최신 버즈
AI 추론에 대한 ML_PREDICT 함수.
더 알아보기>Apache Flink Power: Alibaba Cloud와의 규모의 엔터프라이즈 급 스트리밍
블로그 읽기>Lazada를위한 효율적인 제품 선택 플랫폼 구축: Apache Flink 및 Hologres를 통한 실시간 분석 여정
블로그 읽기>Git 코드 저장소와 통합
더 알아보기>실시간 광고 레이크 하우스 구축: Frink & Paimon과의 Alibaba Mama의 실습
블로그 읽기>Apache Flink CDC를 사용하여 실시간 Lakehouse에서 데이터 섭취 가속화
블로그 읽기>
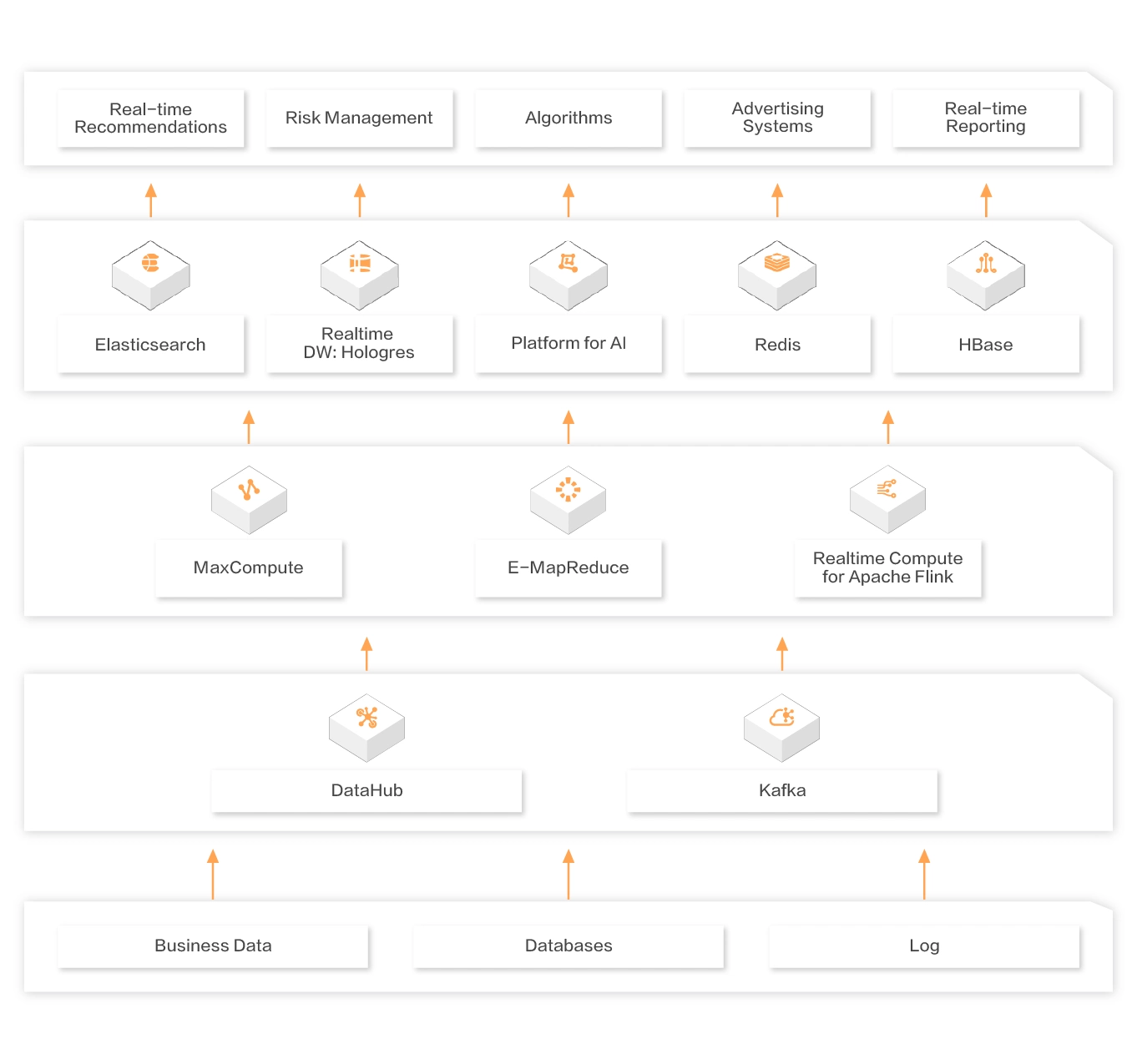
Apache Flink에 대한 실시간 Compute는 Apache Flink를 기반으로 실시간 빅 데이터 처리를 가능하게하는 원 스톱 고성능 플랫폼을 제공합니다. 스트리밍 데이터 처리, 오프라인 데이터 처리 및 데이터 레이크 컴퓨팅과 같은 다양한 시나리오에서 널리 사용됩니다. Apache Flink에 대한 실시간 컴퓨트를 사용하면 비즈니스 통찰력과 의사 결정을 위해 빅 데이터를 실시간으로 처리하고 분석 할 수 있습니다.
Tmall Double Eleven Global Shopping Festival 기간 동안 Alibaba Group이 대량의 데이터를 처리 할 수있는 주요 컴퓨팅 서비스를 제공하는 전 세계 유일의 제품입니다.
고성능 플랫폼

