日志服务提供基于规则的数据实时消费功能,通过SPL可以实现在服务端的数据处理后进行消费。本文介绍基于规则消费功能的概念、功能优势、应用场景、计费规则、消费目标等信息。
工作原理
基于规则消费是指第三方软件、多语言应用、云产品、流式计算框架等通过设置SPL实时消费日志服务的数据。SPL是SLS推出的一款针对日志弱结构化特点进行高性能数据处理的语言。基于规则消费的原理是在服务端使用SPL对日志中的弱结构化数据进行预处理和数据清洗,例如行过滤、列裁剪、正则提取、JSON字段提取等操作,在数据到达客户端时已经是规整后的数据格式,SPL语法详情请参见SPL语法。
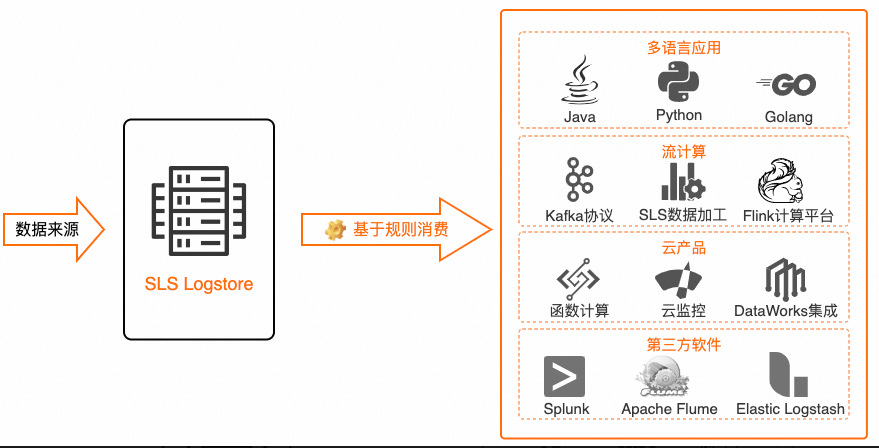
基于规则消费和查询与分析都是读取数据。关于两者的区别,请参见日志消费与查询区别。
应用场景
基于规则消费功能适用于流计算和实时计算中需要数据预处理的场景,例如在消费日志数据前,可能需要进行行过滤、列裁剪、正则提取、JSON字段提取等操作。基于规则消费的实时性较强,通常为秒级。您可以自定义存储时间。
功能优势
通过公网消费,节省流量费用。
某客户想把日志写入到日志服务后,再通过公网消费日志,过滤后再分发给内部系统。基于SPL消费功能,该客户可以直接在日志服务中实现日志规则过滤,避免将大量无效日志投递给消费者,节省网络流量费用。
节省本地CPU资源,加速计算进程。
某客户想把日志写入到日志服务后,再消费日志到本地机器进行计算。基于SPL消费功能,该客户可以直接在日志服务中实现SPL计算,降低本地资源消耗。
计费规则
若Logstore的计费模式为按写入数据量计费,基于规则消费将不产生费用,仅从日志服务公网域名所在接口拉取数据时,会产生外网读取流量(按照压缩后的数据量计算)。具体内容,可参见按写入数据量计费模式计费项。
若Logstore的计费模式为按使用功能计费,基于规则消费服务会产生服务端计算费用,使用日志服务公网域名可能产生公网流量费用。更多信息,请参见按使用功能计费模式计费项。
消费目标
日志服务支持的基于规则消费目标如下表所示。
类型 | 目标 | 说明 |
多语言应用 | 多语言应用 | 基于Java、Python、Go等语言的应用基于规则消费组消费日志服务的数据。具体操作,请参见通过API消费和通过消费组消费日志。 |
云产品 | 阿里云Flink | 您可以通过阿里云Flink实时计算消费日志服务的数据。具体操作,请参见日志服务SLS。 最佳实践: |
流式计算 | Kafka | 如有需求请提工单申请。 |
注意事项
基于规则消费需要在服务端进行复杂计算。由于SPL计算复杂度及数据特征的差异,数据读取的服务端延迟可能会略有增加(例如处理5MB数据,延迟增加10~100ms之间)。然而,一般情况下,尽管服务端延迟有所增加,但整体端到端延迟(即从数据拉取到本地计算完成的总时间)通常会减少。
基于规则消费在SPL语法错误、源数据字段缺失等情况下,可能会导致获取到的数据缺失或失败,具体说明可以参考错误处理。
基于规则消费在配置SPL语句时,SPL语句长度(字符串长度)最大为4KB。
基于规则消费与普通实时消费Shard读取限制相同:其中基于规则消费的Shard读流量是指SPL处理前的原始数据量,具体限制可以参考数据读写。
常见问题
规则消费的ShardReadQuotaExceed错误怎么处理?
这个错误码是由于Shard读流量超过Quota报错,解决方案:
消费客户端程序遇到此错误可以等待(sleep)后重试。
或者手动分裂Shard,对于Shard分裂后的产生的新数据消费,达到降低每个shard读取速度的效果。
规则消费的流量控制是什么样的?
规则消费的流量控制策略等同于普通消费的流量控制,具体可以参考数据读写。规则消费的流量计算是指SPL处理前的原始数据量:
例如原始数据大小为100MB(压缩后),经过SPL语句
* | where method = 'POST'过滤后,返回给消费客户端的数据大小为20MB(压缩后),读取流量控制是按照100MB来计算。
使用规则消费后,为什么在项目监控中的“流量/分钟”图表中看到的outflow的流量很低?
因为项目监控中显示的“流量/分钟”的outflow是指SPL处理后的数据量,并非原始数据量,如果SPL语句中包含行过滤、列裁剪等减少数据量的指令时,可能会有outflow低情况出现。