LangStudio 提供了一个直观、高效的集成开发环境,可在此构建、调试和优化由大语言模型、Python节点及其他工具组成的应用流。
快速开始
参见创建工作流应用。
创建方式说明
从模板新建:提供多场景的应用模板快速搭建AI应用。
按类型新建:
标准型:适用于通用应用程序开发。利用大语言模型的强大功能、定制的Python代码等来打造您的定制化应用流。
对话型:适用于对话型应用程序开发。在标准型的基础上,对话型提供对话历史、输入、输出的管理,以及对话框形式的测试界面。
从OSS导入:选择待导入的应用流ZIP压缩包文件或应用流OSS路径,该路径必须直接包含应用流的flow.dag.yaml及其他Code文件。
可通过LangStudio应用流列表操作列的导出功能将应用流导出,分享给他人导入使用。
将Dify的DSL文件转换LangStudio应用流格式后,可通过该方式导入。
配置环境变量
在 LangStudio 中,您可以添加应用流运行时所需的环境变量,系统会在应用流执行前自动加载这些变量,供 Python 节点、工具调用或自定义逻辑使用。
适用场景
敏感信息管理:存储 API 密钥、认证令牌等,避免硬编码在代码中。
配置参数化:灵活设置模型地址、超时时间等运行参数。
配置与使用
在应用流编辑页面,单击右上角设置,添加环境变量。
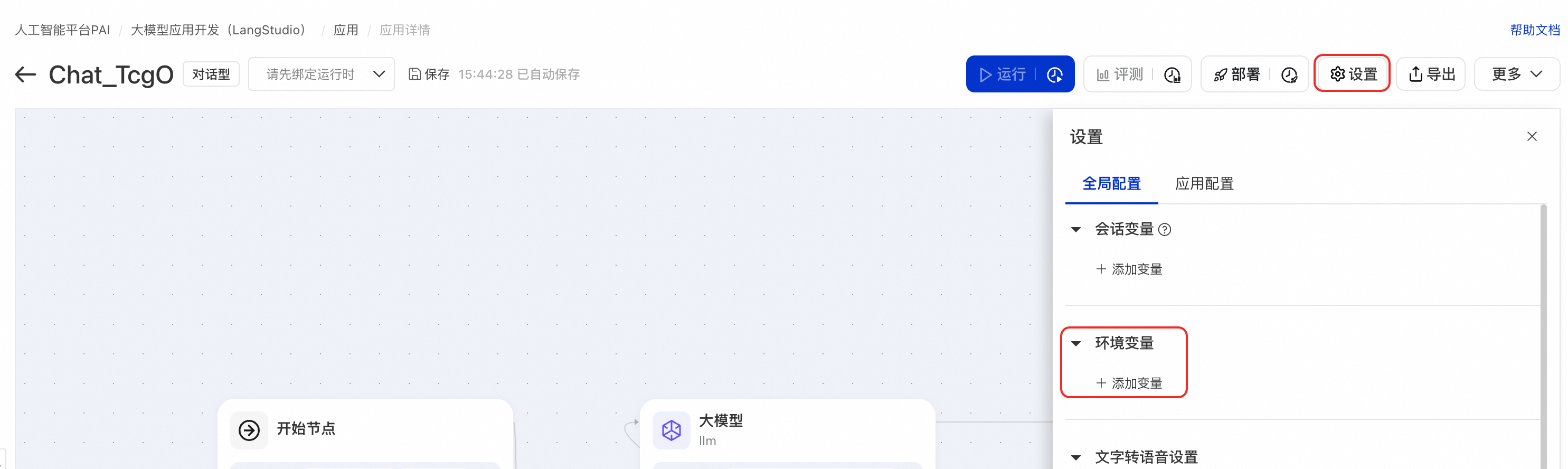
在Python节点中,可通过标准 Python 的
os.environ访问已配置的环境变量:import os # 示例:获取 API 密钥 api_key = os.environ["OPENAI_API_KEY"]
配置语音交互
在应用流编辑页面,单击右上角设置,在全局配置页签进行语音交互设置。
语音转文字
语音转文字功能可将用户的语音输入转换为文本,并作为开始节点中标识为“对话输入”字段的输入内容。

配置参数 | 说明 |
模型设置 | 选择已配置的模型服务连接和 ASR 模型。目前支持 Paraformer 系列模型。 |
识别语言 | 设置语音识别的语言。当前仅 paraformer-v2 模型支持指定识别语言。 |
文字转语音
文字转语音功能可将工作流的对话输出自动合成为语音。

配置参数 | 说明 |
模型设置 | 选择已配置的模型服务连接和 TTS 模型。目前支持 CosyVoice 系列模型。 |
音色设置 | 选择合成语音的音色。支持多种预置音色。 |
自动播放 | 开启后,对话时合成的语音会自动播放。 |
部署调用
部署至PAI-EAS后,您可以通过API调用实现语音交互功能。关于通用的API调用方式,请参见应用流部署。本节重点说明语音交互相关的差异部分。
语音输入
在请求体中添加system.audio_input字段传入音频文件 URL(文件数据结构可参考文件类型输入输出),系统会自动将音频转换为文本并填入对话输入字段。
{
"question": "",
"system": {
"audio_input": {
"source_uri": "oss://your-bucket.oss-cn-hangzhou.aliyuncs.com/audio/input.wav"
}
}
}语音输出
如需获取 TTS 合成的音频数据,请使用完整模式(<Endpoint>/run端点)进行调用,简单模式不返回音频数据。
字段 | 说明 |
audio_data | Base64编码的音频数据片段,需在客户端解码后拼接播放 |
tts_metadata | 音频元数据,包含格式(pcm)、采样率(22050Hz)、声道数(1)、位深(16bit) |
流式响应
TTS音频通过SSE事件流中的TTSOutput事件返回:
{
"event": "TTSOutput",
"audio_data": "<base64编码的音频数据>",
"tts_metadata": {
"format": "pcm",
"sample_rate": 22050,
"channels": 1,
"bit_depth": 16
}
}非流式响应
TTS音频作为output.tts_audio字段包含在JSON响应中:
{
"output": {
"answer": "xxx",
"tts_audio": {
"audio_data": "<base64编码的完整音频数据>",
"tts_metadata": {
"format": "pcm",
"sample_rate": 22050,
"channels": 1,
"bit_depth": 16
}
}
}
}预置组件说明
详情请参见工作流节点参考。
下一步
在完成应用流的开发和调试后,您可以对应用流进行评测,待满足业务需求后,您可以将应用流部署至模型在线服务PAI-EAS中供生产使用。