本文将介绍企业在没有向量数据的情况下,如何通过OpenSearch向量检索版,快速搭建图像搜索服务。
用户可以直接导入图片源数据,在OpenSearch内部便捷完成图片向量化、向量搜索等步骤,实现以图搜图、以文搜图等多种图像检索能力。
方案架构
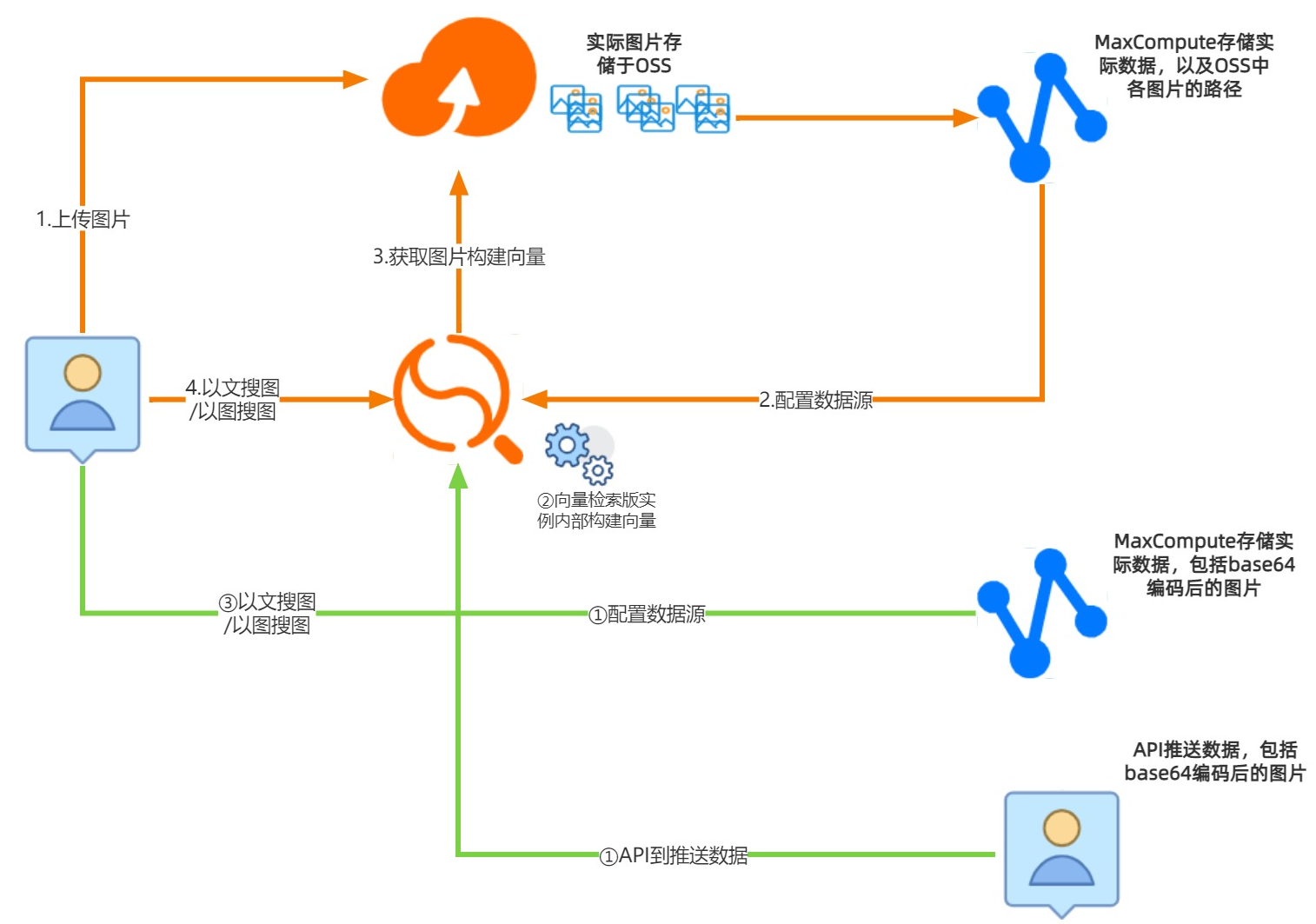
用户可以通过3种不同的方式上传图片进行图搜引擎的搭建:
OSS+MaxCompute+OpenSearch向量检索版:用户先将图片上传至OSS中,在MaxCompute中存储业务表数据以及每条数据对应的图片地址(OSS里的路径,比如/image/1.jpg)
MaxCompute+OpenSearch向量检索版:用户将图片通过base64编码后的图片及其表数据存储在MaxCompute中
API+OpenSearch向量检索版:用户通过OpenSearch向量检索版给出的数据推送接口,将base64编码后的图片及其表数据推送到OpenSearch向量检索版实例中
本文演示的是OSS+MaxCompute+OpenSearch向量检索版搭建图搜引擎。
环境准备
1、创建AK和SK
第一次开通阿里云账号并登录控制台时,会提示先创建access key才能继续使用。
创建及使用应用依赖access key参数,主账号下access key参数不能为空。
在为主账号创建access key参数后,还可以再创建RAM子账号access key通过RAM子账号进行访问,RAM子账号赋予对应访问权限,请参考RAM(子账号)的创建及授权。
2、创建对象存储OSS
本文在OSS中上传了1000张图片:
部分图片类型如下:
购买OpenSearch向量检索版实例
进入OpenSearch控制台,在左上角切换到OpenSearch-向量检索版:

进入向量检索版控制台后,在实例管理界面,点击创建实例:

商品版本选择向量检索版,选择地区,配置“查询节点个数”、“查询节点规格”、“数据节点数量”、“数据节点规格”、“单数据节点总存储空间”,设置“专有网络”和“虚拟交换机”,最后按提示要求设置用户名和用户密码(用于查询时校验权限,非阿里云账号密码),点击“立即购买”:
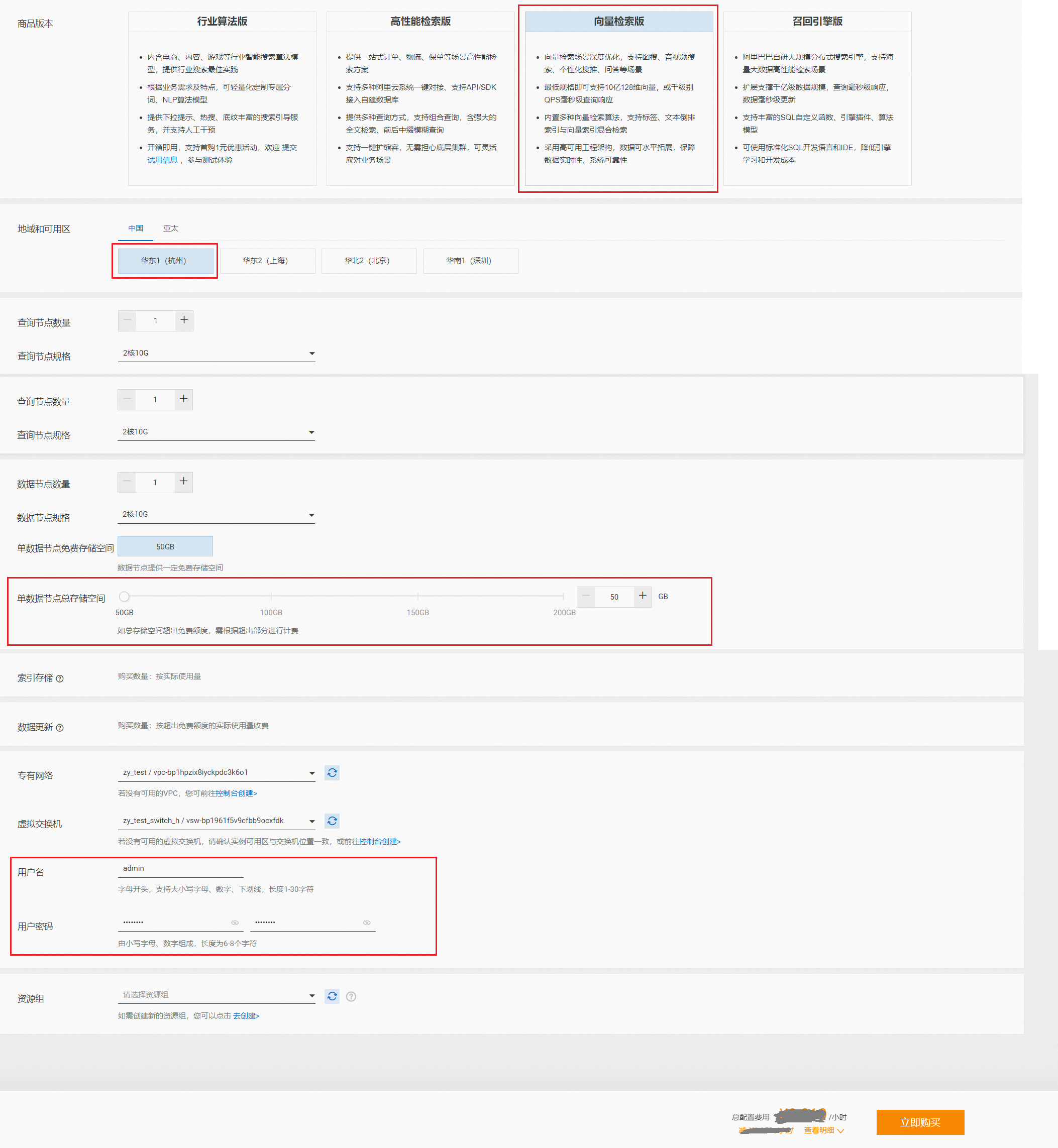
购买的查询节点和数据节点的个数及规格,需根据自身业务进行规划,确定规格后实际费用可在售卖页自动生成。
