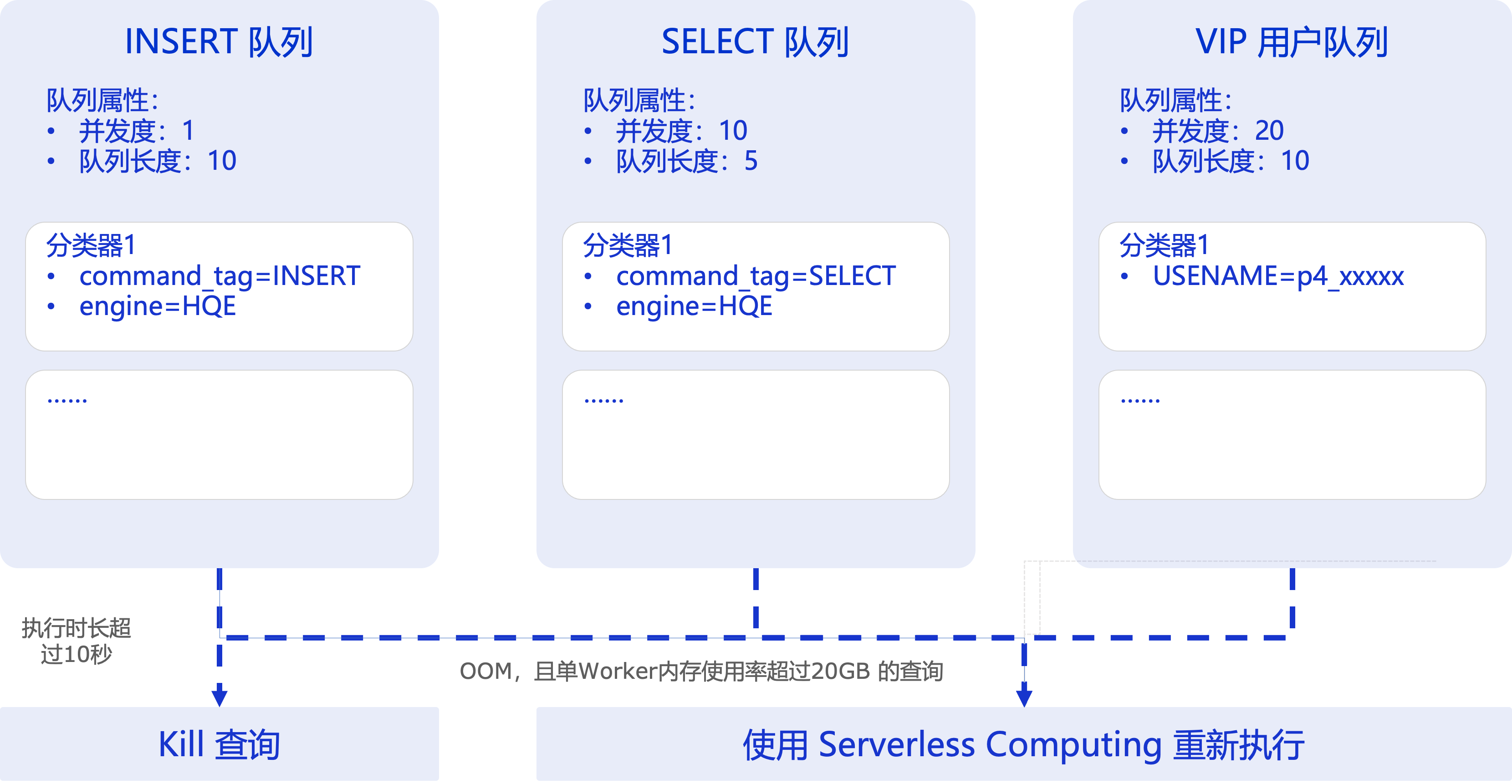
Hologres V3.0版本开始支持查询队列(Query Queue)功能,该功能可实现请求的有序处理、负载均衡和资源管理,特别是在高并发场景下,能够确保系统的稳定性和响应效率。
功能介绍
默认情况下,请求提交到实例后,没有任何并发控制,引擎的Coordinator将为请求分配资源执行。使用查询队列功能后,Hologres将根据查询队列中分类器已配置的匹配规则对SQL请求进行匹配,并将请求分配至不同的查询队列。每个查询队列都支持配置最大并发数,当请求数量达到最大并发数时,后续新请求会在相应的队列中等待,直至有可用的计算资源,方可开始执行。
注意事项
-
查询队列和优化器等配置适用于实例级别(通用型实例)或计算组级别(计算组型实例)。如果一个实例下存在多个数据库,则查询队列和优化器将对所有数据库生效。
-
仅Hologres V3.0及以上版本的通用型和计算组型实例支持查询队列功能。
说明若您的实例为V2.2或以下版本,请实例升级或加入实时数仓Hologres交流群申请升级实例。加入在线支持钉钉群请参见如何获取更多的在线支持?。
-
Hologres从V3.0.10版本起,支持设置某个查询队列的SQL全部使用Serverless Computing资源执行。查询队列的并发配置和排队机制仅对本地资源生效,使用Serverless Computing资源执行的查询不受查询队列并发配置和排队机制等因素影响。
-
每个通用型实例以及计算组型实例中的每个计算组,默认有一个
default_queue查询队列,且其最大并发限制和最大排队限制均不设限制。-
default_queue查询队列不支持创建分类器,只支持设置查询队列属性。 -
default_queue可以管理所有不能被其他查询队列匹配的请求。
-
-
每个通用型实例以及计算组型实例中的每个计算组,支持最多创建10个查询队列(包含
default_queue),每个查询队列最多可创建10个分类器。 -
只读从实例不支持单独启用查询队列功能,但可适用主实例的查询队列规则。
-
只有engine_type为
HQE、PQE、SQE和HiveQE查询,才会匹配查询队列,支持的Query类型包括SELECT、INSERT、UPDATE、DELETE以及COPY、CTAS等命令产生的INSERT语句。 -
Fixed Plan的Query不进入查询队列,不受查询队列并发等配置的控制。详情请参见Fixed Plan加速SQL执行。
-
一个分类器只能归属于一个查询队列,而一个查询队列可以创建多个分类器。
操作步骤
创建查询队列
-
语法
-
通用型实例
CALL hg_create_query_queue (query_queue_name, max_concurrency, max_queue_size); -
计算组型实例
CALL hg_create_query_queue (warehouse_name, query_queue_name, max_concurrency, max_queue_size);
-
-
参数说明
-
warehouse_name:可选,计算组名称。如果未配置warehouse_name参数,则默认在当前连接的计算组中创建查询队列。
说明仅计算组型实例需配置此参数。
-
query_queue_name:必填,查询队列名称,在当前实例或计算组中保持唯一,不可重复。
-
max_concurrency:可选,最大并发数。默认值:-1,表示没有任何并发限制,取值范围:[ -1 , 2147483647 )。
-
max_queue_size:可选,最大排队数量,指支持的最大排队SQL数量。默认值:-1,表示队列无限大,取值范围:[ -1 , 2147483647 )。
说明创建查询队列时仅支持配置max_concurrency和max_queue_size,其他属性配置详情,请参见配置查询队列属性。
-
-
示例
-
通用型实例
-- 创建名为insert_queue的查询队列,并配置最大并发度为10。注意此处的并发度参数无需添加单引号。 CALL hg_create_query_queue ('insert_queue', 10); -
计算组型实例
-- 在init_warehouse计算组中,创建名为insert_queue的查询队列,并配置最大并发度为10。 CALL hg_create_query_queue ('init_warehouse', 'insert_queue', 10);
-
创建分类器
-
语法
-
通用型实例
