RDS SQL Server提供了增量备份上云的解决方案。您需要先将全量备份文件上传至阿里云的对象存储服务(OSS),并通过RDS控制台将全量备份数据恢复至指定的RDS SQL Server数据库中。然后通过RDS控制台将差异备份或日志备份文件导入该RDS SQL Server数据库中,以实现增量备份上云的效果。该方案能够将业务中断时间控制在分钟级别,从而有效缩短业务中断时间。
适用场景
RDS SQL Server增量数据上云适用于以下场景:
基于备份文件物理迁移至RDS SQL Server,而不是逻辑迁移。
说明物理迁移是指基于文件的迁移,逻辑迁移是指将数据生成DML语句写入RDS SQL Server。
物理迁移可做到数据库迁移后和本地环境100%一致。逻辑迁移无法做到100%一致,例如索引碎片率、统计信息等。
对业务停止时间敏感,需要将业务中断时间控制在分钟级别。
说明如果您对业务停止时间不是非常敏感(例如可以接受2小时的中断),当数据库小于100 GB时,建议您通过全量备份文件上云。
前提条件
RDS SQL Server实例需满足如下条件:
实例版本为SQL Server 2012及以上版本,或SQL Server 2008 R2云盘。
实例中没有与待上云数据库名称相同的数据库。
实例剩余空间需大于待上云的数据文件。若空间不足,请提前升级实例空间。
本地SQL Server数据库的恢复模式需要设置为
FULL模式。说明在进行增量备份数据上云时,需要进行事务日志备份,而Simple模式下不允许进行事务日志备份。
如果差异备份文件很大,可能会导致增量备份上云的时间变长。
如果通过RAM用户登录,需满足以下条件:
RAM账号具备AliyunOSSFullAccess权限和AliyunRDSFullAccess权限。如何为RAM用户授权,请参见通过RAM对OSS进行权限管理和通过RAM对RDS进行权限管理。
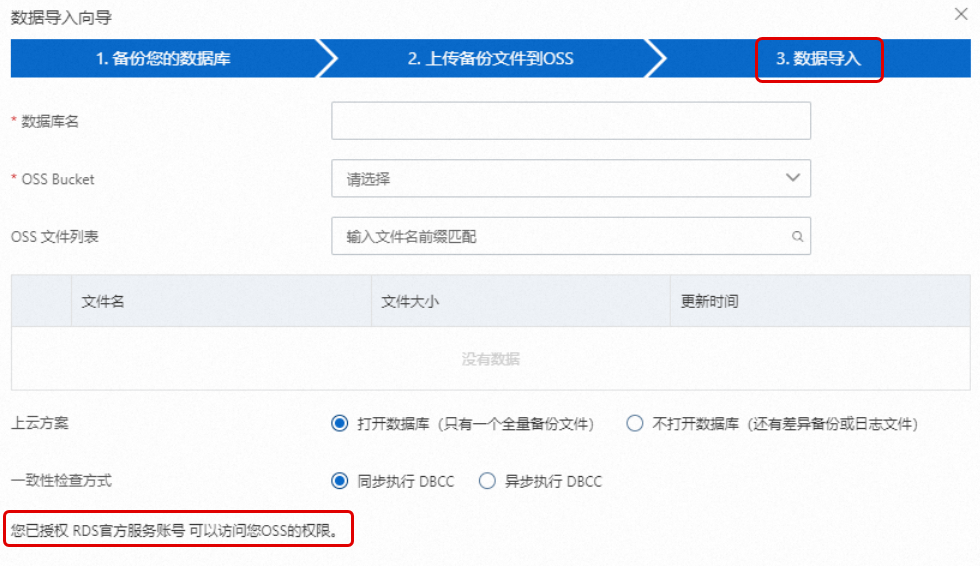
阿里云账号(主账号)已授权RDS官方服务账号可以访问您OSS的权限。
前往RDS实例详情页备份恢复页面,单击OSS备份数据恢复上云按钮。
在数据导入向导页面单击两次下一步,进入3. 数据导入步骤。
若该页面左下角显示您已授权RDS官方服务账号可以访问您OSS的权限,则表示已授权。否则表示还未授权,单击该页面的授权地址同意授权即可。
所在阿里云账号(主账号)需手动创建权限策略,然后将权限添加到RAM账号中。
准备工作
在本地数据库环境中执行DBCC CHECKDB语句,以确保数据库中没有任何的allocation errors和consistency errors。正常执行结果如下:
...