专有网络和虚拟交换的配置一定要和访问向量检索版实例的ECS机器保持一致。否则在访问向量检索版实例时会报错{'errors':{'code':'403','message':'Forbidden'}}
单数据节点存储空间有免费额度,用户也可申请额外额度,按额外额度部分收费(步长50GB)
在确认订单界面,查看服务协议,确认无误后,点击立即开通:
购买成功后,点击管理控制台,即可在实例管理界面查看已购买的向量检索版实例:
新购的实例会设置一个默认实例名称,可在操作栏下点击管理按钮,进入详情页进行修改:

点击修改图标,按提示框要求修改实例名称最后点击确认:

配置集群
新购买的实例,在其详情页中,实例状态为“待配置”,并且会自动部署一个与购买的查询节点和数据节点的个数及规格一致的空集群,之后需要为该集群配置数据源--->配置索引--->索引重建,之后才可正常搜索。

1、配置数据源
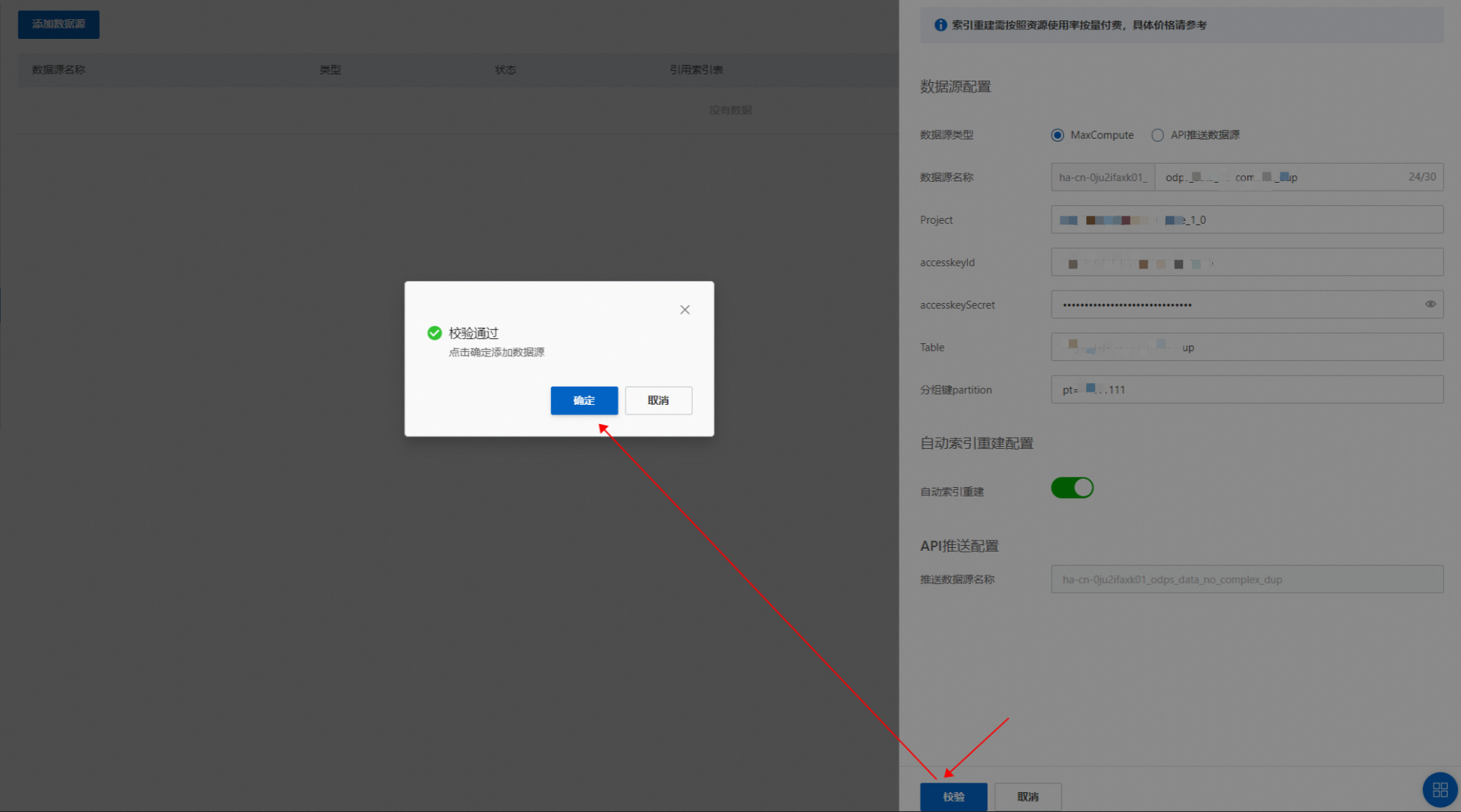
配置数据源(目前支持的数据源有“MaxCompute数据源”和“API推送数据源”)这里以MaxCompute数据源为例:点击“添加数据源”,数据源类型选择“MaxCompute”,设置project、accesskeyID、accesskeyId、accesskeySecret、Table、分组键partition,可按需选择是否开启“自动索引重建”:
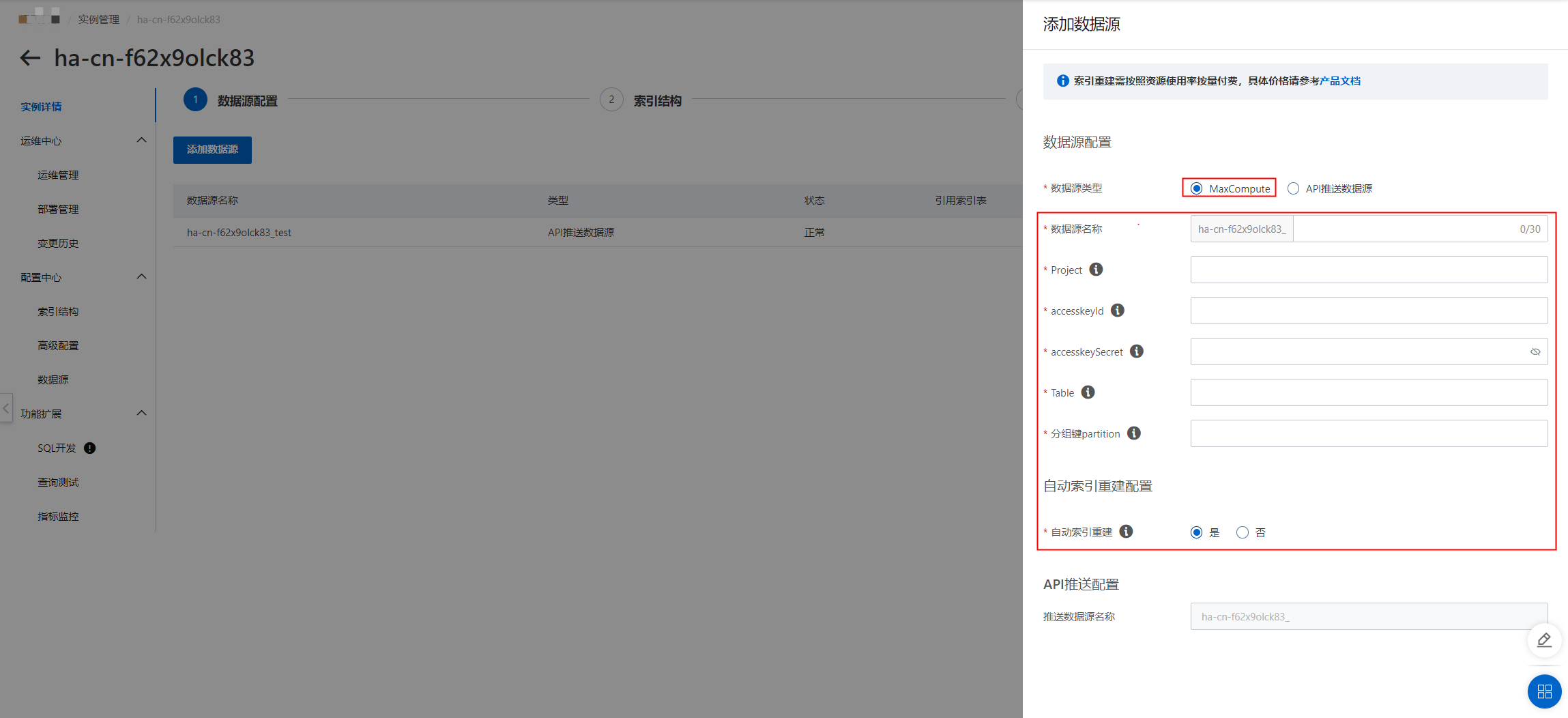
校验成功之后,点击“确定”,完成数据源的添加:
2、配置索引结构
数据源配置成功后,需点击下一步配置索引结构:

添加索引表:

配置索引表,模板选择“向量:图片搜索”模板,数据情况选择“需要将原始数据转为向量”:

配置字段:此处介绍图片存储于OSS和基于base64编码图片方案配置:
图片存储于OSS
模板选择“向量:图片搜索”模板后,系统默认生成4个预置字段id(主键)、cate_id(类目字段)、vector(向量字段)、vector_source_image(存储图片路径的字段),用户选择MaxCompute数据源后,从数据源同步的字段,展示在预置字段下方。
4.1. 配置“vector_source_image”字段:(字段类型需要为STRING)
用户可根据业务表字段对预置字段名称进行修改,但需要保证该字段的高级配置无误:
具体配置如下:
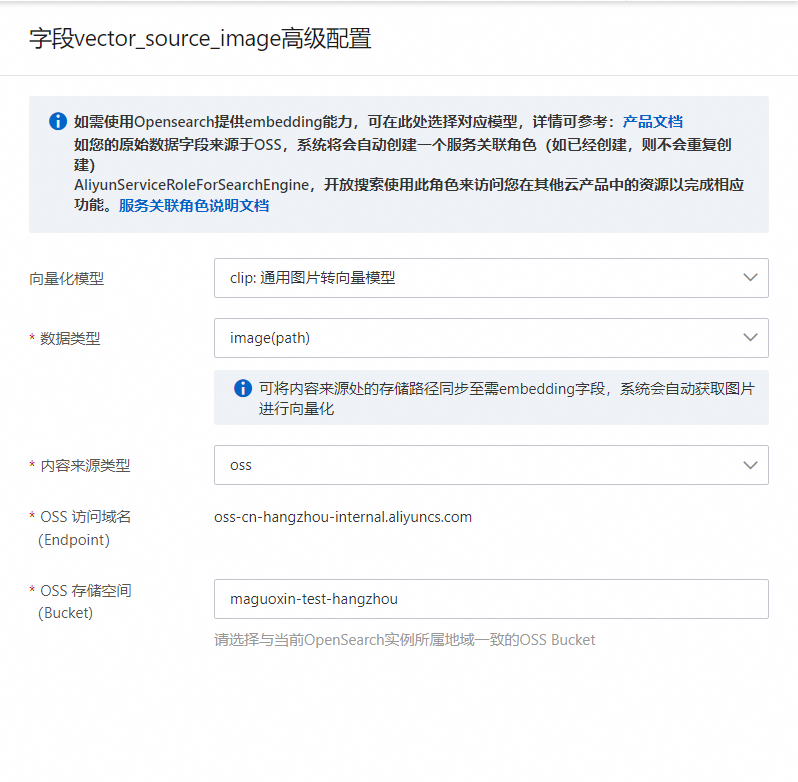