CALL hg_create_classifier (query_queue_name, classifier_name, priority); -
计算组型实例
CALL hg_create_classifier (warehouse_name, query_queue_name, classifier_name, priority);
-
-
参数说明
-
warehouse_name:可选,计算组名称。如果未配置warehouse_name参数,则默认使用当前连接的计算组。
说明仅计算组型实例需配置此参数。
-
query_queue_name:必填,待创建分类器的查询队列名称。
-
classifier_name:必填,分类器名称,在当前实例或计算组中保持唯一,不可重复。
-
priority:可选,分类器匹配优先级,数值越大优先级越高。默认值:50,取值范围:[ 1 , 100 ]。若您创建时未配置该参数,后续可通过配置分类器属性方式进行配置。
说明-
分类器的优先级越高,则匹配的顺序越靠前。
-
当多个分类器具有相同的优先级时,将依据查询队列和分类器名称的字典序进行匹配,优先匹配字典序较小的项。例如,queue_a(classifier_1) 的优先级高于 queue_b(classifier_1)。
-
-
-
示例
-
通用型实例
-- 在insert_queue的查询队列中,创建名为classifier_insert的分类器,匹配优先级为20,注意此处的优先级参数无需添加单引号。 CALL hg_create_classifier ('insert_queue', 'classifier_insert', 20); -
计算组型实例
-- 在init_warehouse计算组的insert_queue查询队列中,创建名为classifier_insert的分类器,匹配优先级为20 CALL hg_create_classifier ('init_warehouse', 'insert_queue', 'classifier_insert', 20);
-
配置分类器匹配规则
在查询列队中,可以通过为分类器配置匹配规则来进行SQL匹配,以确定SQL应进入相应的查询队列。
-
语法
-
通用型实例
CALL hg_set_classifier_rule_condition_value (query_queue_name, classifier_name, condition_name, condition_value); -
计算组型实例
CALL hg_set_classifier_rule_condition_value (warehouse_name, query_queue_name, classifier_name, condition_name, condition_value);
-
-
参数说明
名称
说明
warehouse_name
可选,计算组名称。如果未配置warehouse_name参数,则默认使用当前连接的计算组。
说明仅计算组型实例需配置此参数。
query_queue_name
必填,查询队列名称。
classifier_name
必填,待添加配置规则的分类器名称。
condition_name和condition_value
必填,当前支持的条件属性:
-
user_name:当前账号的UID。
-
command_tag:请求类型。取值:INSERT、SELECT、UPDATE、DELETE。
为了提高COPY操作的执行效率,Hologres是通过INSERT来实现COPY操作。因此,当INSERT操作的并发受到限制时,COPY操作的写入并发同样会受到影响。
-
db_name:数据库名称。
-
engine_type:请求使用的引擎。取值:HQE、PQE、SQE、HiveQE。建议自Hologres V3.1.18版本开始使用。
-
digest:SQL指纹。关于SQL指纹详情,请参见SQL指纹。
-
application_name:发起Query的应用。仅V3.0.9及以上版本支持该属性。
-
storage_mode:存储模式。取值:hot、cold。建议自Hologres V3.1.18版本或V3.1.8开始使用。
-
write_table:Query写入的表。格式为
<db_name>.<schema_name>.<table_name>。仅V3.1版本及以上版本支持该属性。 -
read_table:Query读取的表。仅V3.1版本及以上版本支持该属性。
分类器内可以设置多个属性,每个属性可以设置多条匹配规则,自Hologres V3.1.18版本起,属性和规则对应关系如下:
-
如果一个分类器内设置了多个属性的匹配规则:
-
