ComfyUI提供基于Stable Diffusion的节点式操作界面,通过拖拽节点和连接的方式构建复杂的AIGC流程,完成短视频内容生成、动画制作等任务。本文介绍如何在EAS中部署和使用ComfyUI。
开始之前
重要限制与注意事项
部署前必读:了解以下关键限制,以避免不必要的资源浪费和常见错误。
部署资源:推荐使用GU30、A10或T4卡型,其中
ml.gu7i.c16m60.1-gu30性价比高。重要每个 EAS 实例仅运行一个 ComfyUI 进程,仅支持单张 GPU(单机单卡或多机单卡),不支持多卡并行推理。请勿选择多卡 GPU 规格(如
2*A10等),这会造成资源浪费且无法提升单任务的性能。水平扩展方式:如需提升并发处理能力,请使用API版并增加副本数量,而非选择多卡规格。
存储准备:如需使用自定义模型、安装自定义节点或通过API调用,必须提前创建OSS存储空间或NAS文件系统。详见对象存储OSS快速入门。
EAS 不支持通过 ComfyUI 管理器或 Git Clone 等方式从网络直接安装自定义节点(插件)。所有自定义内容都必须通过挂载存储的方式上传。
Serverless 版核心限制:
仅可使用内置模型和插件。如需上传自定义模型或安装第三方节点,请选择标准版、API版或集群版。
仅在华东2(上海)、华东1(杭州)地域可用。
选择部署版本
根据使用场景选择合适的版本:
部署版本 | 适用场景 | 调用方式 | 主要特点 | 计费模式 |
标准版 | 单用户开发和测试 |
|
| 按照服务的运行时长计费(部署成功后即使不使用也计费)。 |
API版 | 生产环境高并发 | API调用(异步) |
| |
集群版WebUI | 多用户团队和教学 | WebUI |
原理参见集群版服务原理介绍 | |
Serverless版 | 波动性工作负载,成本优化 | WebUI |
| 部署免费,仅在服务调用时按实际推理实时长计费。 |
更多计费详情请参见模型在线服务(EAS)计费说明。
此处API调用的同步与异步取决于是否使用EAS的队列服务:
同步调用:直接请求推理实例,不使用EAS的队列服务;
异步调用:使用EAS的队列服务,向输入队列发送请求,以订阅的方式获得结果推送。
由于ComfyUI本身具有异步队列系统,即使发起同步调用,实质上也是异步进行的。用户发送请求后,系统会返回一个Prompt ID,然后需要使用Prompt ID轮询以获取推理结果。
部署服务
Serverless版:只能使用场景化模型部署。
标准版、集群版、API版:可使用场景化模型部署(操作简单)或者自定义模型部署(支持更多功能)。
方式一:场景化模型部署(推荐)
登录PAI控制台,在页面上方选择目标地域,并在右侧选择目标工作空间,然后单击进入EAS。