数据类型:选择image(path)
内容来源类型:选择oss
OSS存储空间:填写当前账号可以访问的且存储需要向量化图片的OSS存储空间
假设某张图片在OSS的路径为“/测试图片/image/10031.png”,那么该字段的内容也必须是“/测试图片/image/10031.png”,以下图举例:
OSS的路径:

MaxCompute字段值:

4.2. 配置vector字段:(字段类型需要为FLOAT)
配置完“vector_source_image”字段后,引擎可以通过OSS访问到对应的图片,如果需要“将原始数据转为向量数据”,还需要配置vector字段,用户可根据业务表字段对预置字段名称进行修改,但需要保证该字段的高级配置无误:

具体配置如下:
{
"vector_model": "clip",
"vector_modal": "image",
"vector_source_field": "vector_source_image"
}vector_model:向量化模型,目前支持通用图片和电商增强图片转化
选择通用类型,
"vector_model": "clip",通用图片转向量模型。选择电商增强:
"vector_model": "clip_ecom",电商增强图片转向量模型。
vector_modal:填写
imagevector_source_field:配置存储OSS图片路径的字段,默认为vector_source_image
4.3. schema示例:
"fields": [
{
"field_name": "id",
"field_type": "INT64",
"compress_type": "equal"
},
{
"user_defined_param": {
"content_type": "oss",
"oss_endpoint": "",
"oss_bucket": "OSS的Bucket名称",
"oss_secret": "可以访问OSS的账号SK",
"oss_access_key": "可以访问OSS的账号AK"
},
"field_name": "vector_source_image",
"field_type": "STRING",
"compress_type": "uniq"
},
{
"field_name": "cate_id",
"field_type": "INT64",
