本文将为您介绍如何使用弹性并行查询(Elastic Parallel Query,简称ePQ)。
注意事项
请确认您的集群是否支持使用弹性并行查询。
单机并行:
数据库引擎版本为8.0.1,内核小版本需为8.0.1.0.5及以上。
产品版本:企业版。
单机并行:
数据库引擎版本为8.0.2,内核小版本需为8.0.2.1.4.1及以上。
产品版本:企业版。
多机并行:
数据库引擎版本为8.0.2,内核小版本需为8.0.2.2.6及以上。
产品版本:企业版。
并行查询存在使用限制和兼容性问题。具体信息,请参见使用限制和兼容性问题。
只读节点和主节点都支持并行查询功能,但主节点上的并行查询默认关闭,您可以根据实际业务情况进行调整。具体信息,请参考自适应调整并行度。
开启/关闭并行查询
开启
您可前往。在集群基本信息页面的数据库连接区域,选择目标地址,单击配置。在编辑地址配置弹窗内,开启并行查询并配置并行度。
登录PolarDB控制台,在左侧导航栏单击集群列表,选择集群所在地域,并单击目标集群ID进入集群详情页。
集群基本信息页面的数据库连接区域,选择目标地址,单击配置。
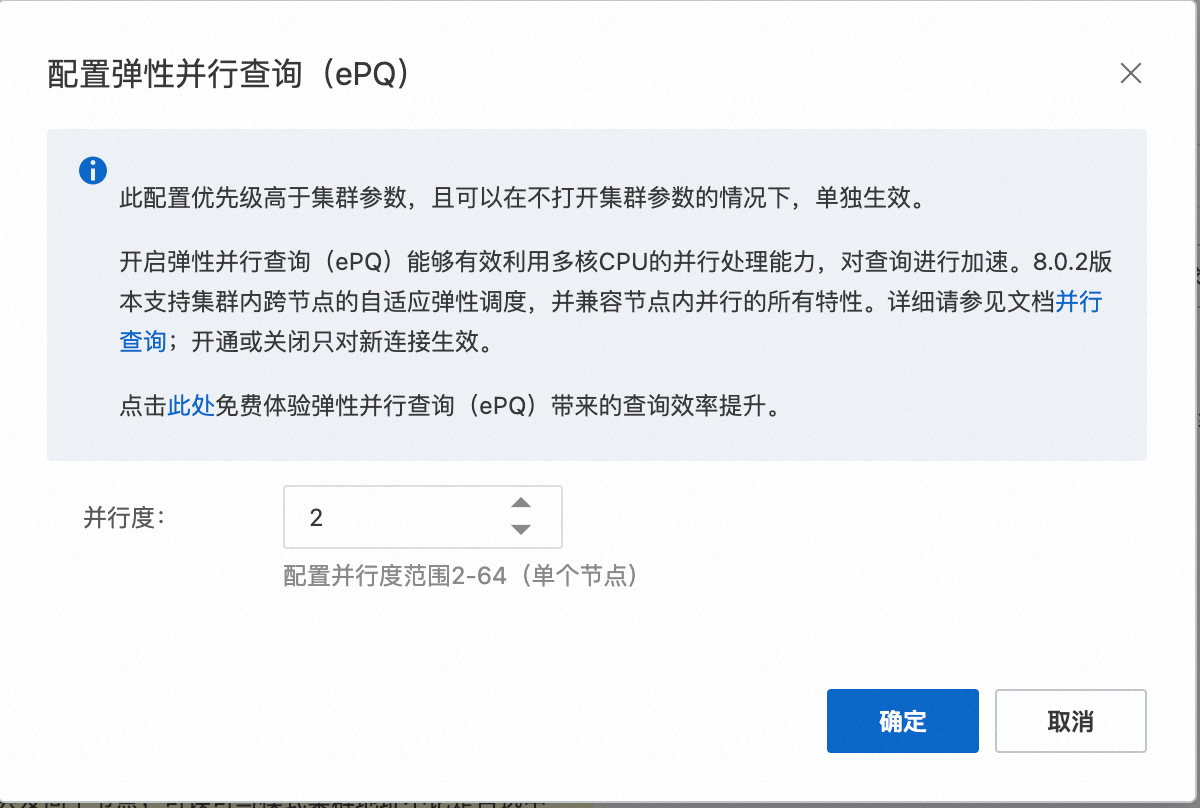
在编辑地址配置弹窗内,开启并行查询并配置并行度。其他参数说明,请参见配置数据库代理。
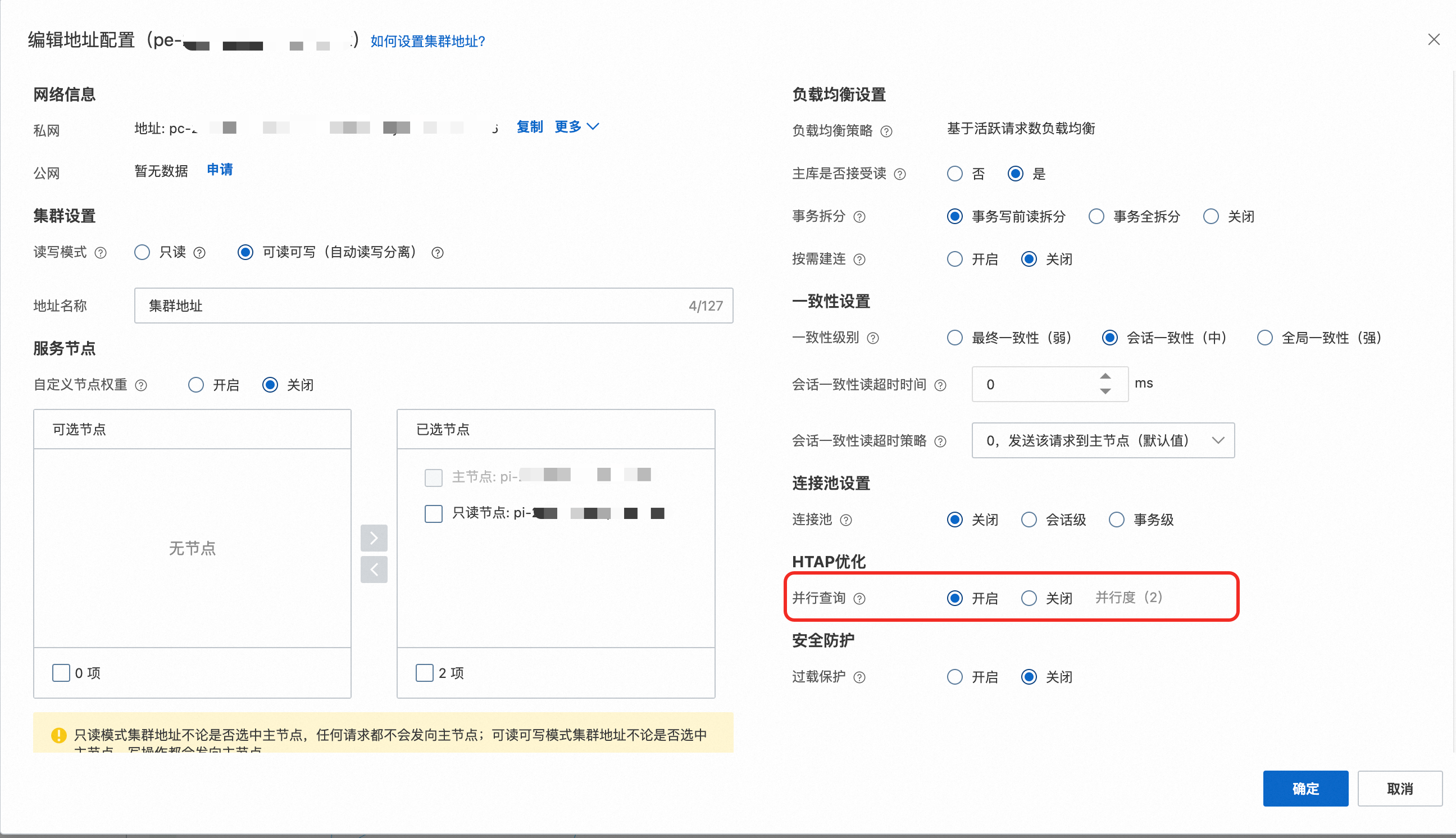
推荐设置与说明:
并行度是指单个查询在单个计算节点内最大允许同时运行的worker线程数。单个查询最大允许同时运行的线程数=并行度×节点个数。