在模型在线服务 (EAS)页面,单击部署服务,在场景化模型部署区域,单击AI视频生成-ComfyUI部署。
配置以下关键参数:
单击部署。等待约5分钟,当服务状态变为运行中,表示部署成功。
方式二:自定义模型部署
登录PAI控制台,在页面上方选择目标地域,并在右侧选择目标工作空间,然后单击进入EAS。
在推理服务页签,单击部署服务,然后在自定义模型部署区域,单击自定义部署。
配置以下关键参数:
部署方式:选择镜像部署,勾选开启Web应用复选框。
镜像配置:在官方镜像列表中选择
comfyui:1.9。其中:x.x:表示标准版,x.x-api:表示API版,x.x-cluster:表示集群版。说明由于版本迭代迅速,部署时镜像版本选择最高版本即可。
更多关于每个版本的使用场景说明,请参见选择部署版本。
存储挂载:如需使用自己的模型、安装自定义节点或通过API调用,必须进行存储挂载。以对象存储(OSS)为例,选择Bucket和目录,部署成功后系统会自动在其中创建ComfyUI所需目录。请确保创建的存储空间与EAS服务位于同一地域。
Uri:单击
 选择已创建的OSS存储目录。例如
选择已创建的OSS存储目录。例如oss://bucket-test/data-oss/。挂载路径:配置为
/mnt/data,表示将您配置的OSS文件目录挂载到容器路径/mnt/data下 。
运行命令:
选择镜像版本后,系统自动配置运行命令。
若进行了存储挂载,则必须在运行命令中添加
--data-dir参数, 并且其值与挂载路径完全一致。例如python main.py --listen --port 8000 --data-dir /mnt/data --cache-root /stable-diffusion-cache。
资源类型:选择公共资源。
部署资源:资源规格必须选择GPU类型,推荐使用GU30、A10或T4卡型。
ml.gu7i.c16m60.1-gu30性价比高,如库存不足可选择ecs.gn6i-c16g1.4xlarge。
单击部署。服务部署时间约为5分钟,当服务状态为运行中时,表明服务已成功部署。
通过WebUI使用
标准版、集群版和Serverless版支持通过WebUI使用。
进入Web界面
单击目标服务名称进入概览页面,在右上角单击Web应用。
如页面长时间无法打开,请参见刷新页面时间过长或页面卡死。
使用模板工作流
ComfyUI为常见任务提供预置模板。
选择一个模板(如Wan VACE 文生视频)。
说明ComfyUI不同镜像版本中的模板有差别,若无示例模板,可选择其他模板使用。也可以加载本地文件系统中的工作流使用。
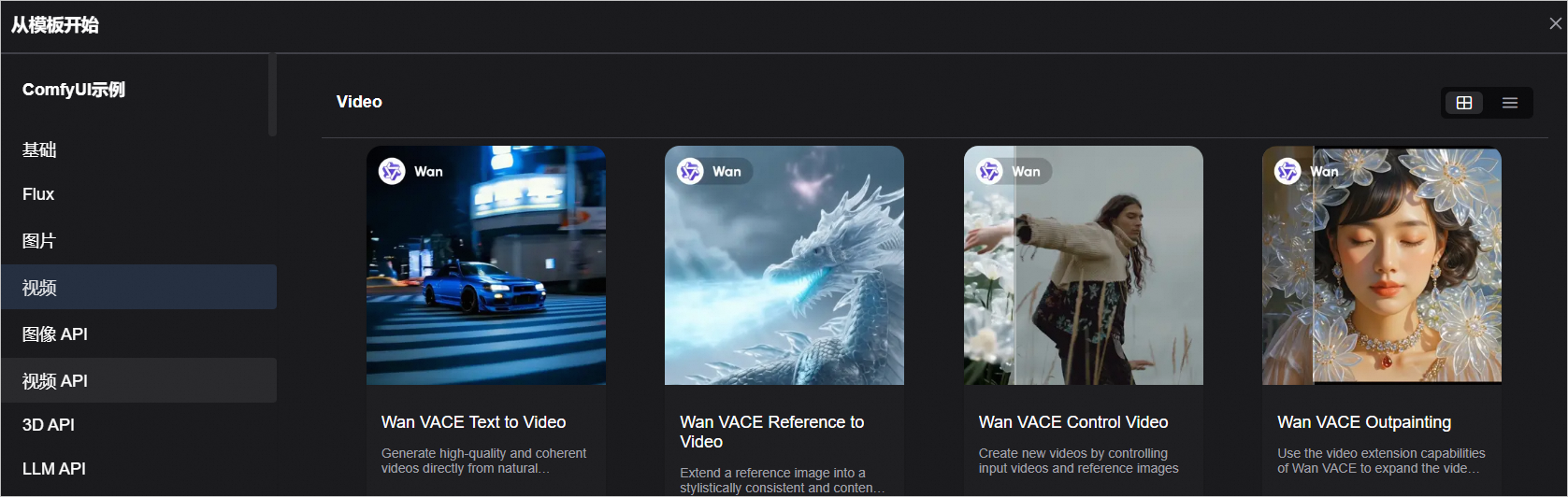
工作流加载成功后,如遇到报错缺少模型,可忽视(建议勾选不再显示此消息)。