CHECKDB found 0 allocation errors and 0 consistency errors in database 'xxx'.
DBCC execution completed. If DBCC printed error messages, contact your system administrator.注意事项
迁移级别:本方案仅支持单个数据库的迁移。如需迁移多个或所有数据库,请参见SQL Server实例级别迁移上云。
版本兼容性:备份文件所在本地SQL Server版本不支持迁移到低版本RDS SQL Server实例。
权限管理:授予RDS服务账号访问OSS权限后,系统会在访问控制RAM的角色管理中创建名为
AliyunRDSImportRole的角色,请勿修改或删除该角色,否则会导致上云任务失败。若误操作,需通过数据上云向导重新授权。账号管理:迁移完成后,原有数据库账号无法使用,需在RDS控制台重新创建账号。
OSS文件保留:在上云任务完成前,请勿删除OSS上的备份文件,否则会导致任务失败。
备份文件要求:
文件名限制:文件名不得包含特殊字符(如
!@#$%^&*()_+-=),否则会导致上云失败。文件后缀:RDS支持的备份文件为
.bak(全量备份)、.diff(差异备份)、.trn或.log(日志备份),系统无法识别其他文件类型。说明实际使用时,并非严格要求每种备份类型必须对应其格式后缀,例如
.bak可代表全量备份、差异备份或事务日志备份。对于通过RDS控制台下载的SQL Server日志备份文件(而非本文步骤一官方脚本生成的
.bak备份文件),该文件默认格式为.zip.log,格式处理后可直接用于增量上云。处理方法:先将文件扩展改为
.zip以解压,再将解压得到的database_name.lbak重命名为.bak格式,最后上传此.bak文件到OSS中作为增量日志备份进行上云。
操作流程举例
上云阶段 | 步骤 | 说明 |
全量阶段 | Step1. 00:00之前 | 完成准备工作,包括:
|
Step2. 00:01 | 开始对线下数据库做FULL Backup,耗时近1小时。 | |
Step3. 02:00 | 上传备份文件到OSS Bucket,耗时近1小时。 | |
Step4. 03:00 | 开始在RDS控制台恢复FULL Backup文件,耗时19小时。 | |
增量阶段 | Step5. 22:00 | 开始数据库增量LOG备份上云,完成LOG备份并上传至OSS,耗时约20分钟。 |
Step6. 22:20 | 完成LOG Backup上云,耗时约10分钟。 | |
Step6. 22:30 |
| |
打开数据库 | Step8. 22:34 | 完成了最后一个LOG Backup文件增量上云操作,耗时4分钟,开始将数据库上线。 |
Step9. 22:35 | 数据库上线完毕,如果选择异步执行DBCC操作,上线速度快,耗时1分钟。 |
从整个的动作流程和时间轴来看,用户需要停止应用的时间非常的短,仅在最后一个LOG Backup之前停止应用写入即可。在本例中整个应用停止的时间控制在5分钟内。
1. 备份本地数据库
下载备份脚本,用SSMS打开备份脚本。
修改如下参数。
配置项
说明
@backup_databases_list
需要备份的数据库,多个数据库以分号或者逗号分隔。
@backup_type
备份类型。参数值如下:
FULL:全量备份
DIFF:差异备份
LOG:日志备份
@backup_folder
备份文件所在的本地目录。如不存在,会自动创建。
@is_run