일괄 처리 및 스트림 처리 지원
일괄 처리와 스트림 처리에 동일한 엔진 및 API를 사용하여 개발을 간소화합니다.

초고성능
일부 성능 지표의 경우 오픈소스 Apache Flink에 비해 10배, Apache Spark에 비해 5~10배 높습니다.

최첨단 기술
Apache Flink 커밋 사용자의 전문 지식을 통해 Flink와 관련된 광범위한 문제를 해결합니다.
특징

-
강력한 기능 - 실시간 및 오프라인 데이터 처리와 관련된 문제를 처리할 수 있는 원스톱 플랫폼 제공
SQL을 통해 실시간 및 오프라인 데이터 정리, 데이터 분석, 데이터 동기화, 서로 다른 데이터 소스에 대한 컴퓨팅 및 데이터 레이크 기능을 구현할 수 있으며, 스트리밍 데이터 및 정적 데이터에 대한 연결 쿼리를 수행할 수 있습니다.

-
초고성능 - 높은 처리량 및 확장성을 특징으로 함
Apache Flink 커뮤니티의 SQL을 크게 개선하여 초당 수백만 개의 데이터 레코드에 이르는 작업 처리량을 달성하고 데이터 처리 지연 시간을 초 단위로 단축합니다.

-
안정적이고 안전 - 단 한 번 의미 체계 사용, 자동 장애 복구 실현, 리소스 격리
단 한 번 의미 체계를 사용하여 중복 데이터가 처리되지 않고 처리되지 않는 데이터가 없는지 확인하고, 분산 클러스터를 기반으로 컴퓨팅을 실행하여 자동 장애 복구를 활성화하고, 테넌트 간에 컴퓨팅 리소스를 격리하여 상호 간에 부정적인 영향을 미치지 않도록 합니다.

-
사용 편리성 - SQL, 온라인 개발 및 사용자 정의 확장(UDX) 지원
교육 비용을 절감하고 신속하게 시작하며 비즈니스 로직에 집중할 수 있도록 표준 SQL을 지원하고, 스트림 처리 작업의 개발, 디버깅 및 관리를 통합하는 완전 관리형 온라인 개발 플랫폼을 제공하며, 온라인 디버깅, 지능형 코드 완성 및 온라인 관리와 같은 다양한 코딩 지원 기능을 제공합니다.
사용 시나리오
실시간 데이터 창고
기업이 디지털 운영 시스템을 구축하고, 주요 비즈니스 지표의 실시간 통계를 수집하고, 기업의 생산 및 운영을 시각적으로 제시하고, 비즈니스 결정에 대한 실시간 데이터 지원을 제공하도록 지원합니다.
실시간 ETL
수십 개의 커넥터, 커버 데이터베이스, 메시지 큐, OLAP 엔진 및 기타 시스템을 통합합니다. Self-Service SQL Writing은 완전 관리 서비스를 사용하여 실시간 데이터 흐름을 통합하여 기업이 Mid-End 데이터 구축을 지원합니다.
실시간 리스크 관리
기업에 대한 막대한 경제적 손실을 피하기 위해 실시간으로 대규모 데이터에서 부정 행위 및 악성 크롤러와 같은 비즈니스 위험을 확인하십시오. CEP (복잡한 이벤트 처리) 는 스트리밍 처리 작업의 비정상적인 상황을 직접 감지하는 데 사용할 수도 있습니다.
실시간 모니터링
실시간 컴퓨팅의 Flink 버전의 효율적인 상태 관리 및 풍부한 창 지원은 기업이 규칙 경보 구성 프로세스를 단순화하고 경보 효과를 개선하며 모니터링 플랫폼의 유지 보수 비용을 줄이는 데 도움이 될 수 있습니다.
실시간 추천
더 정확한 사용자 초상화를 구축하기 위해 AI 기술과 결합 된 사용자 행동의 실시간 분석, 사용자에게 적시에 추천 더 적합한 뉴스, 비디오 및 제품
실시간 IoT 데이터 분석
IoT 장치에서 생성 된 대량의 데이터를 실시간으로 캡처하고 분석하여 사용자가 실시간으로 장치의 실행 상태를 분석 및 진단하고 실시간으로 실행 중인 오류를 감지합니다. 실시간으로 제품 수율을 예측합니다.
산업 솔루션