由于路径变更,直接运行工作流可能会出现以下报错。

请先在Load models here区域重新选择模型
wan2.1_vace_14B_fp16.safetensors与Wan21_CausVid_14B_T2V_lora_rank32.safetensors。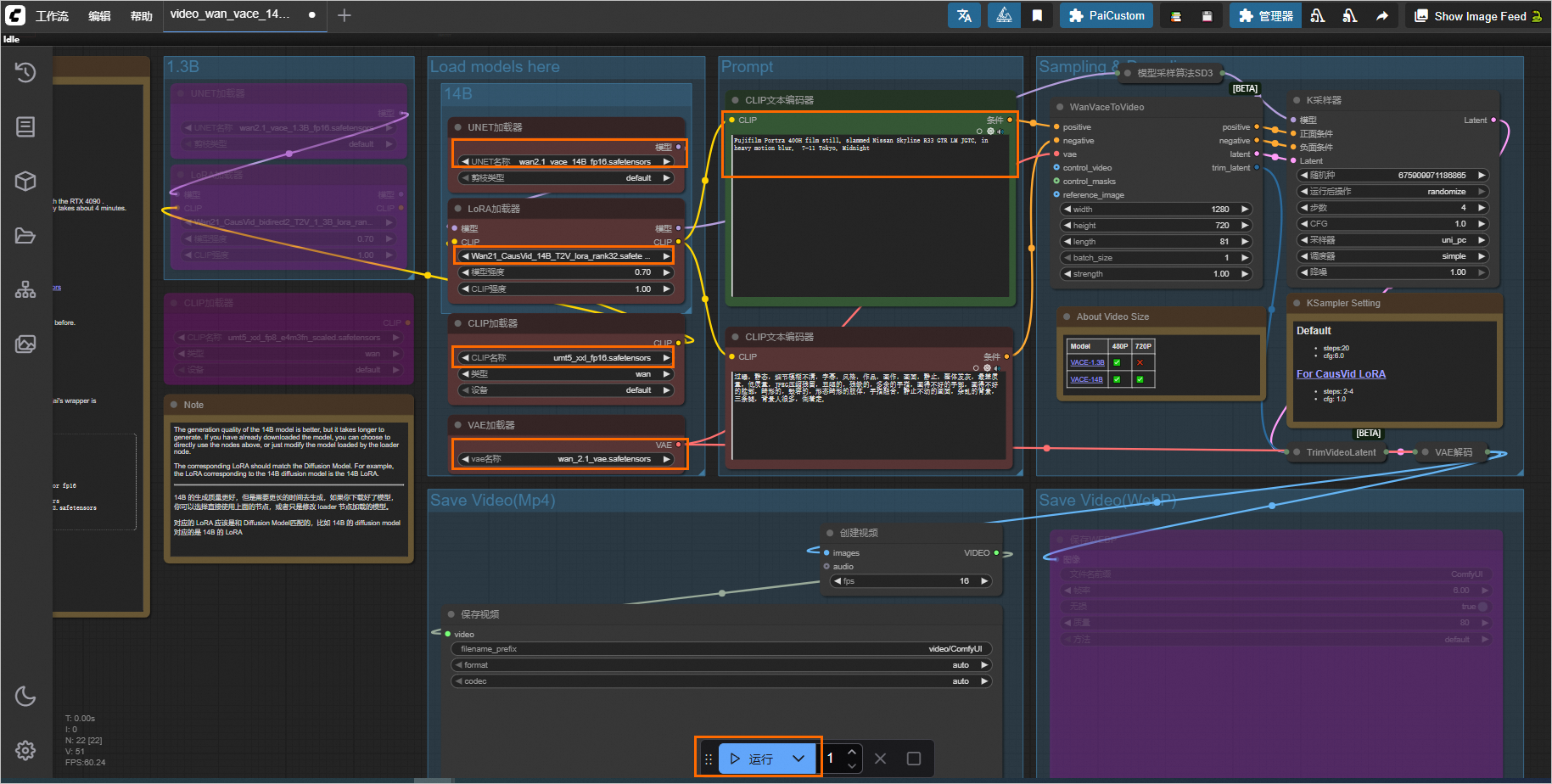
工作流运行成功后,会在Save Video区域,展示生成的视频。
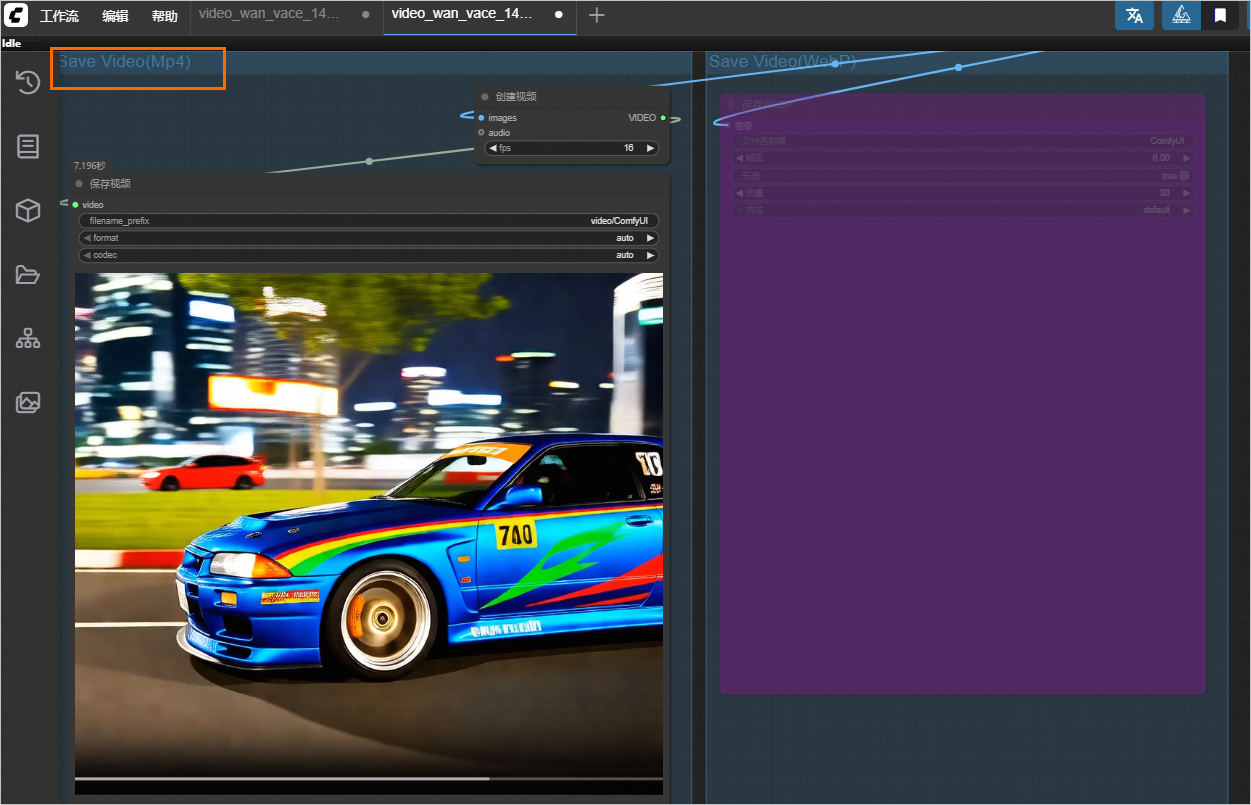
使用自定义模型和节点
Serverless版本不支持此功能。
确认服务已配置存储挂载。如使用自定义部署,需在运行命令中增加参数
--data-dir挂载目录,详情见方式二:自定义模型部署。服务部署成功后,系统会自动在已挂载的OSS或NAS存储空间中创建如下目录结构。
data-oss/ ├── custom_nodes/ # 存放节点文件(ComfyUI插件) ├── models/ # 存放模型文件 ├── input/ ├── output/ ├── unet/ └── temp/上传模型或节点文件。以OSS为例,可控制台上传文件到OSS。对于大文件,请参见如何上传大文件到OSS?。
模型文件上传:根据模型使用节点的源项目库使用说明,将模型上传至
models下的对应子目录。例如:Checkpoint加载器:模型上传至
models/checkpoints。风格模型加载器:模型上传至
models/styles。
节点文件上传:推荐您将自定义节点上传至挂载存储的
custom_nodes目录。
加载新内容。
模型:单击PaiCustom>加载新模型,如仍然找不到模型,单击重启进程,重启成功后,刷新浏览器页面。
节点:直接单击重启进程。重启成功后,刷新浏览器页面。
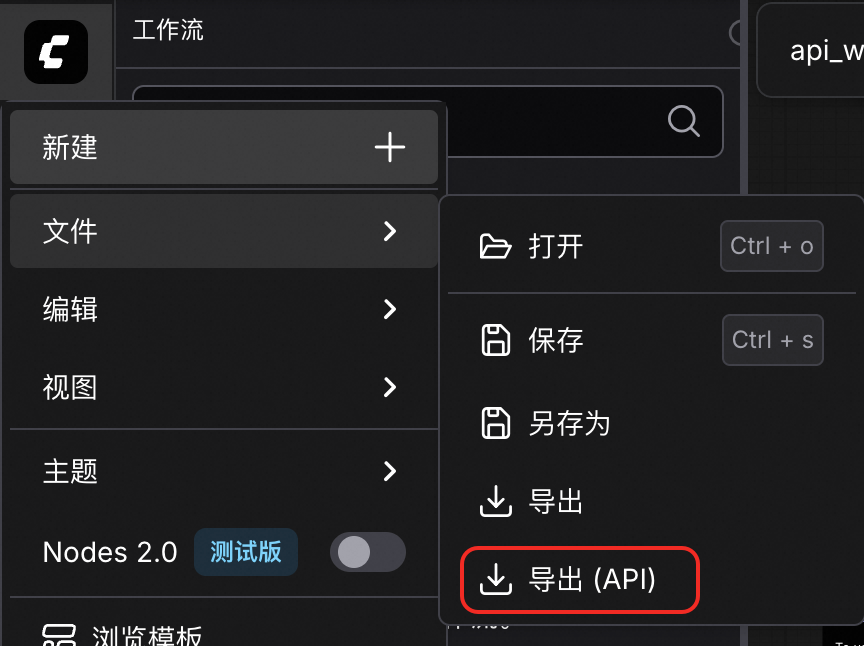
导出工作流
在WebUI中调试好工作流后,将工作流保存为一个JSON文件,用于后续的API调用。
API调用
API调用概述
通过API调用ComfyUI服务,可以将ComfyUI集成到您的应用程序中,实现自动化的AIGC内容生成。API调用的核心流程是:提交工作流JSON配置,系统返回任务ID,然后通过任务ID获取生成结果。
标准版服务仅支持同步调用,并且提供在线调试。
API版服务仅支持异步调用,且仅支持api_prompt路径。
关键准备工作:ComfyUI的API请求体取决于工作流配置。请先在WebUI页面设置并导出工作流的JSON文件。
结果下载:生成的图片或视频存储在挂载的output目录中,API调用的结果返回的是文件名和子目录名。对于OSS,需自行拼接完整的文件路径进行下载,请参见使用阿里云SDK下载OSS文件。