"compress_type": "equal"
},
{
"user_defined_param": {
"vector_model": "clip",
"vector_modal": "image",
"vector_source_field": "vector_source_image"
},
"field_name": "vector",
"field_type": "FLOAT",
"multi_value": true
}
]base64编码的图片
模板选择“向量:图片搜索”模板后,系统默认生成4个预置字段id(主键)、cate_id(类目字段)、vector(向量字段)、vector_source_image(存储图片base64编码后的字段),用户选择MaxCompute数据源后,从数据源同步的字段,展示在预置字段下方。
4.1. 配置“vector_source_image”字段:(字段类型需要为STRING)
用户可根据业务表字段对预置字段名称进行修改:

注意:需要手动将“vector_source_image”字段中的高级配置删除,保留{}即可。
4.2. 配置vector字段:
配置完“vector_source_image”字段后,引擎可以通过OSS访问到对应的图片,如果需要“将原始数据转为向量数据”,还需要配置vector字段,用户可根据业务表字段对预置字段名称进行修改,但需要保证该字段的高级配置无误:

具体配置如下:
{
"vector_model": "clip",
"vector_modal": "image",
"vector_source_field": "vector_source_image"
}vector_model:填写
clipvector_modal:填写
imagevector_source_field:配置存储OSS图片路径的字段,默认为vector_source_image
4.3. schema示例:
"fields": [
{
"field_name": "id",
"field_type": "INT64",
"compress_type": "equal"
},
{
"field_name": "vector_source_image",
"field_type": "STRING",
"compress_type": "uniq"
},
{
"field_name": "cate_id",
