如需对采集到Logstore中的日志进行查询和分析,则必须创建索引。本文为您介绍日志服务索引概念、索引类型、创建索引、关闭索引、配置示例和计费说明等。
为什么需要创建索引
通常我们使用关键词从原始日志中检索想要的内容,例如包含curl的日志:curl/7.74.0。如果不进行切分,该日志文本会作为一个整体,不能和关键词curl完全对应,因此不会被日志服务检索到。
为了便于检索,需要将日志切分成独立、可搜索的词。日志切分由分词符实现,这些符号决定了日志文本内容被切分的位置。以该日志为例,使用分词符\n\t\r,;[]{}()&^*#@~=<>/\?:'"进行分割,得到的词是curl、7.74.0。日志服务基于切分出的关键词建立索引。创建索引后,您才能对日志进行查询和分析。
日志服务Project支持创建全文索引和字段索引。如果您同时创建了全文索引和字段索引,以字段索引的配置为准。
索引类型
全文索引
全文索引根据分词符直接将整个日志切分成多个text类型的词语。创建全文索引后,可以通过关键词进行查询,例如查询语句:Chrome or Safari ,查询包括Chrome或Safari的日志。
分词符不支持中文,开启包含中文选项,日志服务会自动按照中文分词。
如果只配置全文索引,则只能使用全文查询功能。更多信息,请参见查询语法与功能。
字段索引
字段索引将日志根据字段名称(KEY)进行区分,然后在字段内使用分词符进行分割。字段索引支持text、long、double和JSON四种类型的数据。更多信息,请参见数据类型。创建字段索引后,可以指定字段名称和字段值(Key:Value)进行查询,也可以使用SELECT语句。更多信息,请参见字段查询。
如需对字段进行查询或分析(SELECT语句),必须创建字段索引。字段索引的优先级高于全文索引,如果同时创建了全文索引和字段索引,以字段索引的配置为准。
text类型的字段,可以使用全文查询语句、字段查询语句和分析语句(SELECT)。
如果未开启全文索引,全文查询语句是从所有text类型的字段中查询结果。
如果已开启全文索引,全文查询语句是从所有日志中查询结果。
long和double类型的字段,可以使用字段查询语句和分析语句(SELECT)进行查询和分析。
创建索引
不同的索引配置,会产生不同的查询和分析结果,请根据您的需求,合理创建索引。创建索引后需要大约一分钟生效。
创建索引只对增量日志有效。如需查询历史日志,请使用重建索引功能。
日志服务已为部分保留字段创建索引。更多信息,请参见保留字段。
其中