准备API请求体
根据调用方式的不同,请求体格式有所差异:
同步调用:请求体需要将工作流JSON文件内容包装在"prompt"键值下面。
异步调用:请求体就是工作流JSON文件内容。
因为上述Wan VACE Text to Video的工作流运行比较耗时,为方便测试提供以下工作流(运行一次需要约3分钟)。
同步调用
同步调用直接向EAS服务实例发送请求,适合开发测试和低并发场景。
在线调试
在线调试功能允许您在控制台直接测试API调用,无需编写代码。适合快速验证工作流配置和调试问题。
在模型在线服务 (EAS)页面,单击目标服务操作列下的在线调试,进入在线调试页面。
在调试页面的在线调试请求参数区域的Body处填写已准备好的请求体。并在请求URL文本编辑框中添加
/prompt。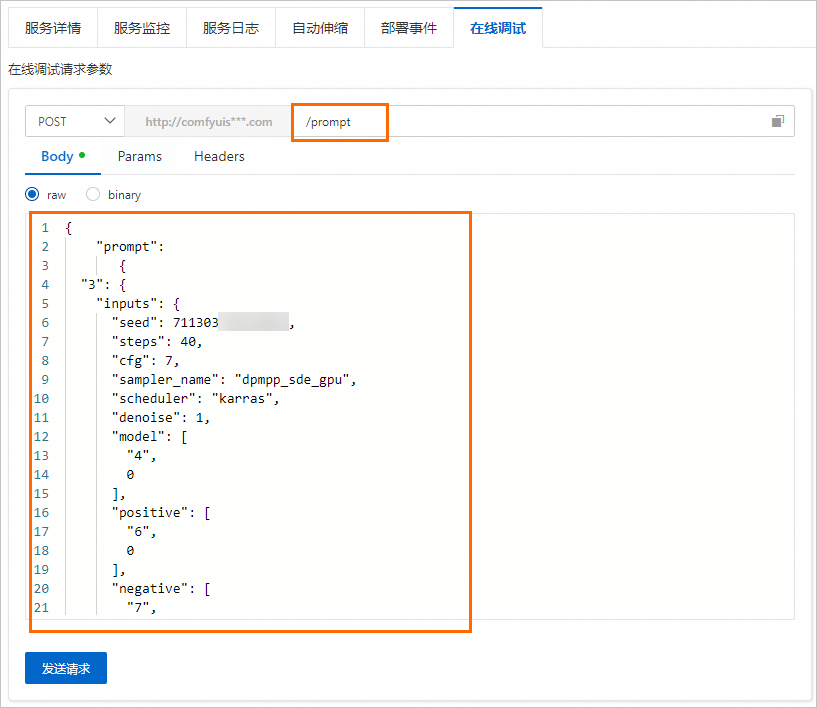
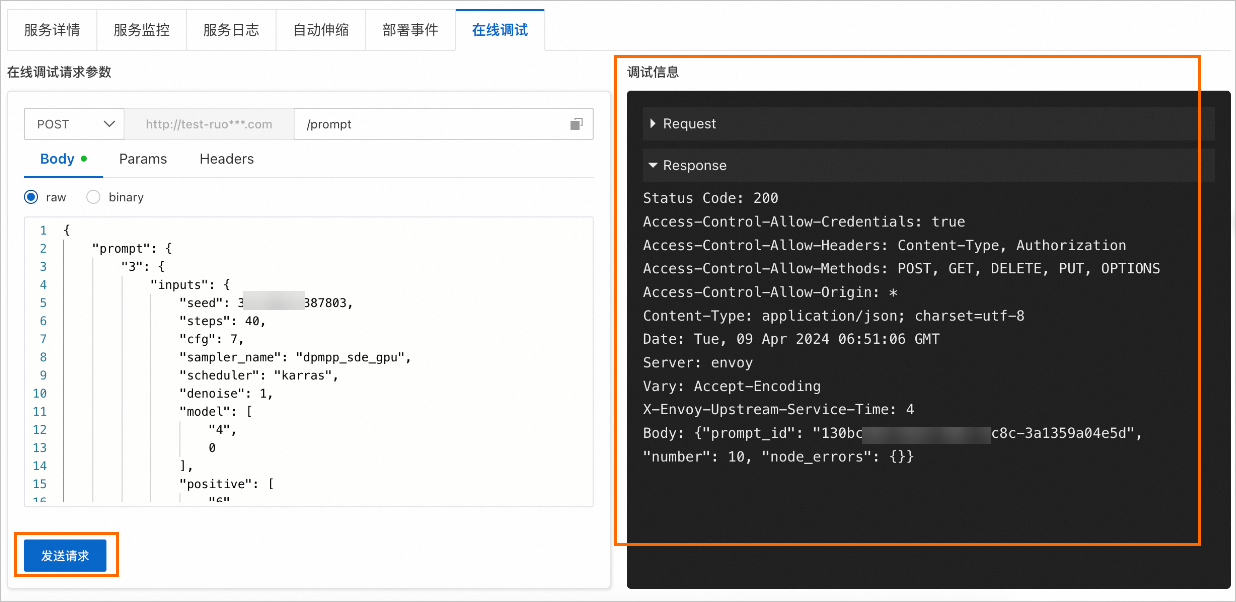
单击发送请求,即可在调试信息区域查看返回结果,示例如下。
在在线调试请求参数区域中,将请求方法修改为GET,并在文本框中配置
/history/<prompt id>,示例如下。
其中
<prompt id>需要替换为步骤1获取的Prompt ID。单击发送请求,即可获取推理结果。
您可以在挂载存储的
output目录中,查看生成的推理结果。
代码调用
通过代码调用API,可将ComfyUI集成到您的应用程序中。调用流程与在线调试相同:先获取Prompt ID,再查询推理结果。
在推理服务页签,单击目标服务名称进入概览页面,在基本信息区域单击查看调用信息。
在调用信息面板,可获取访问地址和Token。根据您的实际情况选择公网或VPC地址,后续使用<EAS_ENDPOINT>和<EAS_TOKEN>指代这两个值。

异步调用
异步调用适用于生产环境高并发场景,基于EAS队列服务实现负载均衡。提交请求后立即返回,通过订阅结果队列获取生成结果。
异步调用仅支持api_prompt路径,其task_id参数是标识请求和结果的关键标志,请给每个请求分配一个唯一的值,以对应后面的队列结果。请求路径如下:
{service_url}/api_prompt?task_id={需分配唯一值}
在推理服务页签,单击目标服务名称进入概览页面,在基本信息区域单击查看调用信息。在调用信息对话框的异步调用页签,查看服务访问地址和Token。

下文使用<EAS_ENDPOINT>指代公网输入调用地址(如果调用端与EAS处于同一VPC,可使用VPC输入调用地址),<EAS_TOKEN>指代Token。
常见问题
本节汇总了ComfyUI部署和使用过程中的常见问题,按问题类型分类。
部署问题
Q:服务一直显示等待中或者ComfyUI无法出图
