

产品优势
-
![]()
高稳定
脱胎于阿里巴巴集团内部实时传输系统,支持历年11.11购物节,久经考验,稳定可靠。
-
![#]()
高吞吐
最高支持单主题(Topic)每日T级别的数据量写入,单个分片(Shard)支持最高每日百GB级别的写入量。
-
![#]()
低成本
随开随用,按量付费,用非常低的成本完成传输任务。
-
![#]()
生态融合
源于飞天系统,与阿里云大数据系统深度整合,无缝对接MaxCompute、实时计算、交互式分析等产品,打通整个大数据体系。




强大的数据同步能力
多样化的数据接入和同步能力,灵活的数据缓存及交互方式

数据接入
提供多种SDK、API和Flume、Logstash等第三方插件,让您高效便捷的把数据接入到数据总线。

数据投递
提供DataConnector模块,稍作配置即可把接入的数据实时同步到下游MaxCompute、OSS、TableStore等存储分析系统,极大减轻了数据链路的工作量。

数据缓存
灵活的缓存时间,下游可重复消费,自动多备份,保障数据高可靠性。

多种接口
既有适合人交互的Web控制台,也有适合程序交互的API和SDK,满足各种使用需求。
典型应用场景
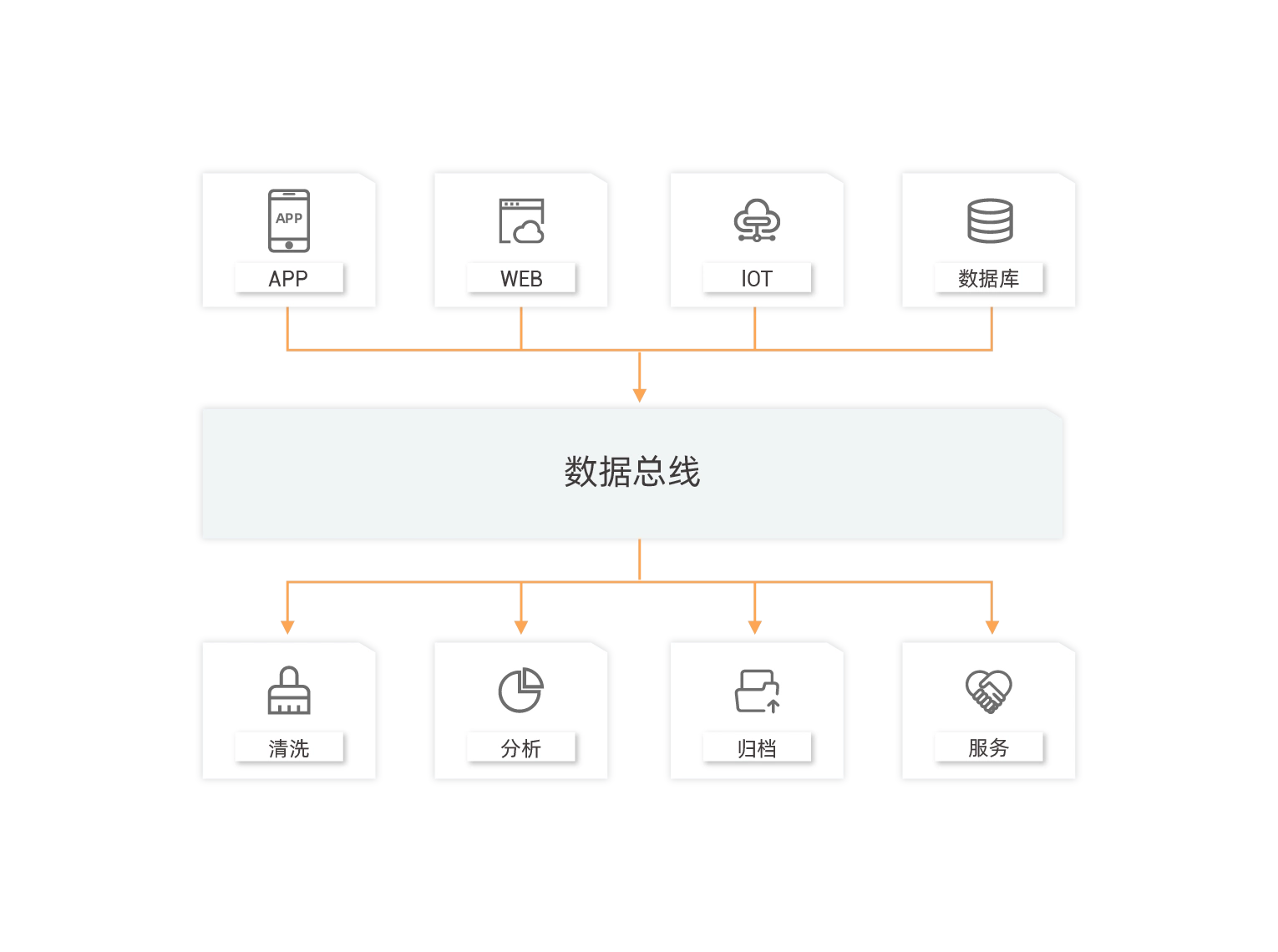
接入多种异构数据并投递到下游多种大数据系统
通过数据总线,您可以实时接入APP、WEB、IoT和数据库等产生的异构数据,统一管理,并投递到下游的分析、归档等系统,构建清晰的数据流,让您更好的释放数据的价值。
能够解决
-
 系统解耦
系统解耦对外,大数据系统与业务系统解耦,对内,大数据系统各组件之间解耦。
-
实时通道
通过数据总线,业务数据能够实时汇入大数据系统,缩短数据分析周期。
相关产品
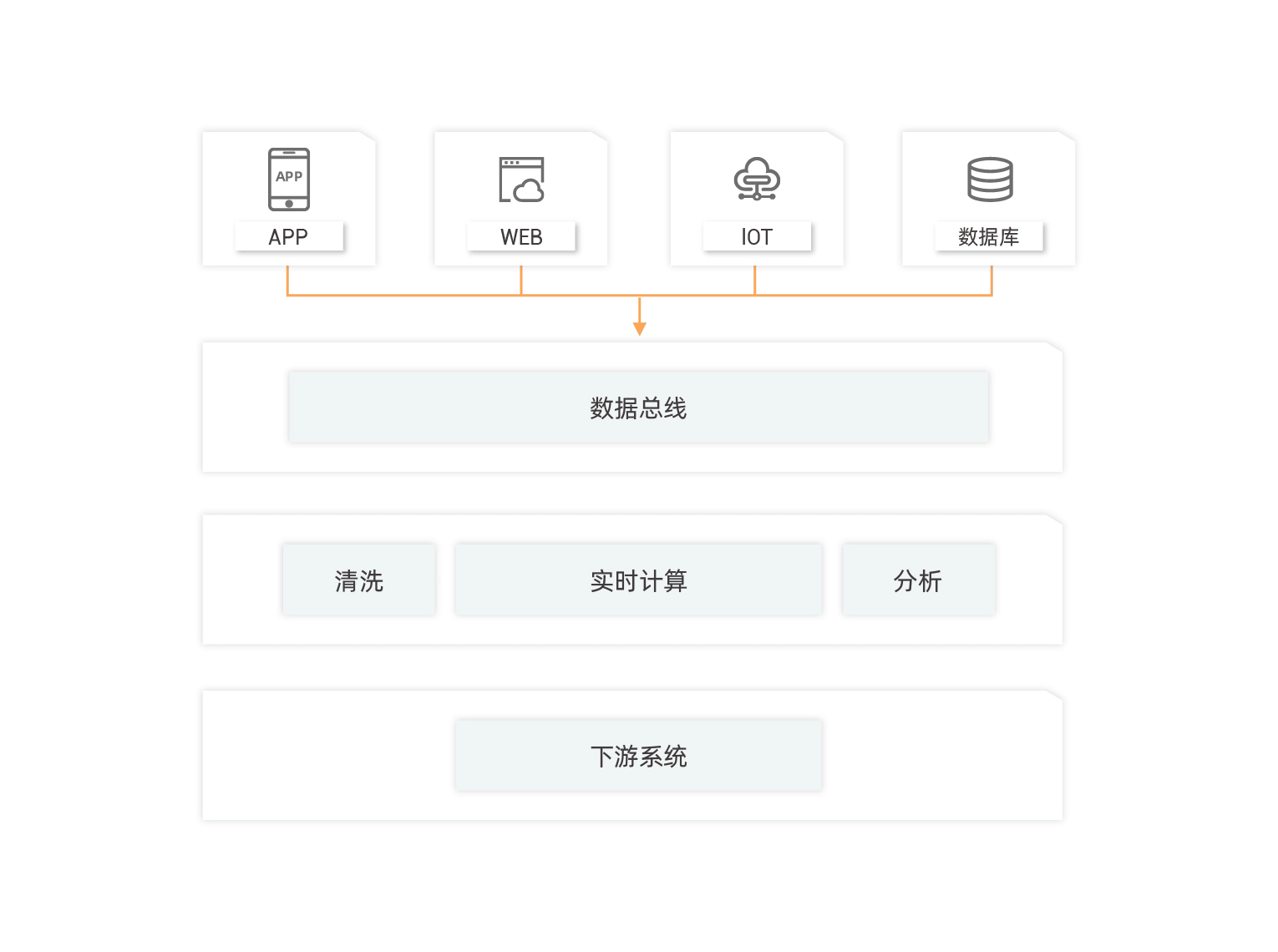
互联网广告业务实时分析
对互联网公司而言,广告依然是目前主流的变现方式。广告的本质是在卖流量,所以这是一个实时决策、在线转化的过程,离线数据T+1的计算已经不满足业务需求,整个行业需要实时转型。