"field_type": "INT64",
"compress_type": "equal"
},
{
"user_defined_param": {
"vector_model": "clip",
"vector_modal": "image",
"vector_source_field": "vector_source_image"
},
"field_name": "vector",
"field_type": "FLOAT",
"multi_value": true
}
]模板选择“向量:图片搜索”模板后,默认生成两个索引,分别为主键索引(id)和向量索引(vector),字段“vector_source_image”和“vector”高级配置完成后,在索引设置中“vector”索引会自动生成高级配置:(类型需要为CUSTOMIZED)
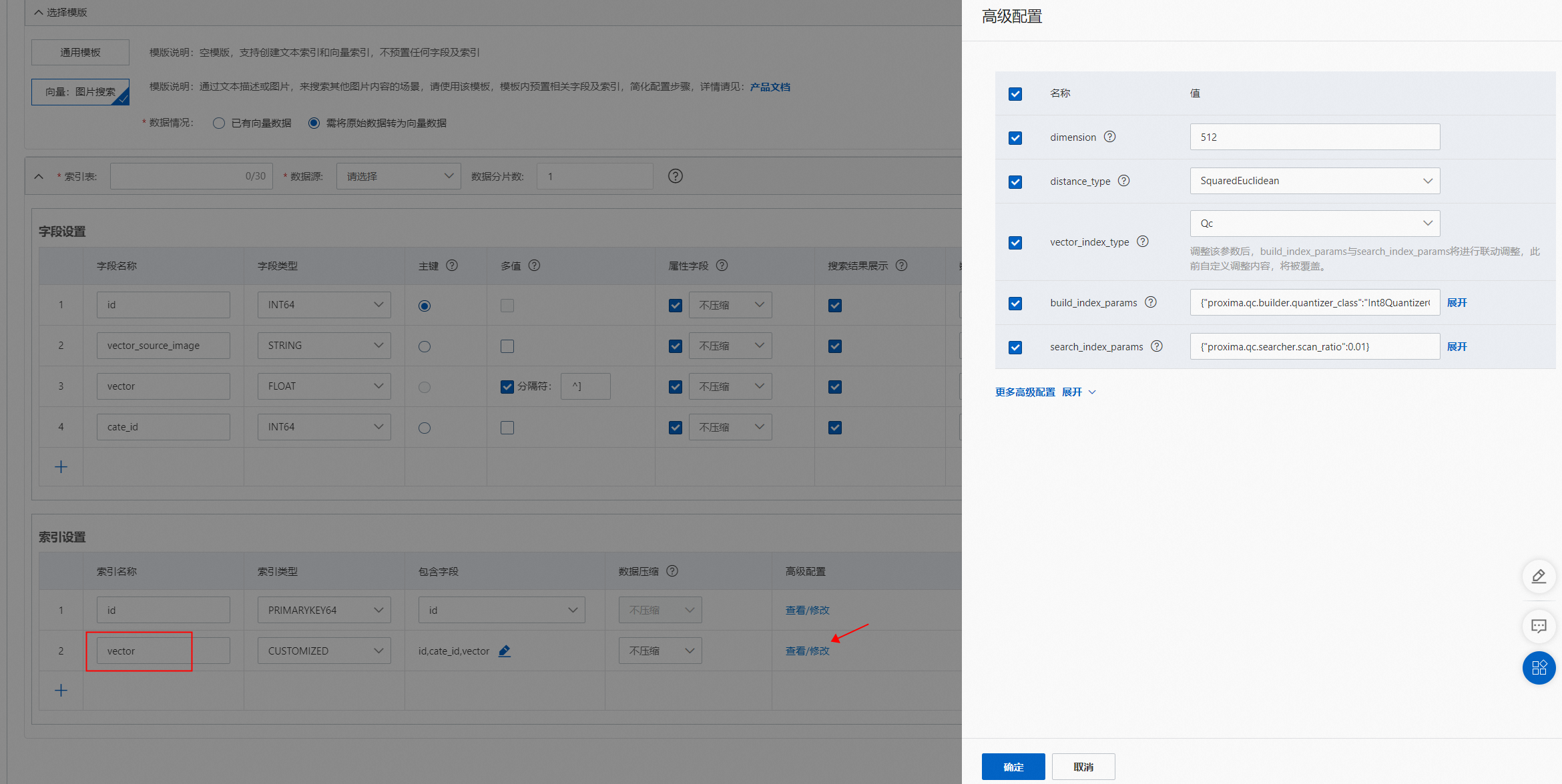
用户需根据字段的配置修改vector索引包含的字段:
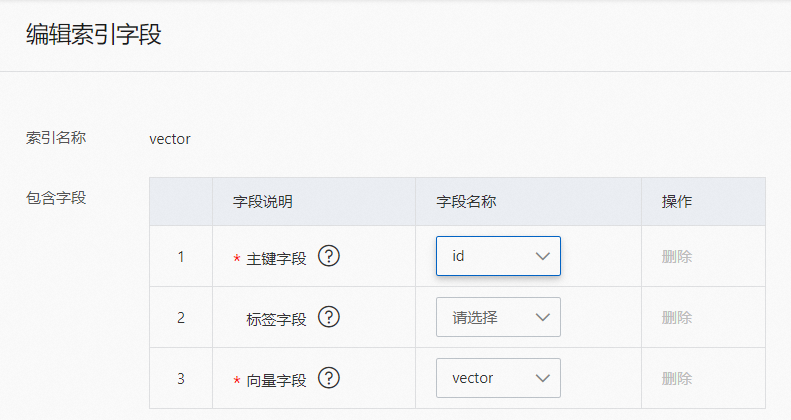
通过引擎将图片生成的向量,默认为512维,并且不支持修改。
schema示例:
"indexs": [
{
"index_name": "id",
"index_type": "PRIMARYKEY64",
"index_fields": "id",
"has_primary_key_attribute": true,
"is_primary_key_sorted": false
},
{
"index_name": "vector",
"index_type": "CUSTOMIZED",
"index_fields": [
{
"field_name": "id",
"boost": 1
},
{
"field_name": "vector",
"boost": 1
}
],
"parameters": {
"dimension": "512",
"distance_type": "SquaredEuclidean",
"vector_index_type": "Qc",