通常是资源规格不够的原因。请检查服务镜像和资源规格配置是否正确,资源规格推荐使用GU30、A10或T4卡型,其中ml.gu7i.c16m60.1-gu30性价比高。
Q:服务部署一段时间后为什么会自动停止?
Serverless版的模型服务如果长时间没有接收到请求或计算任务,系统可能会自动释放相关资源以降低成本。
模型与节点问题
Q:WebUI显示“缺少模型”错误
问题描述:报错如下:
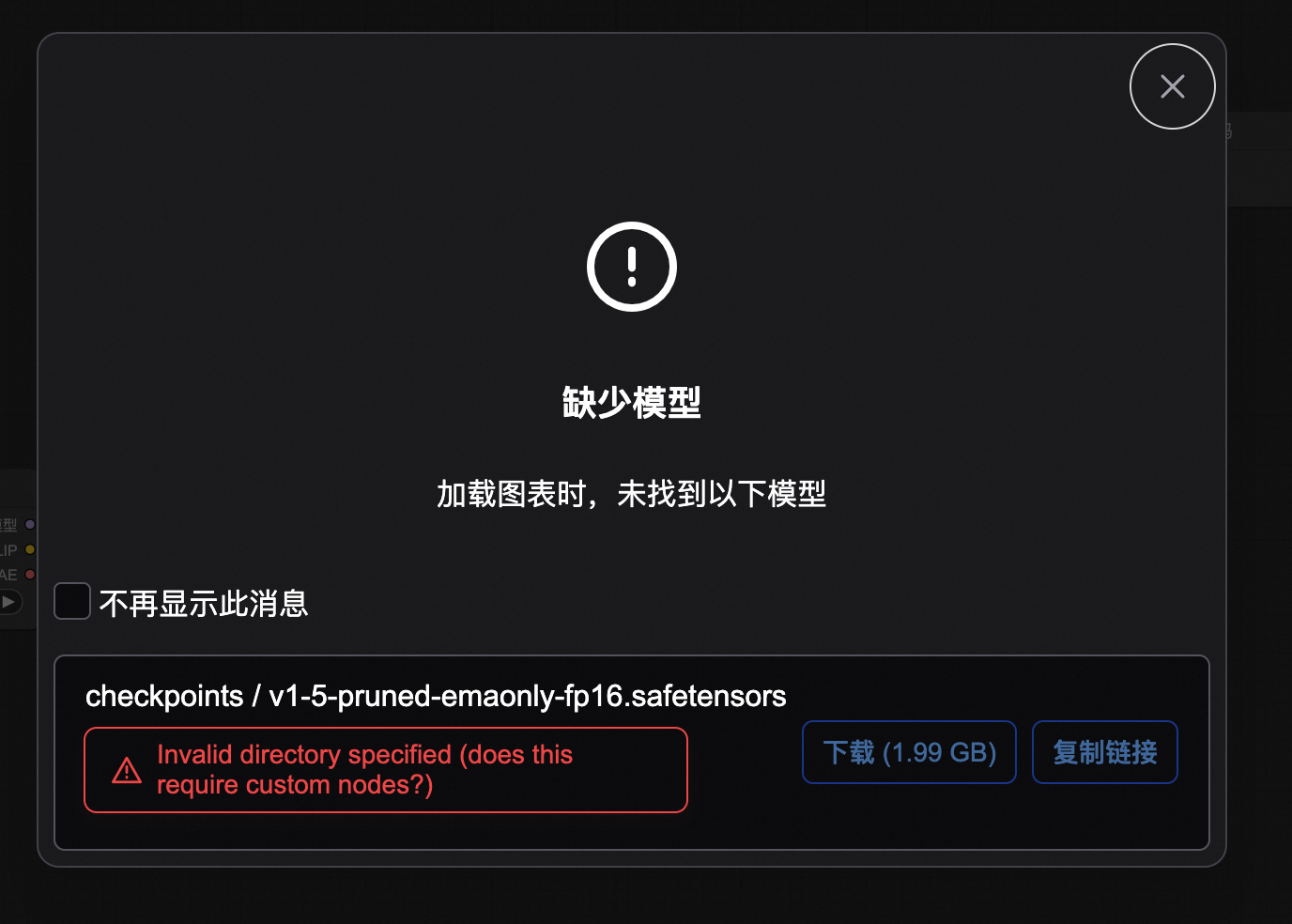
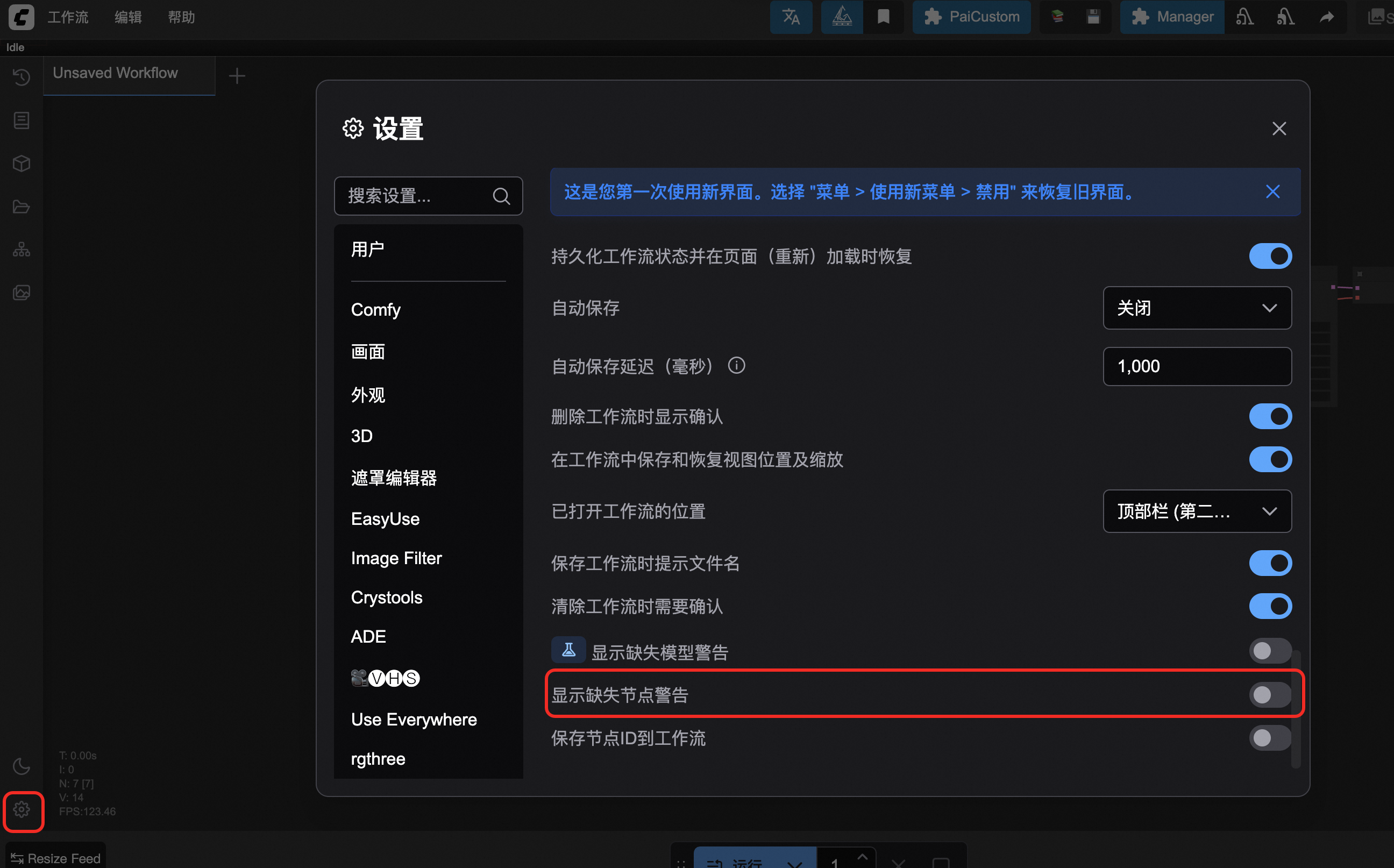
解决方案:此报错可以忽略。PAI部署的ComfyUI此检查无效,请以运行时的报错为准。
建议勾选不再显示此消息,或者通过设置关闭模型校验。
Q:上传了新模型但找不到
解决方案:
确认使用的不是Serverless版(Serverless版不支持上传自己的模型,请使用标准版或集群版)。
单击PaiCustom,选择加载新模型。
如不可见,单击重启进程。
Q:模型加载器显示undefined
首先确认模型的目录位置是否正确,这依赖于模型加载器的要求。
如在部署后上传模型,请重启服务。
Q:找不到节点
新安装的节点,需重启服务。
节点未安装,请参见使用第三方模型和安装节点(ComfyUI插件)。
Q:ComfyUI 管理器下载模型或安装节点失败
在EAS部署的ComfyUI中,不建议使用ComfyUI管理器。因为直接下载外网模型或安装插件(需要从GitHub等平台拉取代码),有可能存在网络连接失败的问题。
建议您将模型或节点文件上传到服务挂载的存储上,详情请参见使用第三方模型和安装节点(ComfyUI插件)。
Q:如何查看当前可用的模型文件和节点(ComfyUI插件)列表
模型文件:在相应模型加载节点查看。例如在Checkpoint加载器的下拉列表中查看当前可用的模型文件。
节点:右键单击WebUI页面,在快捷菜单中单击添加节点,查看所有已安装的ComfyUI插件。
运行异常
Q:页面卡死或加载页面时间过长
刷新页面,清理浏览器缓存或使用无痕/隐私模式访问。
如挂载了存储,删除
input/、output/、temp/文件夹中的文件。尝试重启服务。
Q:工作流跑一半,进程重启了
如果实例日志里面有run.sh: line 54: 531285 Killed python -u main_run.py "$@",那就是内存oom了,内存oom之后,进程会自动重启。
Q:RuntimeError: CUDA error: out of memory
显存超了,如果是图像模型就降低图像的分辨率或者batch size;视频模型降低一下帧数/分辨率。
Q:API调用报错:url not found 或404 page not found?