인터넷 거래
전자 상거래 산업의 급속한 발전으로 "광역" 및 "와이드 넷" 의 원래 운영 모드는 더 이상 비즈니스 요구를 충족시킬 수 없습니다. 실시간 컴퓨팅을 통해 전자 상거래 기업이 디지털, 정제 및 개인화 된 운영의 방향 전환을 완료 할 수 있도록 사용자 특성을 빠르게 채굴하고 수요 환경 설정을 분석 할 수 있습니다.
사용 가능
실시간 사용자 초상화
다양한 유형의 고객을위한 실시간 및 효율적인 개인화 된 추천 개발하여 단일 전환율 향상
실시간 협회 추천
고객 구매 후 실시간 상관 분석 수립 정보 두 번째 구매 확률 향상
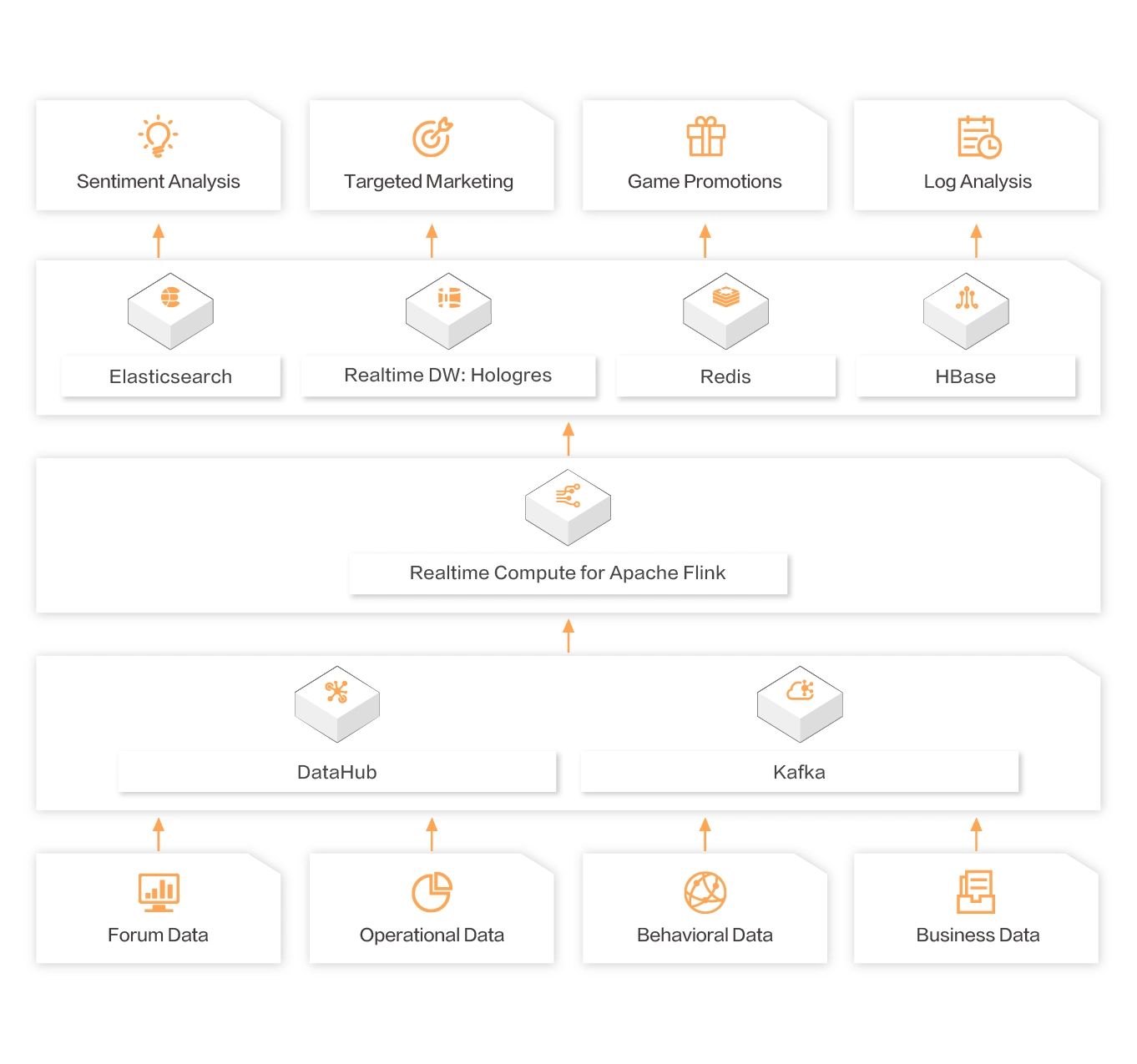
게임산업
신흥 엔터테인먼트 산업으로서 게임은 돈과 관심을 끌기 위해 더 많은 기업과 인재를 유치했습니다. 애플리케이션 스토어와 소셜 네트워크의 등장으로 게임 시장의 규모가 전례없이 확대되었습니다. 빅 데이터 및 인공 지능은 게임 운영, 특히 게임 수명 확장에서 점점 더 긍정적 인 역할을했습니다.
사용 가능
포럼 데이터 추적
플레이어 포럼의 커뮤니케이션 컨트롤에 따르면, 게임의 공정성을 보장하기 위해 현재 플레이어의 핵심 관심 정보와 게임 버그 탐지를 얻습니다.
운영 데이터 제어
실시간 컴퓨팅 기술을 통해 게임 운영 활동에 대한 실시간 분석이 가장 효과적인 사용자 변환 채널을 얻고 운영 및 촉진 효과를 향상시킵니다.