是否执行备份。参数值如下:
1:执行备份。
0:只做检查,不执行备份。
执行备份脚本。
无论指定何种备份类型,本脚本均默认生成
.bak格式文件。
2. 上传备份文件到OSS
将备份文件上传至OSS前,您需先在OSS中创建存储空间Bucket。
若OSS中已存在Bucket,请确保该Bucket满足以下要求:
若OSS中没有Bucket,需要先行创建。(请确保已开通OSS服务)
登录OSS管理控制台,单击Bucket列表,然后单击创建Bucket。
配置如下关键参数,其他参数可以保持默认。
重要创建的存储空间主要用于本次数据上云,只需配置关键参数即可,上云完成后可以及时删除以避免数据泄露及产生相关费用。
创建Bucket时请勿开启数据加密。
参数
说明
取值示例
Bucket 名称
存储空间名称,全局唯一,设置后无法修改。
命名规则:
只能包括小写字母、数字和短划线(-)。
必须以小写字母或者数字开头和结尾。
长度必须在3~63字符之间。
migratetest
地域
Bucket所属的地域,如果您通过ECS内网上传数据至Bucket中,且通过内网将数据恢复至RDS中,则需要三者地域保持一致。
华东1(杭州)
存储类型
选择标准存储。本文上云操作不支持其他存储类型的Bucket。
标准存储
上传备份文件到OSS。
本地数据库备份完成后,请将备份文件上传到与您的RDS实例同地域的OSS Bucket中,两者处于同一地域时可通过内网互通(不会产生外网流量费用),且数据上传速度更快。您可以采用如下方法之一:
下载ossbrowser。
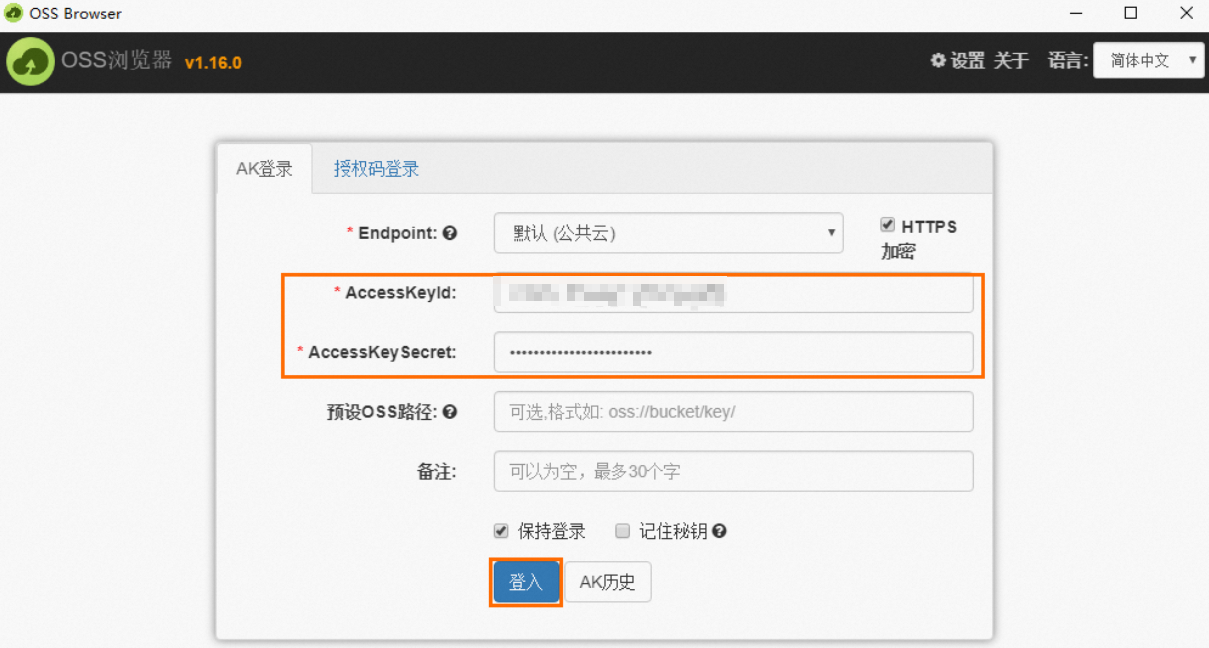
以Windows x64操作系统为例,解压下载的
oss-browser-win32-x64.zip压缩包,双击运行oss-browser.exe应用程序。使用AK登录方式,配置参数AccessKeyId和AccessKeySecret,其他参数保持默认,然后单击登入。
说明AccessKey用于身份验证,确保数据安全,请妥善保管。
单击目标Bucket,进入存储空间。

单击
 ,选择需要上传的备份文件,然后单击打开,即可将本地文件上传至OSS中。
,选择需要上传的备份文件,然后单击打开,即可将本地文件上传至OSS中。
说明如果备份文件小于5 GB,建议您直接通过OSS控制台上传备份文件。
登录OSS管理控制台。
单击Bucket列表,然后单击目标Bucket名称。
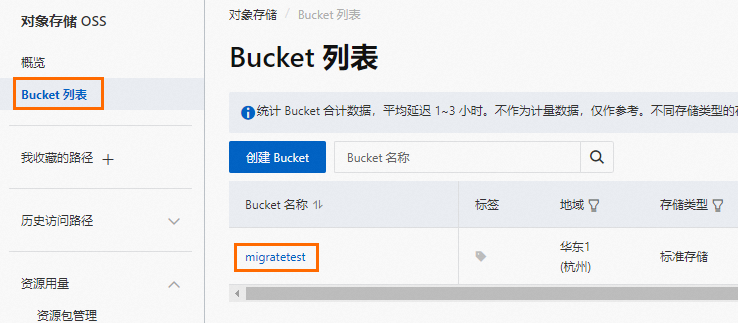
在文件列表中,单击上传文件。
您可以将备份文件拖拽至待上传文件区域,也可以单击扫描文件,选择需要上传的备份文件。
单击页面下方的上传文件,即可将本地备份文件上传至OSS中。
3. 创建数据上云任务
访问RDS实例列表,在上方选择地域,然后单击目标实例ID。
在左侧菜单栏中选择备份恢复。
单击页面上方的OSS备份数据恢复上云。
在数据导入向导页面,单击两次下一步,进入数据导入步骤。
说明首次使用OSS备份数据恢复上云功能,需授权RDS账号访问OSS,请单击授权地址并同意授权,否则会因权限问题导致OSS Bucket下拉列表为空。
设置如下参数,单击确定。
请耐心等待上云任务完成,您可以单击刷新查看数据上云任务最新状态。如上云任务失败,请根据任务描述提示排查错误,具体可参见本文常见错误。
配置项
说明
数据库名
备份数据导入目标RDS实例上的数据库名,名称需要符合SQL Server官方限制。
重要进行上云操作前,请确保目标实例上不存在与备份文件指定要还原的数据库名称相同的数据库,也不存在相同名称的未附加数据库文件。若都不存在,则可以使用备份集中同名数据库文件名称还原数据库。