确认使用的不是Serverless版本(Serverless类型不支持API调用)。
检查API端点URL是否完整。同步调用需拼接
/prompt路径。
其他
Q:xFormer的加速效果
xFormers是基于Transformer的开源加速工具,能够有效缩短图片和视频生成时长,节省显存使用。
ComfyUI镜像部署默认已开启xFormers加速。加速效果跟工作流的大小相关,针对GPU调用的内容尤其是使用NVIDIA显卡的提升比较明显。
Q:EAS与函数计算在部署ComfyUI Serverless版的主要区别
EAS:适合有状态、长周期运行的服务,支持一键部署模型为在线推理服务或AI-Web应用,具备弹性扩缩容、蓝绿部署等功能。例如,您可以通过EAS的场景化模型部署或自定义模型部署方式来部署ComfyUI。
函数计算:基于Serverless架构,提供按需付费、弹性伸缩等优势,适合需要高质量图像生成功能的场景,可自定义ComfyUI模型及安装插件。例如,您可以在函数计算3.0控制台创建应用、选择ComfyUI模板、设置配置项并创建应用。
下一步
完成ComfyUI服务部署后,您可以:
参考信息
安装Python包
通过运行命令安装whl包
确保已为服务挂载存储。假设OSS路径Uri为
oss://examplebucket/comfyui/,挂载路径为/mnt/data/。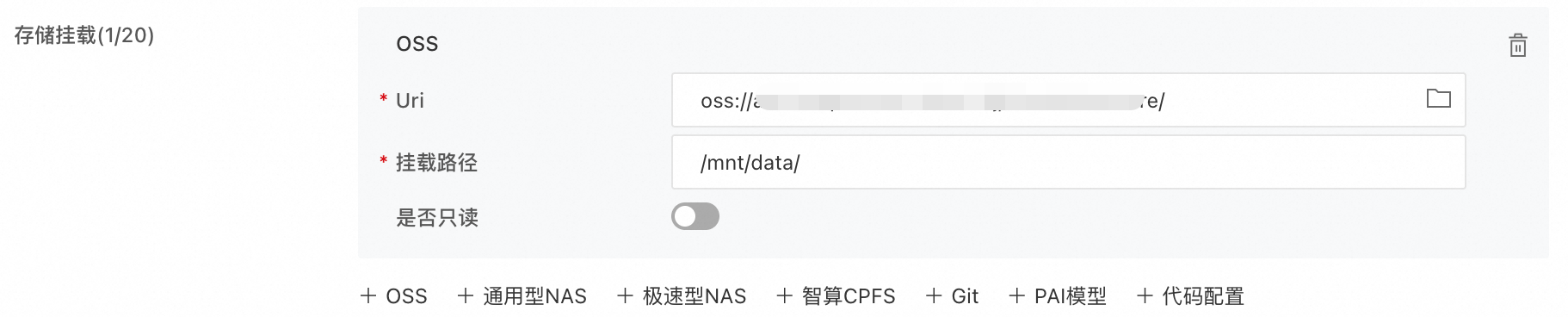