행동 데이터 분석
실시간 행동 데이터 분석을 기반으로 플레이어를위한 사용자 프로필 구축, 다양한 게임 복지 모드 사용자 정의, 플레이어 유지율 및 전환율 향상
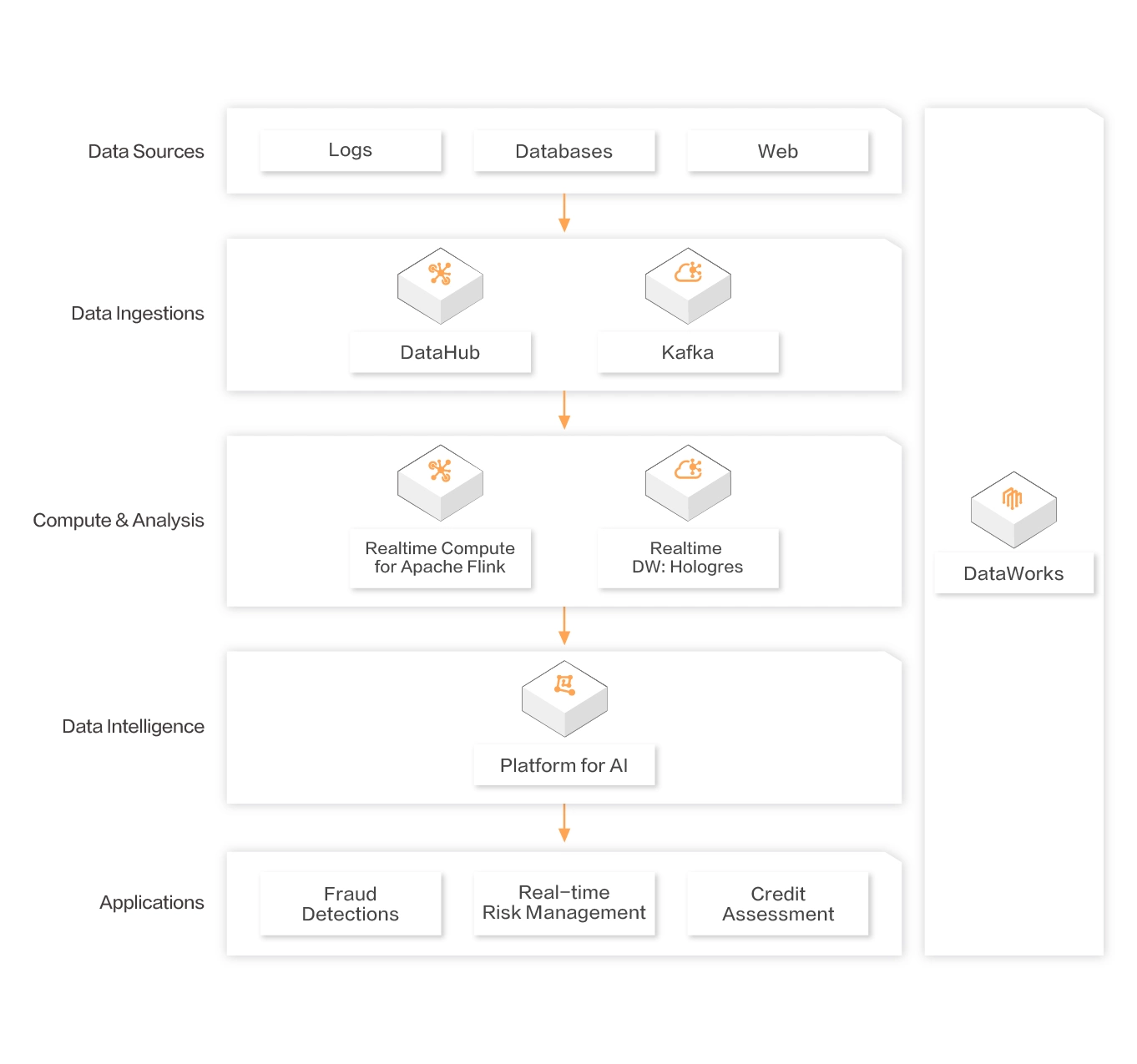
금융산업
최근 몇 년 동안 인터넷 금융 산업의 급속한 발전과 함께 전통적인 금융 기관의 다양한 비즈니스 (거래소, 증권 회사, 은행 등) 의 결합 인터넷이 더 가까워지고 가까워지고 있습니다. 링크, 위험 관리, 신용 평가, 사기 위험 및 데이터 품질과 같은 은행 요구 사항에 대한 전반적인 솔루션을 제공합니다. 금융 기관을 예로 들어 실시간 데이터 창고 및 사기 방지 시스템은 금융 기관이 실시간 위험 제어 시스템을 신속하게 구축 할 수 있도록 실시간 컴퓨팅 Flin을 통해 구축됩니다.
제공 가능
사기 탐지
실시간으로 사용자 계정 및 거래 행위를 모니터링하고 구별하고 거래 정보를 신속하게 식별하고 사용자 손실을 줄입니다.
실시간 위험 통제
실시간 컴퓨팅 Flink를 통해 전통적인 위험 제어 시스템 최적화, 지능형 위험 제어 변환 및 전반적인 인식 효율성 향상
신용평가
거짓 데이터 및 거짓 정보와 같은 악의적 인 사기를 신속하게 식별하고, 고위험 그룹을 식별하고, 지능형 방법을 통해 검토 프로세스를 단축하십시오.