不同属性之间是“且”的关系。例如:一个分类器包含user_name和command_tag两个属性的匹配规则,则二者需同时满足,才可归属到该分类器。
-
如果需要多个属性之前定义为“或”的关系(满足某个属性要求即可),则需创建多个分类器,并将这些分类器归属于同一查询队列。
-
-
在一个分类器内对同一个属性设置的匹配规则,有三种关系,分类如下:
-
user_name/command_tag/db_name/digest/application_name:
-
对同一个属性(例如:user_name),匹配规则配置的属性值集合为set_a。
-
Query的对应属性集合为set_b(该集合内有且仅有一个值)。
-
只要满足集合运算
set_b ⊆ set_a,Query就可匹配该规则。
-
-
storage_mode:
-
对同一个属性(目前仅有storage_mode),匹配规则配置的属性值集合为set_a。
-
Query的对应属性集合为set_b(可能有“hot”、“cold”或“hot, cold”三种取值)。
-
需要满足集合运算
set_a == set_b,Query才可匹配该规则。
-
-
engine_type/write_table/read_table:
-
对同一个属性(例如:read_table),匹配规则配置的属性值集合为set_a。
-
Query的对应属性集合为set_b(数量没有限制,可能有很多张表)。
-
只要满足集合运算
(set_a ∩ set_b) != ∅,Query就可匹配该规则。
-
-
说明-
每次只能配置一个条件属性,若条件值大小写敏感,则需要带上双引号。
-
若同一种条件属性需匹配多个条件值,则需进行多次设置。例如:若分类器对command_tag为SELECT和INSERT的请求均需匹配,则需执行两条SQL语句进行设置。
-
-
示例
以计算组型实例为例(通用型实例仅需删去第一个入参)。为默认计算组init_warehouse创建查询队列test_queue:
CALL hg_create_query_queue ('init_warehouse', 'test_queue');-
示例一:用户p4_123、p4_456,或SQL指纹xxx、yyy,满足任意一个条件即归属查询队列test_queue。
-- 由于需要对用户和SQL指纹这两种属性设置“或”的关系,因此,需要设置两个分类器实现 -- 创建分类器classifier_user并绑定查询队列test_queue CALL hg_create_classifier ('init_warehouse', 'test_queue', 'classifier_user'); -- 设置按用户属性的匹配规则,用户“p4_123”或“p4_456”均可命中该分类器 CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_user', 'user_name', 'p4_123'); CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_user', 'user_name', 'p4_456'); -- 创建分类器classifier_digest并绑定查询队列test_queue CALL hg_create_classifier ('init_warehouse', 'test_queue', 'classifier_digest'); -- 设置按SQL指纹属性的匹配规则,SQL指纹“xxx”或“yyy”均可命中该分类器 CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_digest', 'digest', 'xxx'); CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_digest', 'digest', 'yyy'); -
示例二:由应用xx_bi发起,且同时访问了冷存和热存,所有条件需同时满足,才归属查询队列test_queue。
-- 由于需要对应用和存储类型这两种属性设置“且”的关系,因此,在同一个分类器内定义两种属性 -- 创建分类器classifier_3并绑定查询队列test_queue CALL hg_create_classifier ('init_warehouse', 'test_queue', 'classifier_3'); -- 设置按应用属性的匹配规则 CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_3', 'application_name', 'xx_bi'); -- 设置按存储类型的匹配规则,设置“hot”和“cold”两条,则需Query同时访问冷存和热存,才满足该匹配规格 CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_3', 'storage_mode', 'hot'); CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_3', 'storage_mode', 'cold'); -
