followers
Follow Security Center
Security Center
A unified security management system that identifies, analyzes, and notifies you of security threats in real time
Learn More Security Solution
Security Solution
Alibaba Cloud is committed to safeguarding the cloud security for every business.
Learn More
Data Security on the Cloud Solution
This solution helps you easily build a robust data security framework to safeguard your data assets throughout the data security lifecycle with ensured confidentiality, integrity, and availability of your data.
Learn More Security Overview
Security Overview
Simple, secure, and intelligent services.
Learn More