광고 산업
모바일 인터넷의 발달로 정보 서비스의 임계 값 및 비용이 점차 감소하고 있으며 사용자의 정보 소비 행동이 더 빈번하고 다양 화됩니다. 모바일 네트워크 뉴스 산업 시장의 전반적인 성장률은 상대적으로 빠르며 개발 잠재력은 엄청납니다. 모바일 트래픽의 급속한 성장에 따라 모바일 뉴스 정보 사용자 수가 증가하고 상당한 차이가 있습니다. 훌륭한 운영은 미래의 주요 주제가 될 것입니다.
제공 가능
대규모 데이터 처리
강력한 데이터 처리 기능을 사용하여 증가하는 데이터 양 (플랫폼의 사용자 수 및 평균 일일 UV/PV와 같은 핵심 지표) 에 대처하여 비즈니스 효율성을 향상시킵니다.
복잡한 시나리오의 표준화
뉴스, 짧은 비디오 및 라이브 스트리밍과 같은 주류 미디어는 더 빠른 비즈니스 제어를위한 표준화 및 범용 시나리오를 구축했습니다.
빠른 실시간 비즈니스 출력
콘텐츠 공유 플랫폼의 개인화 된 비즈니스 요구에 따라 실시간 컴퓨팅을 통해 비즈니스가 개선되어 사용자 끈기와 소비 욕구를 증가시킵니다.
고객 성공 사례
Apache Flink에 대한 실시간 컴퓨트가 고객의 실시간 데이터 분석을 가능하게 하는 방법에 대해 알아보기