"build_index_params": "{\"proxima.qc.builder.quantizer_class\":\"Int8QuantizerConverter\",\"proxima.qc.builder.quantize_by_centroid\":true,\"proxima.qc.builder.optimizer_class\":\"BruteForceBuilder\",\"proxima.qc.builder.thread_count\":10,\"proxima.qc.builder.optimizer_params\":{\"proxima.linear.builder.column_major_order\":true},\"proxima.qc.builder.store_original_features\":false,\"proxima.qc.builder.train_sample_count\":3000000,\"proxima.qc.builder.train_sample_ratio\":0.5}",
"search_index_params": "{\"proxima.qc.searcher.scan_ratio\":0.01}",
"embedding_delimiter": ",",
"major_order": "col",
"linear_build_threshold": "5000",
"min_scan_doc_cnt": "20000",
"enable_recall_report": "false",
"is_embedding_saved": "false",
"enable_rt_build": "false",
"builder_name": "QcBuilder",
"searcher_name": "QcSearcher"
},
"indexer": "aitheta2_indexer"
}
]3、索引重建
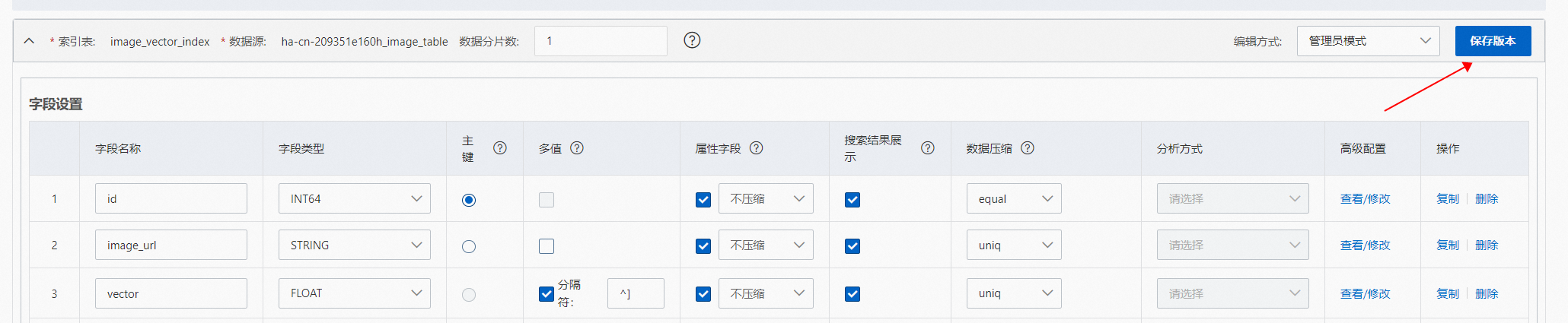
配置完成后,点击保存版本,并在弹框后填写备注(可选),点击发布:
等待索引发布完成后,可点击“下一步”进行索引重建:

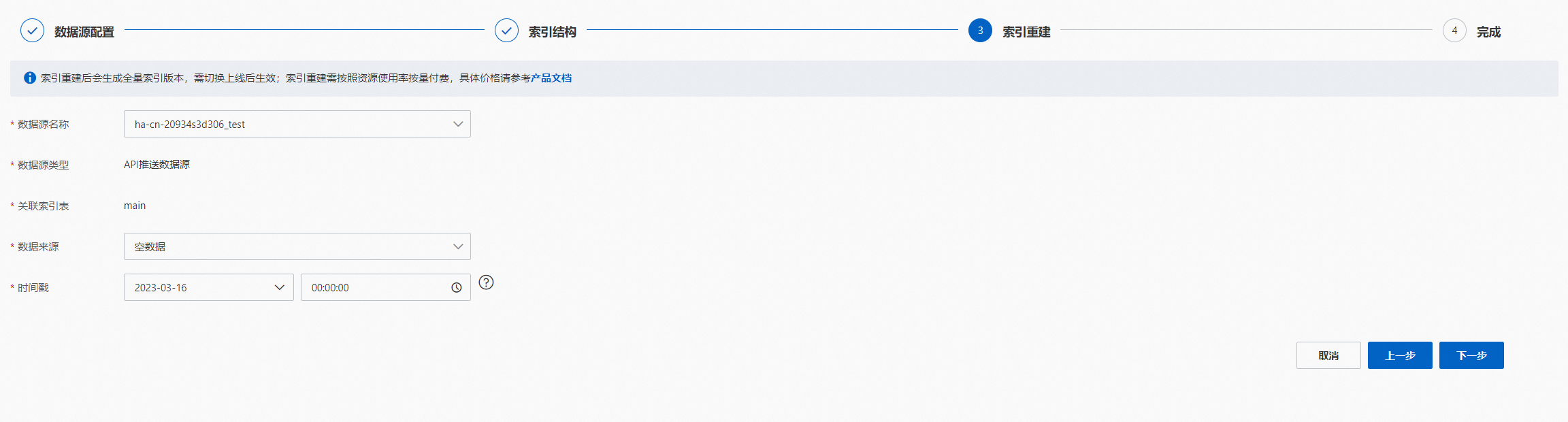
索引重建,选择索引重建需要配置的参数项,点击“下一步”:
API推送数据源:
MaxCompute数据源:
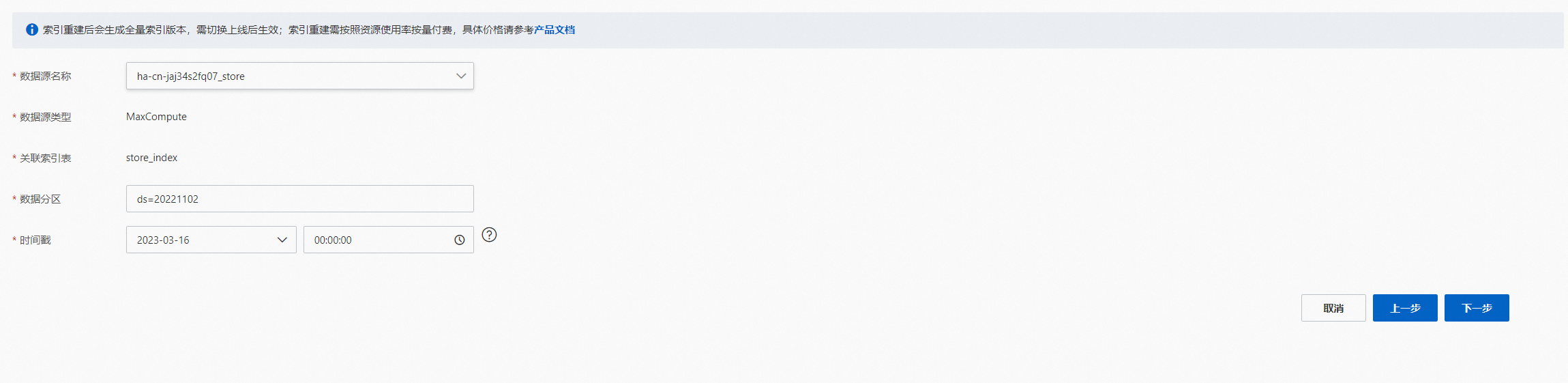
可在运维中心>历史变更>数据源变更查看索引重建进度,进度完成后即可进行查询测试:
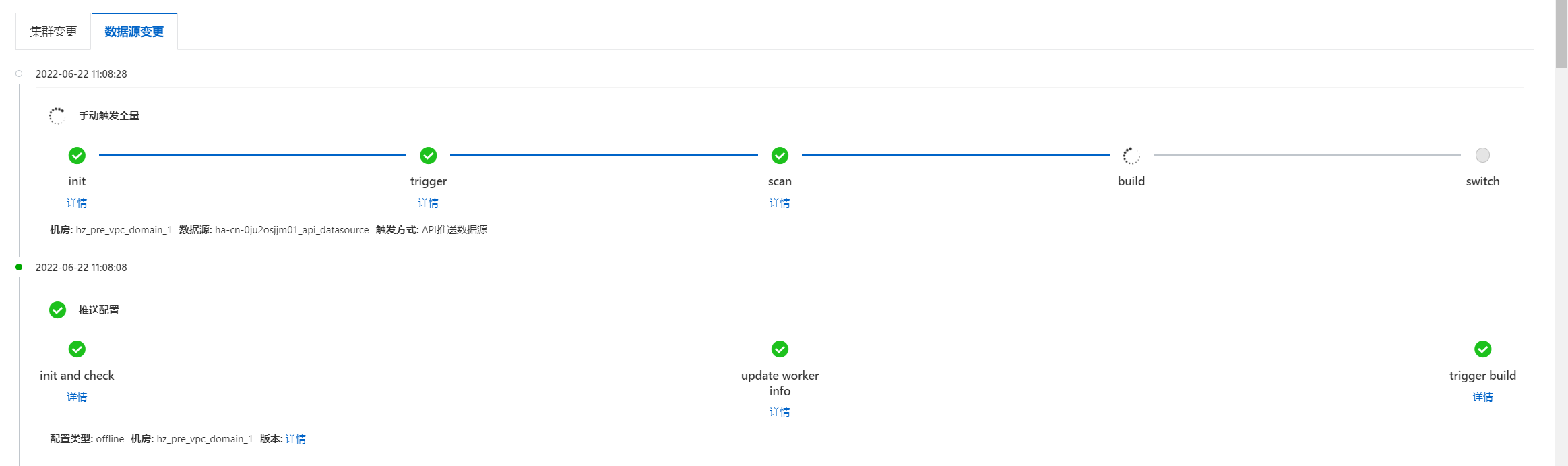
效果测试