并行度建议从低到高逐步增加,且不要超过CPU核数的四分之一 。例如,刚开始使用并行查询时,建议将并行度参数设置为2。经过一天的试运行后,如果CPU负载较低,可以继续上调并行度;若出现较大的CPU负载,应停止上调。
开启并行查询仅对新连接生效。
控制台中的并行查询设置与集群参数说明如下:
系统参数
loose_max_parallel_degree适用于当前集群的所有节点,对集群中所有连接均有效。然而,在控制台中进行的调整仅对当前设置的连接地址生效。若控制台和系统参数
loose_max_parallel_degree同时存在时,以控制台配置为准。因此,建议使用控制台来开启并行查询。若控制台未开启并行查询,但系统参数
loose_max_parallel_degree被设置为大于0时,相当于默认开启了单机并行。
说明loose_max_parallel_degree参数为单个查询的最大并行度,即并行执行的最大Worker数量。具体信息,请参见参数说明。
关闭
您可前往。在集群基本信息页面的数据库连接区域,选择目标地址,单击配置。在编辑地址配置弹窗内,关闭并行查询。
登录PolarDB控制台,在左侧导航栏单击集群列表,选择集群所在地域,并单击目标集群ID进入集群详情页。
集群基本信息页面的数据库连接区域,选择目标地址,单击配置。
在编辑地址配置弹窗内,关闭并行查询。
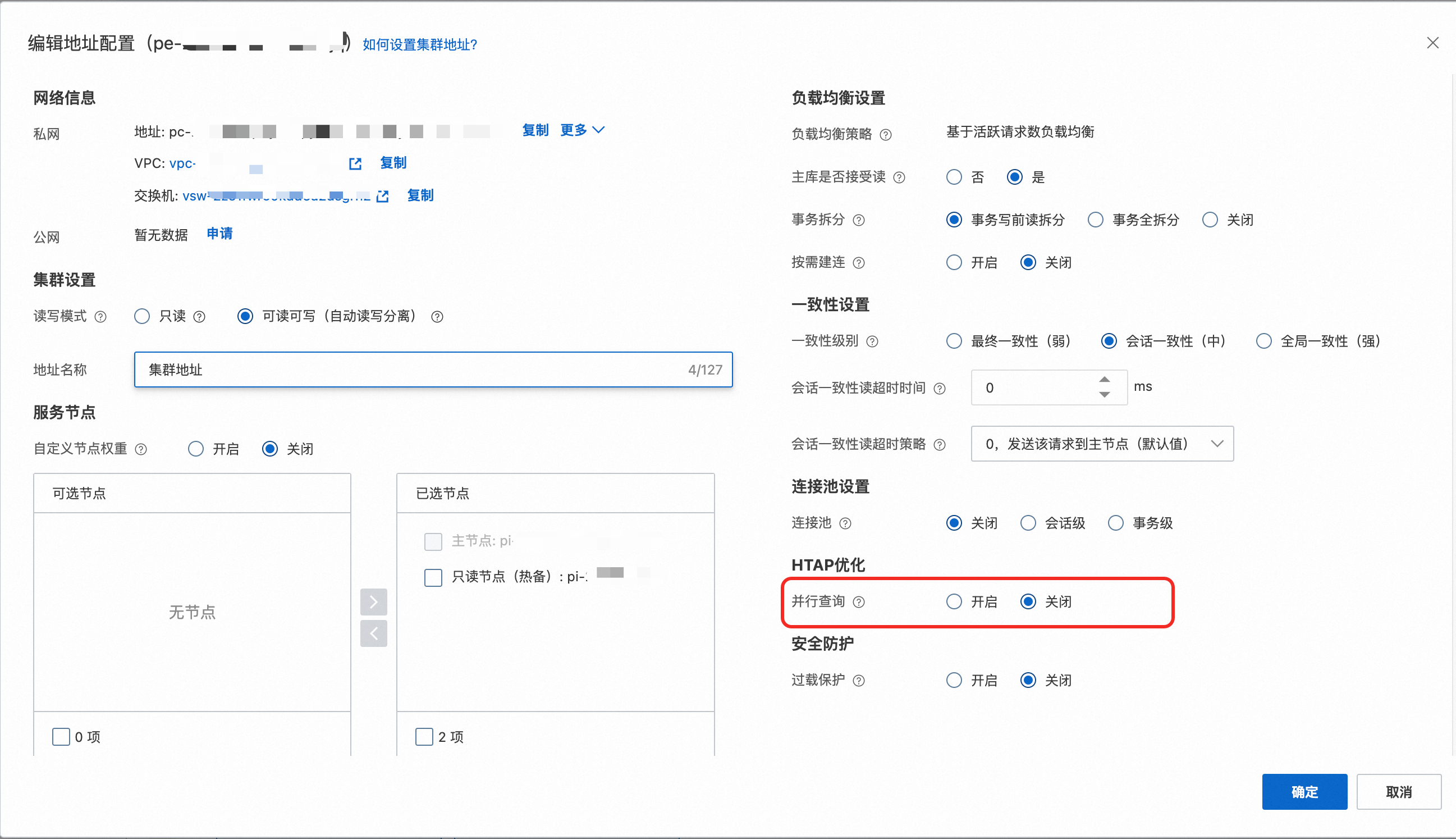
说明:
关闭并行查询仅对新连接生效。