示例三:所有访问了冷存数据的请求,均归属查询队列test_queue。
-- 由于存储类型的值需要完全匹配,“所有访问了冷存数据”的请求需拆分成如下两个分类器,仅需进入一个分类器即可 -- 创建分类器classifier_cold_1并绑定查询队列test_queue CALL hg_create_classifier ('init_warehouse', 'test_queue', 'classifier_cold_1'); -- storage_mode仅为cold的Query进入该队列 CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_cold_1', 'storage_mode', 'cold'); -- 创建分类器classifier_cold_2并绑定查询队列test_queue CALL hg_create_classifier ('init_warehouse', 'test_queue', 'classifier_cold_2'); -- storage_mode同时包含hot和cold的Query进入该队列 CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_cold_2', 'storage_mode', 'hot'); CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_cold_2', 'storage_mode', 'cold'); -
示例四:所有读取了表a且写入表b的请求,归属查询队列test_queue。
-- 由于需要对读表和写表类型这两种属性设置“且”的关系,因此,在同一个分类器内定义两种属性 -- 创建分类器classifier_table并绑定查询队列test_queue CALL hg_create_classifier ('init_warehouse', 'test_queue', 'classifier_table'); -- 设置按读表的匹配规则,只要请求读取了表a数据,不论其是否读取其他表数据,均满足该匹配规则 CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_3', 'read_table', 'db_name.schema_name.a'); -- 设置按写表的匹配规则,写入b表的请求,满足该匹配规则 CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_3', 'write_table', 'db_name.schema_name.b');
-
更多操作
大查询控制
为了有效控制大查询对实例的影响,可以通过查询队列进行管理并控制执行时长及内存溢出(OOM)。对于超过执行时长或内存溢出(OOM)指定阈值的查询,可以选择终止请求或使用Serverless Computing资源进行重运行。
-
Hologres V3.0版本仅支持SELECT查询Rerun。在进行查询Rerun时,如果使用FETCH来获取数据,为了确保结果的准确性,仅当FETCH未能获得任何数据时,才支持按照已配置的查询队列规则进行查询Rerun。
-
Query实际执行过程中,会包含optimization_cost(生成执行计划)、start_query_cost(查询启动)、get_next_cost(查询执行)三部分,详情请参见慢Query日志查看与分析。Query Queue的“大查询控制”能力,仅考虑get_next_cost(查询执行)部分的时长,不考虑排队等待资源、等锁等时长。
-
执行时长查询控制
您可以通过配置big_query_execution_time_threshold_sec参数设置执行时长(单位:s)。默认值为-1,表示不做任何限制。取值范围:[-1,2147483647)。示例如下:
-
场景1:执行时长超长查询熔断
对于进入select_queue队列的查询,会使用本实例资源执行。如果执行时长超过10秒,则自动熔断,终止查询。