语法介绍
query=image_index:'编码后的需要搜索的文本内容&modal=text&n=10&search_params={}'modal表示模态类型,以文搜图modal设置为
text,以图搜图modal设置为imagen表示指定向量检索返回的top结果数
文本内容需要经过base64编码
以文搜图
在查询测试页面通过HA查询:
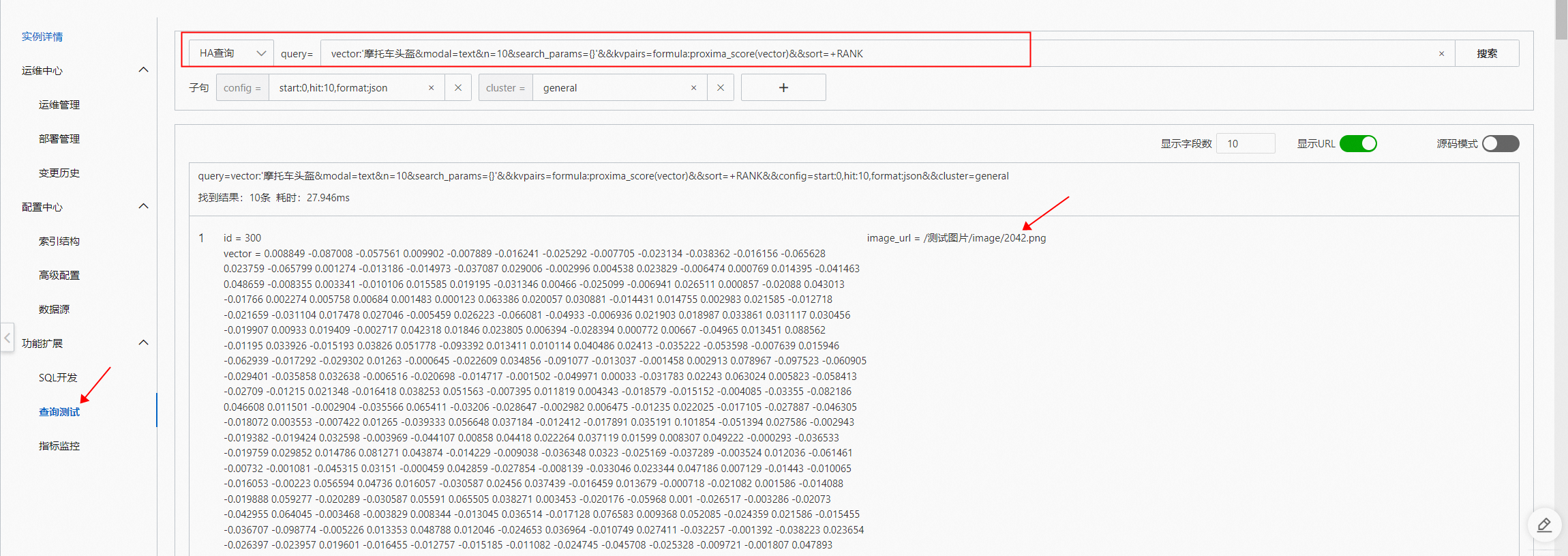
vector:'5pGp5omY6L2mJuWktOeblA==&modal=text&n=10&search_params={}'&&kvpairs=formula:proxima_score(vector)&&sort=+RANK在OSS中查看2042.png 图片:
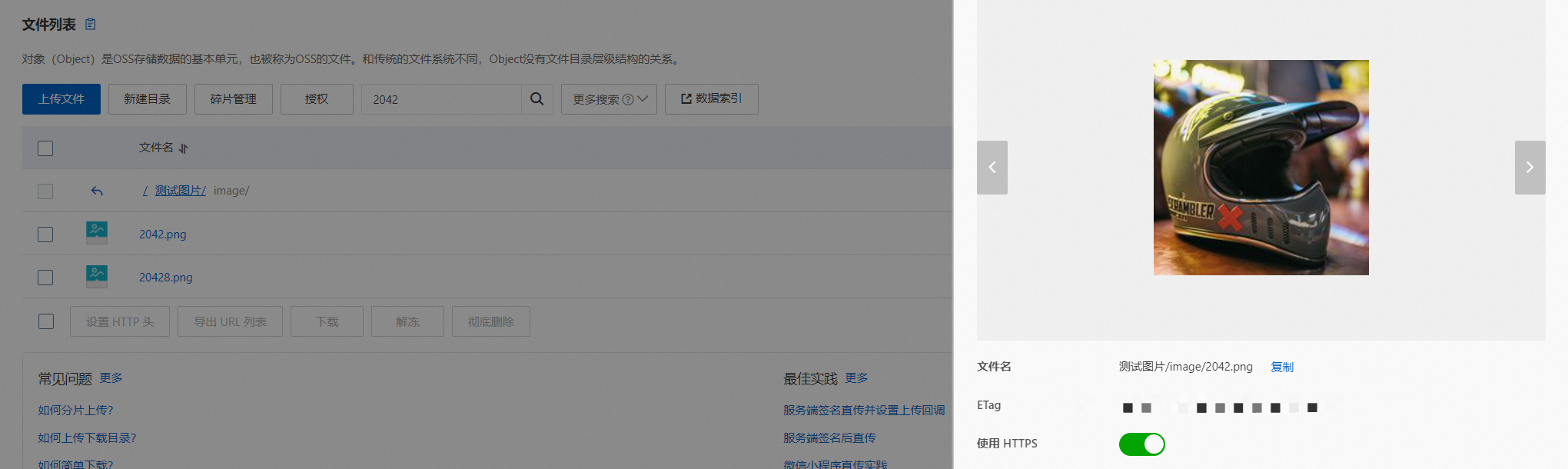
如果搜索的文本内容中特殊字符,需要进行base64编码,例如搜索内容为“摩托车&头盔”,则需要进行base64编码,结果为“5pGp5omY6L2mJuWktOeblA==”
以图搜图
由于图片编码后长度比较大,暂不支持直接在控制台查询测试页面进行搜索。用户可以通过SDK进行检索。
示例:
vector:'base64编码后的图片&modal=image&n=10&search_params={}'&&kvpairs=formula:proxima_score(vector)&&sort=+RANKSDK中检索数据
添加依赖:
pip install alibabacloud-ha3engine搜索 demo:
# -*- coding: utf-8 -*-
from alibabacloud_ha3engine import models, client
from alibabacloud_tea_util import models as util_models
from Tea.exceptions import TeaException, RetryError
def search():
Config = models.Config(
endpoint="参考实例详情页>API入口下的API域名",
instance_id="",
protocol="http",
access_user_name="购买实例时设置的用户名",
access_pass_word="购买实例时设置的密码"
)