控制台关闭并行查询后,需要确认系统参数
loose_max_parallel_degree同时为0,确保并行查询被完全关闭。说明loose_max_parallel_degree参数为单个查询的最大并行度,即并行执行的最大Worker数量。具体信息,请参见参数说明。
并行查询配置
并行查询有多个控制参数。为便于您对并行查询进行管理,PolarDB提供了多种控制策略。以下列出部分控制策略。更多信息,请参见并行资源控制策略配置。
类型 | 说明 |
控制优化器是否选择并行执行 | PolarDB为您提供了两个阈值来控制优化器是否选择并行执行,SQL语句只要满足其中任意一个条件,优化器就会考虑并行执行。
|
控制多机并行引擎的自适应弹性调度 | PolarDB为您提供了两个阈值来控制是否选择多机并行,SQL语句只要满足如下任意一个条件,并行查询会考虑弹性扩展为多机并行。
|
通过Hint来控制并行查询
使用Hint语法可以对单个语句进行控制,指定优化器是否选择并行执行,并支持设置并行度以及需要并行的表。例如,在系统默认关闭并行查询的情况下,如果需要对某个高频的慢SQL查询进行加速,可以使用Hint对特定SQL进行加速。具体信息,请参见并行查询Hint语法。
使用限制和兼容性问题
使用限制
PolarDB会持续迭代并行查询的能力,目前以下情况在并行计划中会有一定的局限性:
查询非
InnoDB表,查询无法并行。使用全文索引的查询,查询无法并行。
包含存储过程
Procedures的表达式,该表达式必须在Leader上执行。Index Merge方式进行表扫描,则该表无法并行。串行化隔离级别事务内的查询语句无法并行。