如果目标实例上存在与备份文件指定要还原的数据库名称相同的数据库,或者存在同名的未附加数据库文件,上云操作将失败。
OSS Bucket
选择备份文件所在的OSS Bucket。
OSS文件列表
单击右侧放大镜按钮,可以按照备份文件名前缀模糊查找,会展示文件名、文件大小和更新时间。请选择需要上云的备份文件。
上云方案
选择不打开数据库。
打开数据库(只有一个全量备份文件):全量上云,适合仅有一个完全备份文件上云的场景。此时CreateMigrateTask中的
BackupMode = FULL并且IsOnlineDB = True。不打开数据库(还有差异备份或日志文件):增量上云,适合有完全备份文件加上日志备份(或者差异备份文件)上云的场景。此时CreateMigrateTask 中的
BackupMode = UPDF并且IsOnlineDB = False。
4. 导入差异或日志备份文件
SQL Server本地数据库全量备份上云完成后,接下来需要导入差异备份或者日志备份文件。
访问RDS实例列表,在上方选择地域,然后单击目标实例ID。
在左侧菜单栏中选择备份恢复,单击备份数据上云记录页签。
在任务列表中找到待导入备份文件的记录,在右侧单击上传增量文件,选择增量文件后单击确认。
说明如果您有多个日志备份文件,请使用同样的方法逐个生成上云任务。
请在上传增量文件时,尽量保证最后一个备份文件的大小不超过500MB,以此来缩短增量上云的时间开销。
在最后一个日志备份文件生成前,请停止本地数据库所有的写入操作,以保证线下数据库和RDS SQL Server上的数据库数据一致。
5. 打开数据库
导入文件后RDS SQL Server中的数据库会处于In Recovery或者Restoring状态。高可用系列会处于In Recovery状态,单机版会处于Restoring状态,此时的数据库还无法进行读写操作,需要打开数据库。
访问RDS实例列表,在上方选择地域,然后单击目标实例ID。
在左侧菜单栏中选择备份恢复,单击备份数据上云记录页签。
在任务列表中找到待导入备份文件的记录,在右侧单击打开数据库。
选择数据库的打开方式,单击确定。
说明打开数据库一致性检查有以下两种方式:
异步执行DBCC:在打开数据库的时候系统不做DBCC CheckDB,会在打开数据库任务结束以后,异步执行DBCC CheckDB操作,以此来节约打开数据库操作的时间开销(数据库比较大,DBCC CheckDB非常耗时),减少您的业务停机时间。如果您对业务停机时间要求非常敏感,且不关心DBCC CheckDB结果,建议使用异步执行DBCC。此时CreateMigrateTask 中的
CheckDBMode = AsyncExecuteDBCheck。同步执行DBCC:相对于异步执行DBCC,有的用户非常关心DBCC CheckDB的结果,以此来找出用户线下数据库数据一致性错误。此时,建议您选择同步执行DBCC,影响是会拉长打开数据库的时间。此时CreateMigrateTask 中的
CheckDBMode = SyncExecuteDBCheck。
6. 查看上云任务备份文件详情
访问RDS实例左侧导航栏备份恢复页面,在备份数据上云记录页签内查看备份上云记录,单击对应任务最右侧的查看文件详情,将展示对应任务所有关联的备份文件详情。
常见错误
全量备份数据上云中常见错误,请参见全量备份数据上云-常见错误。
您在增量上云过程中,可能会遇到如下的错误:
数据库打开失败
错误信息:Failed to open database xxx.