# 如用户请求时间较长. 可通过此配置增加请求等待时间. 单位 ms
# 此参数可在 search_with_options 方法中使用
runtime = util_models.RuntimeOptions(
connect_timeout=5000,
read_timeout=10000,
autoretry=False,
ignore_ssl=False,
max_idle_conns=50
)
# 初始化 Ha3Engine Client
ha3EngineClient = client.Client(Config)
optionsHeaders = {}
try:
# 示例1: 直接使用 ha 查询串进行搜索.
# =====================================================
query_str = "config=hit:4,format:json,fetch_summary_type:pk,qrs_chain:search&&query=image_index:'需要搜索的文本内容&modal=text&n=10&search_params={}'&&cluster=general"
haSearchQuery = models.SearchQuery(query=query_str)
haSearchRequestModel = models.SearchRequestModel(optionsHeaders, haSearchQuery)
hastrSearchResponseModel = ha3EngineClient.search(haSearchRequestModel)
print(hastrSearchResponseModel)
except TeaException as e:
print(f"send request with TeaException : {e}")
except RetryError as e:
print(f"send request with Connection Exception : {e}")其他SDK demo可参考开发指南
注意事项
如果对向量检索耗时有较严格的要求,建议向量索引lock内存
存储图片路径或者图片base64编码的字段需要设置为STRING
向量索引需要设置为CUSTOMIZED类型
该场景支持HA语法、RESTFUL API,不支持SQL