Nginx日志是运维网站的重要信息,日志服务支持通过Nginx模式快速采集Nginx日志并进行多维度分析。本文介绍如何通过日志服务控制台创建Nginx配置模式的Logtail配置采集日志。
方案概览
在Nginx配置模式下,Logtail会根据log_format中的定义将日志内容结构化。Nginx访问日志相关的主要指令为log_format和access_log,通常在配置文件/etc/nginx/nginx.conf中配置。log_format用来定义日志格式;access_log用来指定日志文件的存放路径。
日志格式和存放路径
log_format和access_log的默认值如下所示。
log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$request_time $request_length ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent"'; access_log /var/log/nginx/access.log main;日志字段说明如下所示:
字段名称
说明
remote_addr
客户端IP地址。
remote_user
客户端用户名。
time_local
服务器时间,前后必须加上中括号([])。
request
请求的URI和HTTP协议。
request_time
整个请求的总时间,单位为秒。
request_length
请求的长度,包括请求行、请求头和请求正文。
status
请求状态。
body_bytes_sent
发送给客户端的字节数,不包括响应头的大小。
http_referer
URL跳转来源。
http_user_agent
客户端浏览器等信息。
原始日志
Nginx根据log_format的定义生成日志:
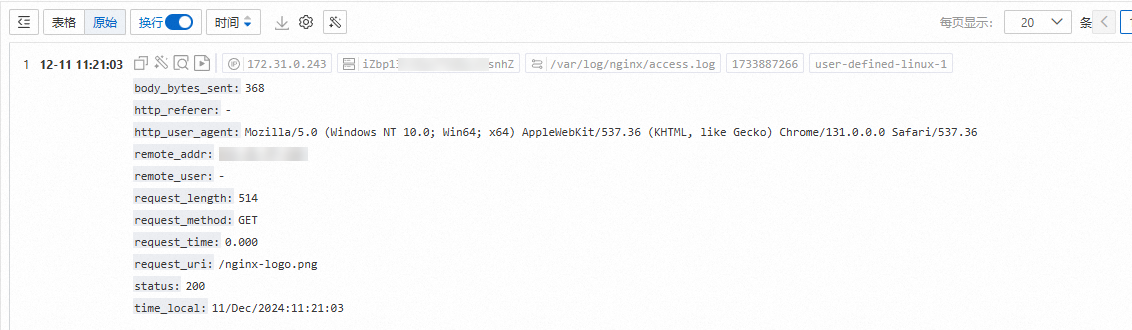
192.168.1.1 - - [11/Dec/2024:11:21:03 +0800] "GET /nginx-logo.png HTTP/1.1" 0.000 514 200 368 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"被采集到日志服务LogStore中的日志:
前提条件
已创建Logtail机器组并添加相应服务器,创建机器组的步骤,请参见创建用户自定义标识机器组和创建IP地址机器组。
服务器具备访问远端服务器80端口和443端口的能力,确保Logtail能够将日志数据发送给日志服务。
服务器日志的内容持续新增。Logtail只采集增量日志,如果下发Logtail配置后日志文件无更新,则Logtail不会采集该文件中的日志。更多信息,请参见采集流程。