错误原因:线下SQL Server数据库启用了一些高级功能,如果用户选择的RDS SQL Server版本不支持这些高级功能,会导致数据库打开失败。例如本地SQL Server数据库是企业版,启用了数据压缩(Data Compression)或者分区(Partition),OSS上云到RDS SQL Server Web版,就会报告这个错误。
解决方法:
在本地SQL Server实例上禁用高级功能,重新备份后,再使用OSS上云功能。
购买与线下SQL Server实例相同版本的RDS SQL Server。购买方法,请参见创建并使用RDS SQL Server实例。
说明更多详情,请参见RDS SQL Server各版本的功能差异。
数据库备份链中LSN无法对接
错误信息:The log in this backup set begins at LSN XXX, which is too recent to apply to the database.RESTORE LOG is terminating abnormally.
错误原因:在SQL Server数据库中,差异备份或者日志备份能够成功还原的前提是,差异或者日志备份的LSN必须与上一次还原的备份文件LSN能够对接上,否则就会报告这个错误。
解决方法:请选择对应的LSN备份文件进行增量备份文件上云,您可以按照备份文件备份操作时间先后顺序进行增量上云操作。
异步DBCC Checkdb失败
错误信息:asynchronously DBCC checkdb failed: CHECKDB found 0 allocation errors and 2 consistency errors in table 'XXX' (object ID XXX).
错误原因:备份文件还原到RDS SQL Server上,上云任务系统会异步做DBCC CheckDB检查,如果检查不通过,说明本地数据库中已经有错误发生。
解决方法:
在RDS SQL Server上执行:
DBCC CHECKDB (DBName,REPAIR_ALLOW_DATA_LOSS)重要使用该命令修复错误的过程,可能会导致数据丢失。
在本地使用如下命令修复错误后重新进行增量上云。
DBCC CHECKDB (DBName,REPAIR_ALLOW_DATA_LOSS)
完全备份文件类型
错误信息:Backup set (xxx) is a Database FULL backup, we only accept transaction log or differential backup.
错误原因:在增量上云RDS SQL Server过程中,全量备份文件还原完毕后,就只能再接受日志备份文件或者是差异备份文件。如果用户再次选择了全量备份文件,就会报告这个错误。
解决方法:选择日志备份文件或者差异备份文件。
数据库个数超出最大限制数
错误信息:The database (xxx) migration failed due to databases count limitation.
错误原因:当数据库达到数量限制以后再做上云操作,任务会失败报告这个错误。
解决方法:迁移上云数据库到其他的RDS SQL Server,或者删除不必要的数据库。
RAM账号操作权限不足
Q1:执行创建数据上云任务步骤5使,各配置项参数均已填写完整,但确定按钮为灰色无法单击?
A1:无法单击的原因可能是您为RAM用户,您的账号权限不足。请参见本文前提条件,确保相应权限已授予。
Q2:使用RAM子账号进行
AliyunRDSImportRole授权时提示没有权限如何解决?A2:使用阿里云主账号为RAM子账号临时增加
AliyunRAMFullAccess权限解决。如何为RAM用户授权,请参见通过RAM对RDS进行权限管理。
相关API
API | 描述 |
将OSS上的备份文件还原到RDS SQL Server实例,创建数据上云任务。 | |
打开RDS SQL Server备份数据上云任务的数据库。 | |
查询RDS SQL Server实例备份数据上云任务列表。 | |
查询RDS SQL Server备份数据上云任务的文件详情。 |