将
.whl文件上传到oss://examplebucket/comfyui/models/whl目录下,如无whl的文件夹,请先创建。更新服务配置中的运行命令:在运行命令前增加
pip install /mnt/data/models/whl/xxx.whl。其中/mnt/data为OSS的挂载路径,xxx.whl表示whl包的名字。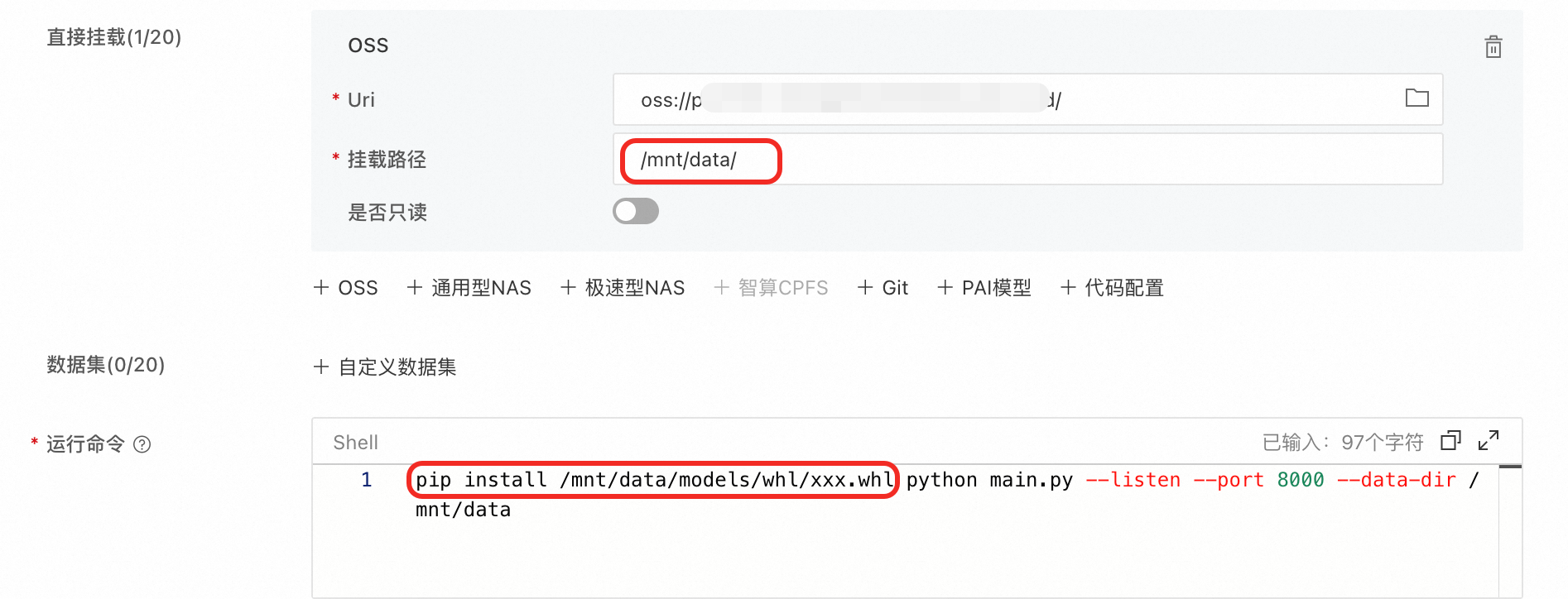
重启服务。
通过三方库配置安装
在服务详情页右上角单击更新。

如果是通过场景化部署,请切换为自定义部署。
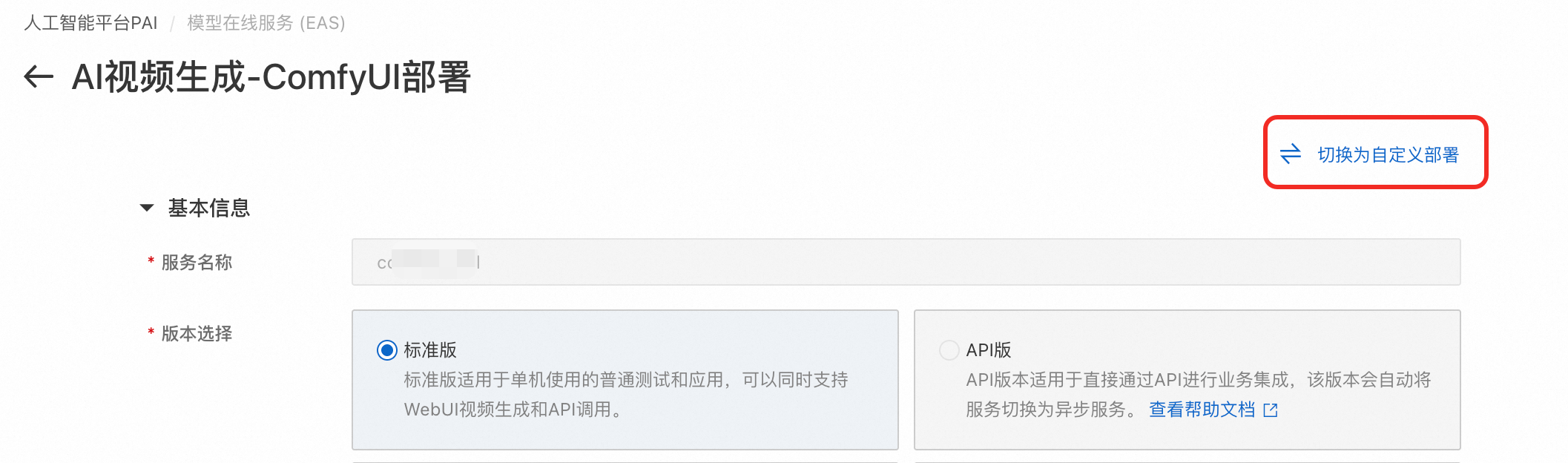
在环境信息区域的三方库配置,设置依赖包。
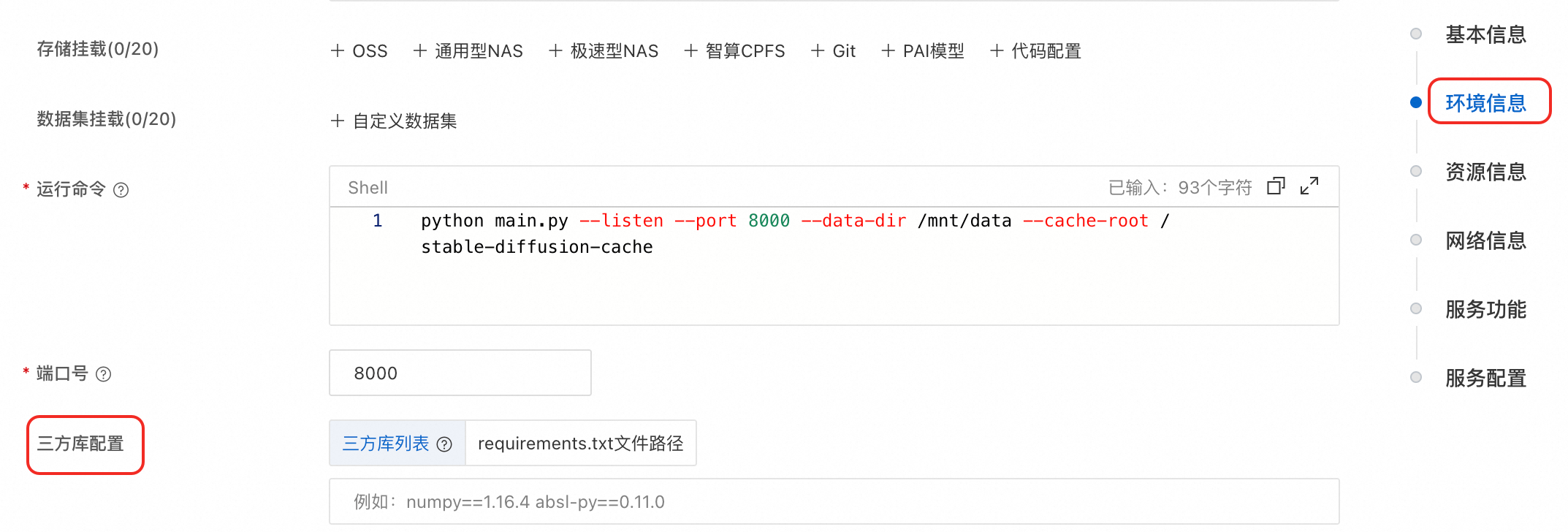
单击页面下方更新按钮,完成服务更新即可。
更新镜像版本
Serverless版本不支持此功能。
若服务挂载OSS或者NAS存储空间,自定义模型保留在OSS或者NAS存储空间,更新镜像版本不会影响已安装的自定义模型。
在服务详情页右上角单击更新。
如通过场景化方法部署,请切换为自定义部署。
在服务配置区域,编辑JSON配置并更新
containers的image字段,如图将1.9改成需要的版本。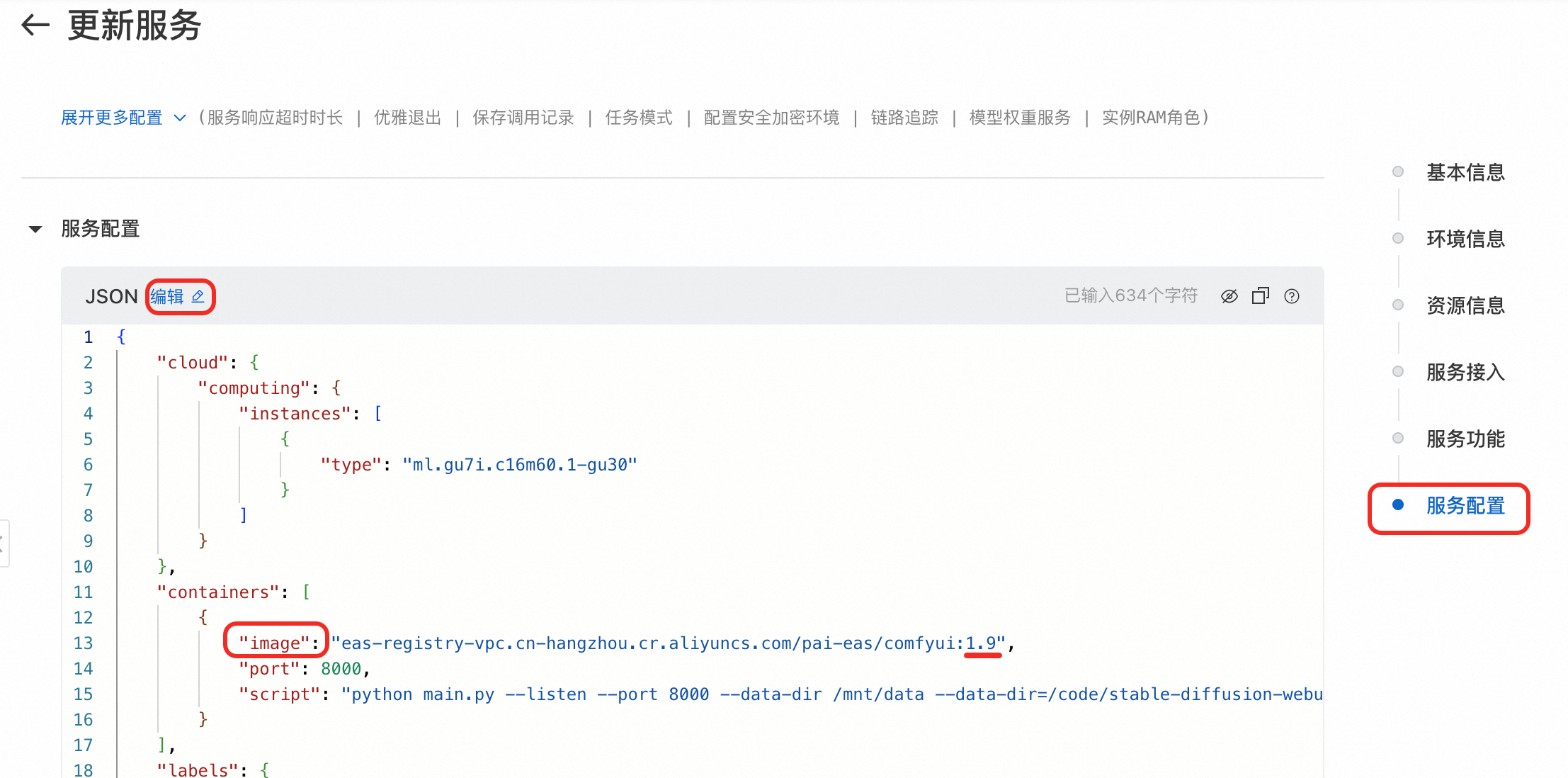
单击直接更新。
延长无登录态的URL时间