操作步骤
登录日志服务控制台。
在Project列表区域,单击目标Project。
在页签中,单击目标Logstore。
展开LogStore选项卡,单击Logtail配置,然后单击添加Logtail配置。
在弹出的快速数据接入页面中,选择。
在机器组配置步骤中,选择已创建的机器组。
在Logtail配置步骤中,配置以下选项。
配置名称:输入Logtail采集配置名称,例如
nginx-logs。文件路径:输入日志的存放路径,例如
/var/log/nginx/**/access*表示/var/log/nginx目录(包含该目录的递归子目录)中以access开头的文件。处理配置:单击NGINX模式解析,在弹出的处理插件页签中,输入标准NGINX配置文件日志配置部分,通常以log_format开头。日志服务将自动提取对应字段。例如:
log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$request_time $request_length ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent"';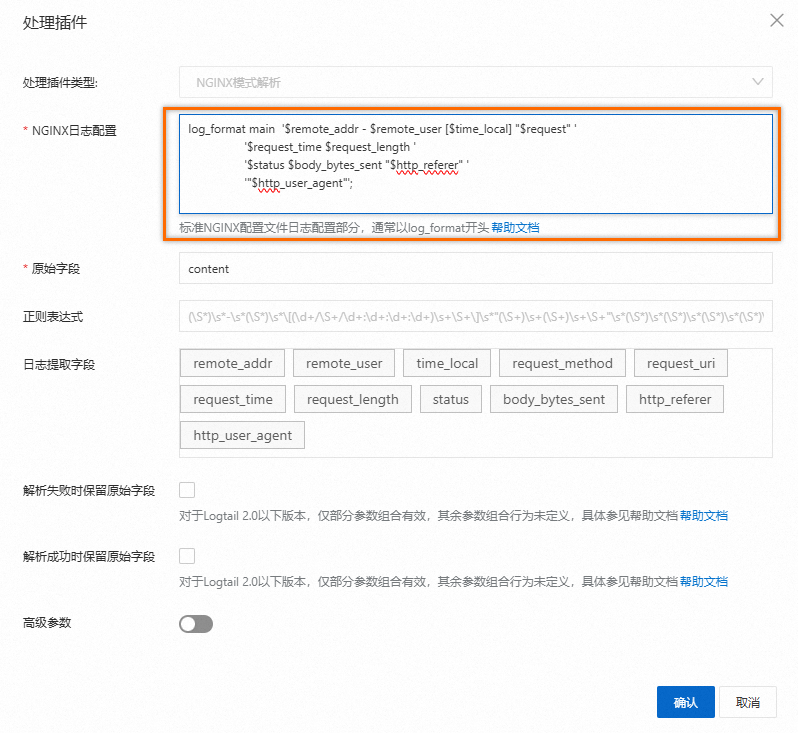
其他配置项保持默认即可。如需了解更多配置信息,请参见采集主机文本日志。
在查询分析配置步骤中,单击刷新,可预览采集到的数据。
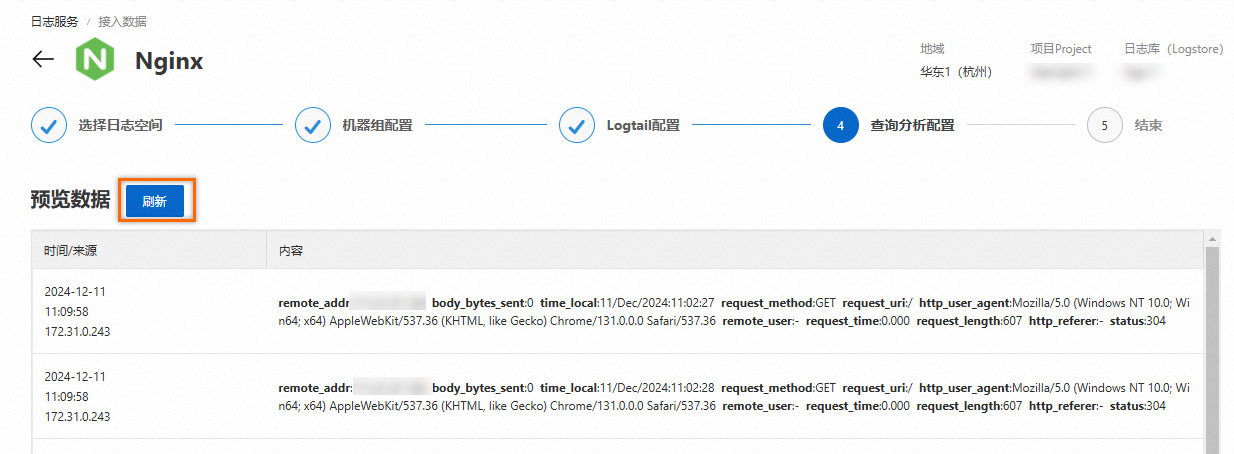
单击下一步,结束配置流程。您可在此单击查询日志,系统将跳转至LogStore查询分析页面。您需要等待1分钟左右,待索引生效后,才能在原始日志页签中,查看已采集到的日志。更多信息,请参见查询与分析快速指引。
相关文档
日志服务为Linux系统提供Logtail自动诊断工具,可以根据工具提示快速定位并解决问题。请参见Logtail自动诊断工具。
使用Logtail采集日志后,如果预览页面为空或查询页面无数据,请按照Logtail采集日志失败的排查思路进行排查。
在使用Logtail采集日志时,可能遇到正则解析失败、文件路径不正确、流量超过Shard服务能力等错误。查看Logtail采集错误的步骤,请参见如何查看Logtail采集错误信息。采集数据常见的错误类型请参见日志服务采集数据常见的错误类型。
默认情况下,一个日志文件只能匹配一个Logtail配置。如果同一份日志需要被采集多份,请参见如何实现文件中的日志被采集多份。
将企业内网服务器日志采集到日志服务,请参见采集企业内网服务器日志。
不同服务器上的日志的保存路径或文件名相同,需要区分不同服务器,请参见日志主题。区分不同用户或实例产生的日志数据,请参见日志主题。
分析网站访问情况、诊断及调优网站和重要场景告警,请参见分析Nginx访问日志。