云原生多模数据库 Lindorm流引擎是面向流式数据处理的引擎,提供了流式数据的存储和轻计算功能,帮助您轻松实现流式数据存储至云原生多模数据库 Lindorm,构建基于流式数据的处理和应用。本文介绍Lindorm流引擎的应用场景和功能特性。
产品架构
云原生多模数据库 Lindorm流引擎的架构图如下: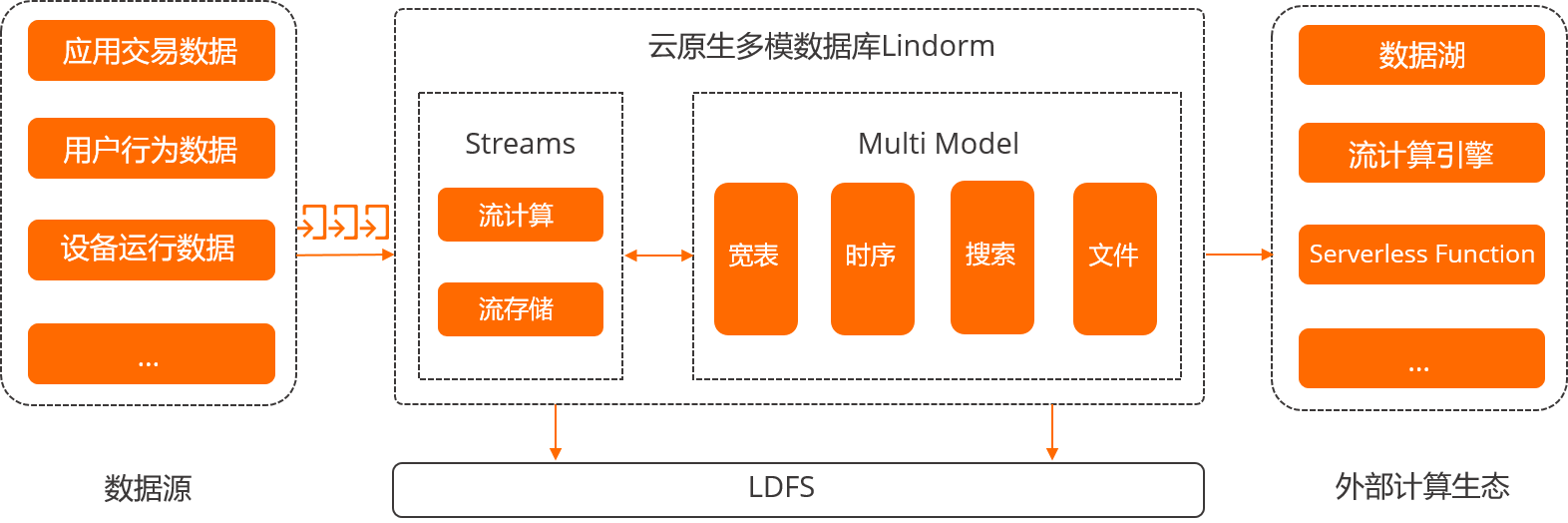
应用场景
Lindorm流引擎主要用于应用日志、物联网实时数据等流式数据存储至云原生多模数据库 Lindorm宽表引擎或者时序引擎。Lindorm流引擎的典型应用场景为ELT,流程如下。相比于传统的复杂组合方案(由Kafka、Flink和数据库组成),云原生多模数据库 Lindorm提供了一体化的存储、计算和查询能力,简化了运维操作,降低了开发成本。
将数据源写入至Lindorm流引擎,写入的数据格式包括CSV、Avro、JSON等。
通过Lindorm流引擎SQL对数据源进行过滤或者转化等轻量计算。
将计算结果同步至Lindorm宽表引擎或者时序引擎。
流程图如下: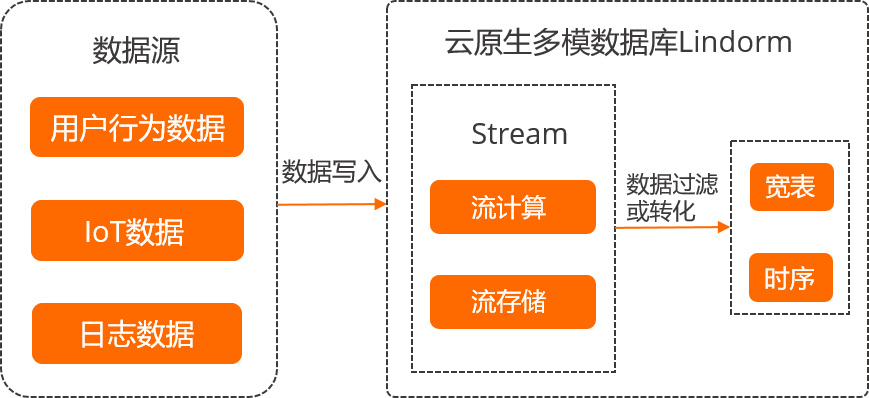
功能特性
Lindorm流引擎的功能特性分为三个方面:
Lindorm流引擎SQL
功能
说明
SQL客户端
支持JDBC协议,与SQL生态工具融合。
SQL语法
支持基本的DDL和DML操作。
多种类函数
通用的SQL函数、Lindorm内置函数、用户自定义函数。
可视化显示
通过控制台可以查看流处理链路信息。
窗口函数
支持流计算窗口函数。
Schema管理
功能
说明
Schema映射
可以将数据源映射成为Table Format。数据源的写入格式包括CSV、Avro、JSON等。
脏数据处理
在Schema映射过程中,由于数据类型不符合或者主键列为空会存在一些不符合Schema的数据,这类数据为脏数据。对于脏数据提供一些默认的处理机制,包括阻塞、忽略、 死信队列 等。
数据写入和数据存储
功能
说明
100%兼容Kafka协议
可以使用开源Kafka客户端写入数据到Lindorm流引擎。
存储和计算分离、存储容量大
Lindorm流引擎可以存储PB级别的数据,支持存储独立水平扩展。