__topic__和__source__的索引分词符为空,查询这两个字段时,关键字必须完全匹配。__tag__为前缀的字段不支持全文索引。您需要创建字段索引后,才能执行查询和分析操作,例如*| select "__tag__:__receive_time__"。日志中存在同名字段(例如都为request_time)时,日志服务会将其中一个字段名显示为request_time_0,底层存储的字段名仍为request_time。因此在创建索引、查询、分析、投递、加工时,只能使用原始字段名request_time。
控制台方式
登录日志服务控制台。
在Project列表区域,单击目标Project。
在页签中,单击目标Logstore。
在Logstore的查询和分析页面,单击开启索引。
说明开启后等待1min左右即可查询最新数据。

(可选)关闭自动更新索引
当Logstore为云产品专属Logstore或内部Logstore时,默认打开索引自动更新开关,后续如有版本更新时可以升级到内置索引最新版本。如果需要创建索引,请在查询分析面板中,关闭自动更新开关。
警告删除云产品专属Logstore的索引会影响相关报表、告警等功能的使用。
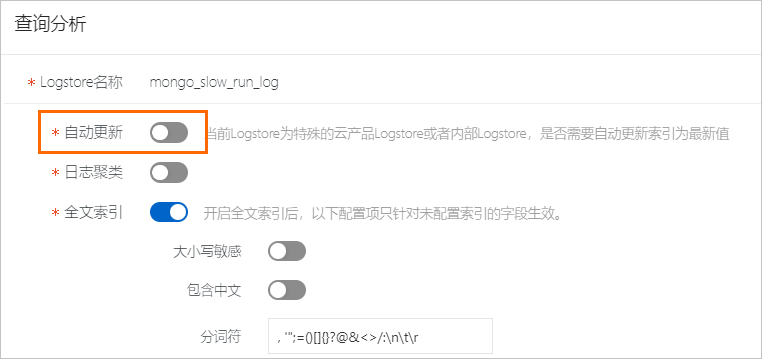
创建索引
创建全文索引
单击开启索引后,全文索引开关默认打开。您可根据需要选择是否打开日志聚类、大小写敏感、包含中文功能,也可选择指定分词符或自定义分词符。
页面配置如下所示:
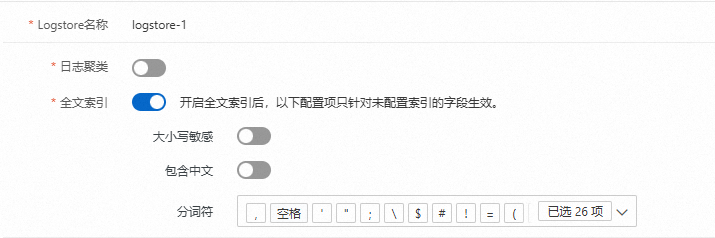
配置项说明如下所示:
创建字段索引
单击开启索引后。您可在查询分析页面单击自动生成索引。日志服务会根据采集时预览数据中的第一条内容,自动生成字段索引。如需自定义字段索引,可单击页面下方的
+创建,具体字段说明请参见配置项说明。首次打开时页面如下所示:
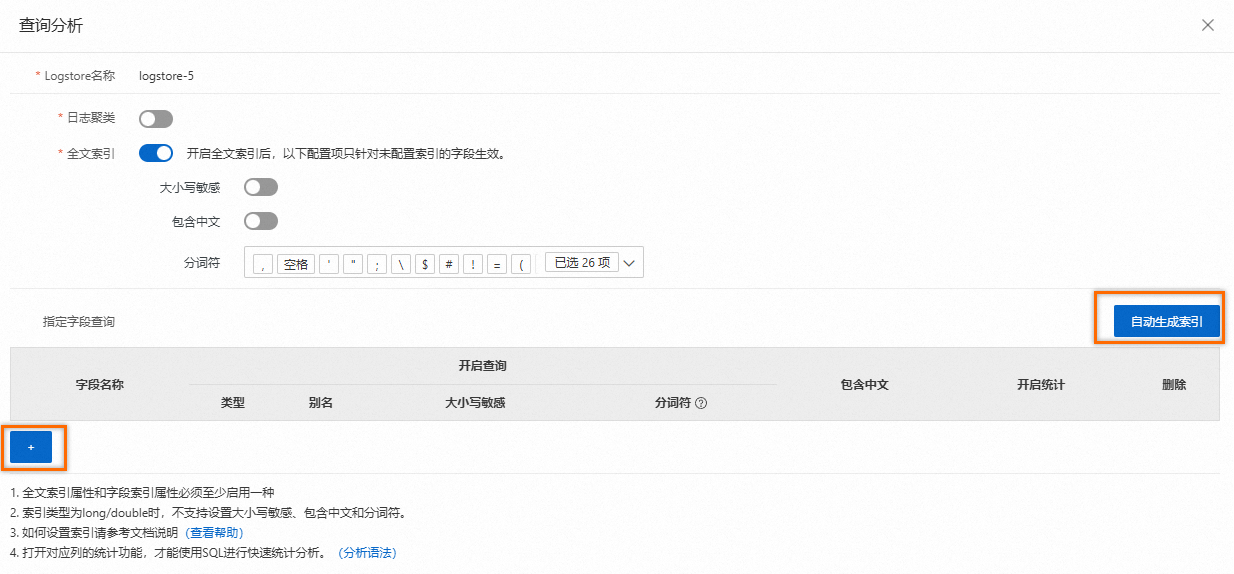
字段索引配置项如下所示:
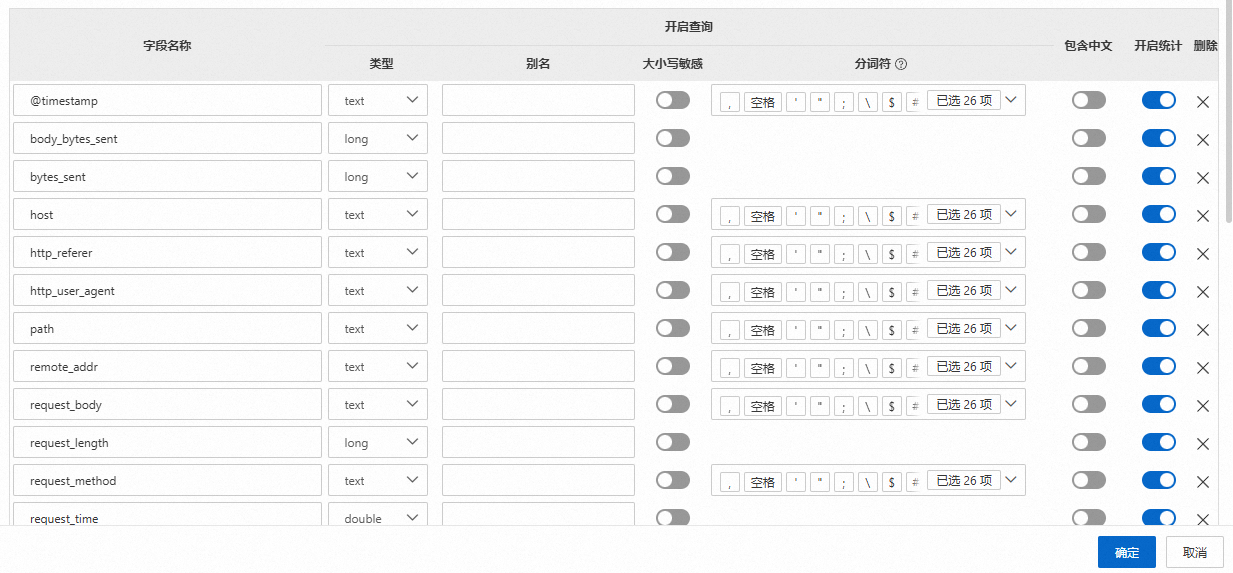
配置项说明如下所示:
(可选)设置字段的最大长度
SQL分析过程中,默认为截取一定长度,日志服务的默认配置为
2048字节,即2KB。如果您需要修改字段值的最大长度,可在查询分析页面底部设置统计字段(text)最大长度,取值范围为64~16384字节。重要更新索引配置只对增量数据有效。
如果单个字段值长度超过最大长度,超出部分将被截断,不参与分析。

API方式
SDK方式
CLI方式
更新索引
操作步骤
在目标Logstore的查询和分析页面,选择。不同的索引配置,会产生不同的查询和分析结果,请根据您的需求,合理更新索引。更新索引后需要大约一分钟生效。

关闭索引
关闭索引后,历史索引的存储空间将在当前Logstore的数据保存时间到期后,自动被清除。
操作步骤
在目标Logstore的查询和分析页面,选择。

索引配置示例
示例1