可通过API获取指定有效时长的免登录Web访问链接。
选择服务地址。
设置参数:
ClusterId服务所在区域、ServiceName 服务名字:填写服务所在区域与服务名字。如下从EAS服务概览页面获取。

Type 页面类型:下拉选择 webview。
Expire 过期时间:填写整数,单位为秒。目前最长只能是43200秒(12小时),建议按需填写。
Internal 是否为VPC链接:false(公网访问)或true(VPC访问)。
单击发起调用,返回结果中
SignedUrl为服务免登录Web访问链接。
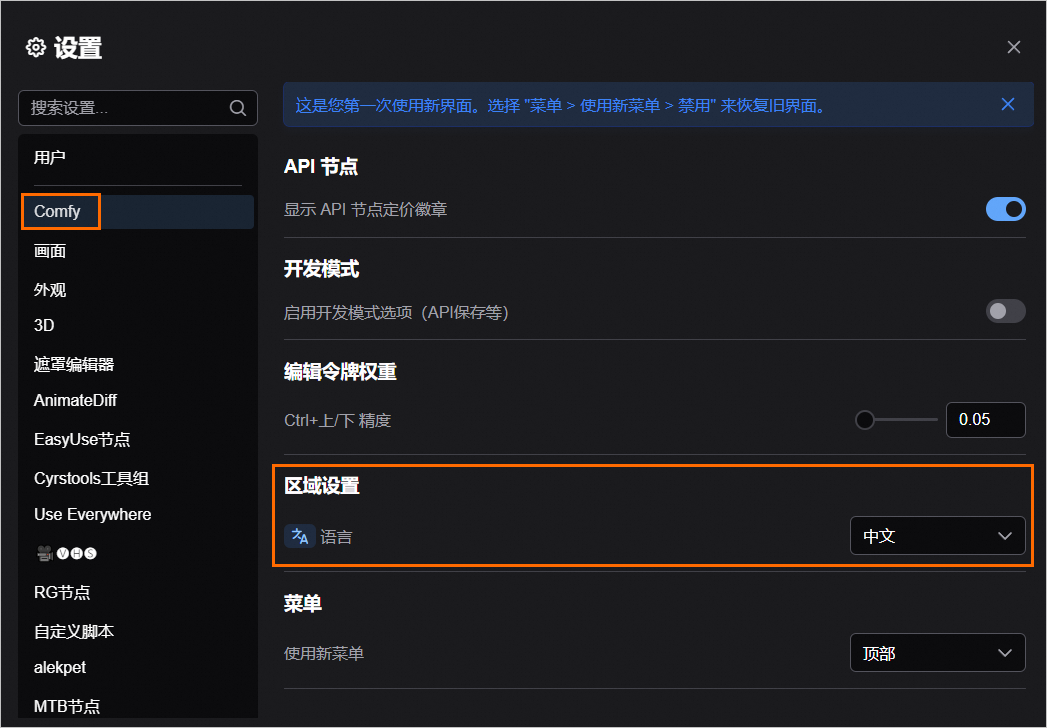
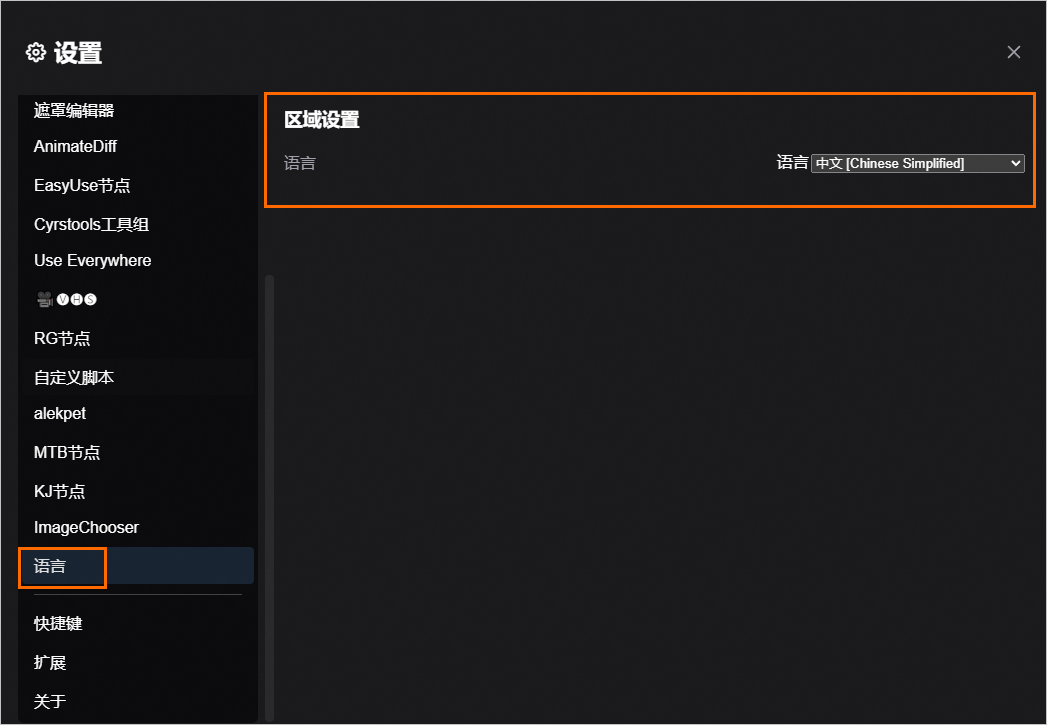
切换WebUI页面的默认语言
在WebUI页面,单击左下角的设置按钮。
分别在以下两个位置设置完成后,刷新页面并重新加载即可。
Comfy > 区域设置:
语言 > 区域设置:
附录
集群版服务原理介绍
实现原理图如下:

集群版服务主要针对多用户场景,通过引入一个 Proxy 代理层,实现了客户端和后端推理实例解耦。
每个用户有独立的后端环境和工作目录,但共享后端的GPU推理实例池。
当用户发起推理请求时,Proxy 代理会从池中寻找一个空闲的实例来处理该请求。
这种分时复用机制在保证用户环境隔离的同时,有效提升了 GPU 资源的利用率,降低了多用户场景下的推理成本。