能够解决
-
实时汇聚多种数据源
利用DataHub收集不同终端的用户信息,后配合实时计算引擎Flink进行广告实时侦测,反馈失效链接、流量作弊行为等。
-
实时分析决策
不同平台数据统一计算,避免数据孤岛,实时场景下引导客户快速做出业务反应,避免流量损失,提高广告曝光度。
相关产品
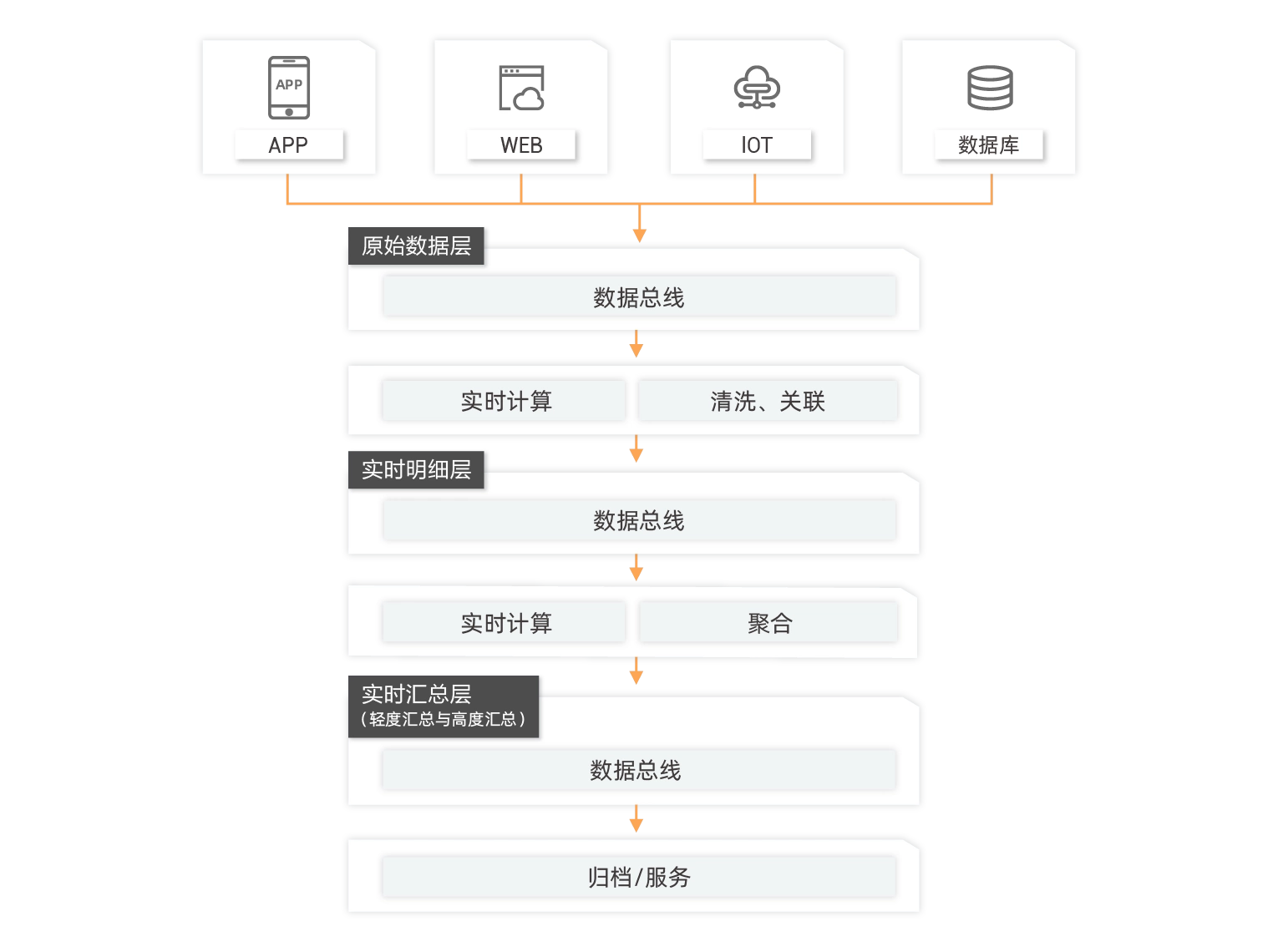
数据总线替换传统数据库,构建实时数仓
随着业务向实时需求的转型,传统T+1的离线数仓已经无法满足业务需求。可以利用数据总线DataHub和实时计算引擎Flink构建实时数仓系统,将数据分为:公共明细层(dwd),公共汇总层(dws),应用结果层(ads),使用Kappa架构构建整个体系
能够解决
-
统一的Kappa架构
传统Lambda架构的两条链路缩减为一条,大大降低维护成本。
-
大数据实时化
满足业务对实时性的需求,做到了数据复用,减少重复计算与存储;同时使得业务指标口径统一,避免混乱。