日志内容中有request_time字段,执行字段查询语句request_time>100。
只建立全文索引,返回同时包含
request_time、>(非分词符)、100这三个词的日志。只建立double、long类型的字段索引,返回结果是
request_time大于100的日志。建立全文索引和double、long类型的字段索引,
request_time的全文索引失效,返回结果是request_time大于100的日志。
示例2
日志内容中有request_time字段,执行全文查询语句request_time。
只建立double、long类型的字段索引,无法查询到相关日志。
只建立全文索引,从所有日志文本中查询包括
request_time的日志。只建立text类型的字段索引,从字段索引是text类型的字段中查询包括
request_time的日志。
示例3
日志内容中有status字段,执行分析语句* | SELECT status, count(*) AS PV GROUP BY status。
只建立全文索引,无法查询到相关日志。
为
status建立字段索引,返回结果是不同的状态码及对应的PV总数。
索引流量说明
全文索引
所有字段名和字段值都将作为text类型存储,即字段名和字段值都被计入索引流量。
字段索引
不同数据类型的字段的索引流量计算方式不同。
text类型:字段名和字段值都被计入索引流量中。
long类型和double类型:字段名不计入索引流量中,每个字段值所占的索引流量统一为8字节。
例如对
status字段设置了索引(long类型),字段值为200,则字符串status不会被计入在索引流量中,200的索引流量统一为8字节。JSON类型:字段名和字段值都被计入到索引流量中,包括未被创建索引的子节点。更多信息,请参见如何计算JSON类型字段的索引流量。
如果未对子节点设置索引,则其索引流量按照text类型进行计算。
如果对子节点设置了索引,则其索引流量按照其子节点数据类型(text、long或double)进行计算。
计费说明
按写入数据量计费的logstore
创建的索引会占用存储空间,存储类型请参见管理智能存储分层。
重建索引不产生费用。
索引流量计费请参见按写入数据量计费模式计费项。
按使用功能计费的logstore
创建的索引会占用存储空间,存储类型请参见管理智能存储分层。
创建索引会产生流量,索引流量计费请参见按使用功能计费模式计费项中的索引流量-日志索引和索引流量-日志索引-查询型。降低索引流量的建议,请参见如何降低索引流量费用?。
重建索引会产生费用。计费项、计费价格和创建索引相同。
后续步骤
查询和分析的示例,请参见:
优化查询的方法,请参见提高查询分析日志速度的方法。
查询和分析JSON类型的网站日志,请参见查询和分析JSON日志。