MaxCompute使用的Python 2版本为2.7。本文为您介绍如何通过Python 2语言编写UDAF。
UDAF代码结构
- 编码声明:可选。
固定声明格式为
#coding:utf-8或# -*- coding: utf-8 -*-,二者等效。当Python 2代码中出现中文字符时,运行程序会报错,您需要在代码头部增加编码声明。 - 导入模块:必选。
至少要包含
from odps.udf import annotate和from odps.udf import BaseUDAF。from odps.udf import annotate用于导入函数签名模块,MaxCompute才可以识别后续代码中定义的函数签名。from odps.udf import BaseUDAF为Python UDAF的基类,您需要通过此类在派生类中实现iterate、merge、terminate等方法。当UDAF代码中需要引用文件资源或表资源时,需要包含
from odps.distcache import get_cache_file(文件资源)或from odps.distcache import get_cache_table(表资源)。 - 函数签名:必选。
格式为
@annotate(<signature>),signature用于定义函数的输入参数和返回值的数据类型。更多函数签名信息,请参见函数签名及数据类型。 - 自定义Python类(派生类):必选。
UDAF代码的组织单位,定义了实现业务需求的变量及方法。您还可以在代码中引用MaxCompute内置的第三方库或引用文件、表资源。更多信息,请参见第三方库或引用资源。
- 实现Python类的方法:必选。
Python类实现包含如下4个方法,您可以根据实际需要进行选择。
方法定义 描述 BaseUDAF.new_buffer()返回聚合函数的中间值的buffer。 buffer必须是Marshal对象(例如LIST、DICT),并且buffer的大小不应该随数据量递增。在极限情况下,buffer在执行对象序列化后的大小不应该超过2 MB。BaseUDAF.iterate(buffer[, args, ...])将 args聚合到中间值buffer中。BaseUDAF.merge(buffer, pbuffer)将中间值 buffer和pbuffer合并的结果存放在buffer中。BaseUDAF.terminate(buffer)将 buffer转换为MaxCompute SQL的基本类型。
#coding:utf-8
#导入函数签名模块及基类。
from odps.udf import annotate
from odps.udf import BaseUDAF
#函数签名。
@annotate('double->double')
#自定义Python类。
class Average(BaseUDAF):
#实现Python类的方法。
def new_buffer(self):
return [0, 0]
def iterate(self, buffer, number):
if number is not None:
buffer[0] += number
buffer[1] += 1
def merge(self, buffer, pbuffer):
buffer[0] += pbuffer[0]
buffer[1] += pbuffer[1]
def terminate(self, buffer):
if buffer[1] == 0:
return 0.0
return buffer[0] / buffer[1]avg的MaxCompute UDAF的实现逻辑及计算流程如下。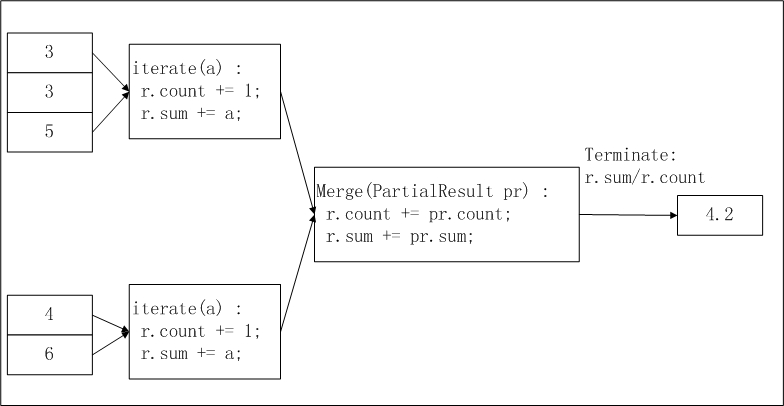
pbuffer相当于上图中的pr,buffer相当于上图中的r。使用限制
- 读写本地文件。
- 启动子进程。
- 启动线程。
- 使用Socket通信。
- 其他系统调用。
- 所有基于标准Python实现(不依赖扩展模块)的模块都可用。
- C扩展模块中下列模块可用:
- array、audioop
- binascii、bisect
- cmath、_codecs_cn、_codecs_hk、_codecs_iso2022、_codecs_jp、_codecs_kr、_codecs_tw、_collections、cStringIO
- datetime
- _functools、future_builtins、
- _heapq、_hashlib
- itertools
- _json
- _locale、_lsprof
- math、_md5、_multibytecodec
- operator
- _random
- _sha256、_sha512、_sha、_struct、strop
- time
- unicodedata
- _weakref
- cPickle
- 沙箱限制了您的代码最多可向标准输出和标准错误输出写入数据的大小为20 KB,即
sys.stdout/sys.stderr最多能写入20 KB数据,多余的字符会被忽略。
第三方库
函数签名及数据类型