隔离级别是
Repeatable-read的情况下,事务内的INSERT ... SELECT/REPLACE ... SELECT查询部分无法并行。
兼容性
错误提示次数可能会变化
串行执行中出现错误提示的查询,在并行执行的情况下,总体错误提示数可能会与串行有所不同。
精度问题
在并行查询的执行过程中,可能会出现比串行执行多出中间结果存储的情况,如果中间结果是浮点型,可能会导致浮点部分的精度差异,从而使最终结果出现细微的差别。
网络包或者中间结果长度超出
max_allowed_packet允许的最大长度在并行查询的执行过程中,相比串行执行可能会多出中间结果。如果中间结果的长度超出了
max_allowed_packet定义的最大长度,可能出现错误提示,可以通过增加max_allowed_packet参数的值来解决。如何修改参数请参见设置集群参数和节点参数。结果集顺序差别
当并行查询执行未加
ORDER BY关键字的SELECT ... LIMIT n语句时,返回的结果集可能与执行顺序不一致。由于有多个Worker同时执行,每次执行时Worker的执行速度是不确定的,当Leader得到足够的数据后,就会返回结果,因此返回的结果集可能与执行顺序不一致。加了行锁的数据记录数增多
当并行执行
SELECT ... FROM ... FOR SHARE语句时,InnoDB会将访问到的每一行数据都加锁,因此加了行锁的记录数可能会比非并行执行的情况下要多,这属于正常现象。