@annotate(<signature>)signature为字符串,用于标识输入参数和返回值的数据类型。执行UDAF时,UDAF函数的输入参数和返回值类型要与函数签名指定的类型一致。查询语义解析阶段会检查不符合函数签名定义的用法,检查到类型不匹配时会报错。具体格式如下。'arg_type_list -> type'arg_type_list:表示输入参数的数据类型。输入参数可以为多个,用英文逗号(,)分隔。支持的数据类型为BIGINT、STRING、DOUBLE、BOOLEAN、DATETIME、DECIMAL、FLOAT、BINARY、DATE、DECIMAL(precision,scale)、CHAR、VARCHAR、复杂数据类型(ARRAY、MAP、STRUCT)或复杂数据类型嵌套。arg_type_list还支持星号(*)或为空(''):- 当
arg_type_list为星号(*)时,表示输入参数为任意个数。 - 当
arg_type_list为空('')时,表示无输入参数。
- 当
type:表示返回值的数据类型。UDAF只返回一列。支持的数据类型为:BIGINT、STRING、DOUBLE、BOOLEAN、DATETIME、DECIMAL、FLOAT、BINARY、DATE、DECIMAL(precision,scale)、复杂数据类型(ARRAY、MAP、STRUCT)或复杂数据类型嵌套。
合法函数签名示例如下。
| 函数签名示例 | 说明 |
|---|---|
@annotate('bigint,double->string') | 输入参数类型为BIGINT、DOUBLE,返回值类型为STRING。 |
@annotate('*->string') | 输入任意个参数,返回值类型为STRING。 |
@annotate('->double') | 无输入参数,返回值类型为DOUBLE。 |
@annotate('array<bigint>->struct<x:string, y:int>') | 输入参数类型为ARRAY<BIGINT>,返回值类型为STRUCT<x:STRING, y:INT>。 |
为确保编写Python UDAF过程中使用的数据类型与MaxCompute支持的数据类型保持一致,您需要关注二者间的数据类型映射关系。具体映射关系如下。
| MaxCompute SQL Type | Python 2 Type |
|---|---|
| BIGINT | INT |
| STRING | STR |
| DOUBLE | FLOAT |
| BOOLEAN | BOOL |
| DATETIME | INT |
| FLOAT | FLOAT |
| CHAR | STR |
| VARCHAR | STR |
| BINARY | BYTEARRAY |
| DATE | INT |
| DECIMAL | DECIMAL.DECIMAL |
| ARRAY | LIST |
| MAP | DICT |
| STRUCT | COLLECTIONS.NAMEDTUPLE |
- DATETIME类型对应的Python类型是INT,值为Epoch UTC Time起至今的毫秒数。您可以通过Python标准库中的DATETIME模块处理日期时间类型。
odps.udf.int(value,[silent=True])增加了参数silent。当silent为True时,如果value无法转为INT,则会返回None(不会返回异常)。- NULL值对应Python的None。
引用资源
Python UDAF可以通过odps.distcache模块引用资源,支持引用文件资源和表资源。
odps.distcache.get_cache_file(resource_name):返回指定文件资源的内容。resource_name为STRING类型,对应当前MaxCompute项目中已存在的文件资源名。如果文件资源名非法或者没有相应的文件资源,会返回异常。说明 使用UDAF访问资源,在创建UDAF时需要声明引用的资源,否则会报错。- 返回值为File-like对象。在使用完此对象后,您需要调用
close方法释放打开的资源文件。
odps.distcache.get_cache_table(resource_name):返回指定表资源的内容。resource_name支持STRING类型,对应当前MaxCompute项目中已存在的表资源名。如果表资源名非法或者没有相应的表资源,会返回异常。- 返回值为GENERATOR类型,调用者以遍历方式获取表的内容,每次遍历可得到以数组形式存在的表中的一条记录。
具体使用方法请参见引用资源(Python UDF 2)和引用资源(Python UDTF 2)。
使用说明
- 在归属MaxCompute项目中使用自定义函数:使用方法与内建函数类似,您可以参照内建函数的使用方法使用自定义函数。
- 跨项目使用自定义函数:即在项目A中使用项目B的自定义函数,跨项目分享语句示例:
select B:udf_in_other_project(arg0, arg1) as res from table_t;。更多跨项目分享信息,请参见基于Package跨项目访问资源。
使用MaxCompute Studio完整开发及调用Python 2 UDAF的操作,请参见开发Python UDF。