CALL hg_set_query_queue_property ('select_queue', 'big_query_execution_time_threshold_sec', '10'); -
场景2:执行时长超长查询重跑
对于进入select_queue队列的查询,会使用本实例资源执行。如果执行时长超过10秒,则自动在本实例资源中熔断,并使用Serverless Computing资源重跑。
CALL hg_set_query_queue_property ('select_queue', 'big_query_execution_time_threshold_sec', '10'); CALL hg_set_query_queue_property ('select_queue', 'enable_rerun_as_big_query_when_exceeded_execution_time_threshold', 'true'); CALL hg_set_query_queue_property ('select_queue', 'rerun_big_query_on_computing_resource', 'serverless');说明-
enable_rerun_as_big_query_when_exceeded_execution_time_threshold:SQL执行超过执行时长,请求被终止后,是否使用其他资源重跑。默认值为false。
-
rerun_big_query_on_computing_resource:指定重新执行SQL请求的Serverless Computing资源名称。
-
-
-
内存溢出(OOM)大查询重跑
对于进入select_queue队列的查询会使用本实例资源执行。如果查询发生OOM,且该查询占用单个Worker的内存超过10 GB时,使用Serverless Computing重跑。其中,参数big_query_mem_threshold_when_oom_gb控制OOM查询的内存阈值,默认值为-1,表示不做任何限制,取值范围:[-1,64)。示例如下:
CALL hg_set_query_queue_property ('select_queue', 'big_query_mem_threshold_when_oom_gb', '10'); CALL hg_set_query_queue_property ('select_queue', 'enable_rerun_as_big_query_when_oom_exceeded_mem_threshold', 'true'); CALL hg_set_query_queue_property ('select_queue', 'rerun_big_query_on_computing_resource', 'serverless');
查询队列管理
删除查询队列
-
语法
-
通用型实例
CALL hg_drop_query_queue (query_queue_name); -
计算组型实例
CALL hg_drop_query_queue (warehouse_name, query_queue_name);
-
-
参数说明
-
warehouse_name:可选,计算组名称。如果未配置warehouse_name参数,则默认使用当前连接的计算组。
说明仅计算组型实例需配置此参数。
-
query_queue_name:必填,查询队列名称。
-
-
示例
-
通用型实例
-- 删除insert_queue查询队列 CALL hg_drop_query_queue ('insert_queue'); -
计算组型实例
-- 在init_warehouse计算组中,删除insert_queue查询队列 CALL hg_drop_query_queue ('init_warehouse', 'insert_queue');
删除查询队列的属性
-
语法
-
通用型实例
CALL hg_remove_query_queue_property (query_queue_name, property_key); -
计算组型实例
CALL hg_remove_query_queue_property (warehouse_name, query_queue_name, property_key);
-
-
参数说明
-
warehouse_name:可选,计算组名称。如果未配置warehouse_name参数,则默认使用当前连接的计算组。
说明仅计算组型实例需配置此参数。
-
query_queue_name:必填,查询队列名称。
-
property_key:必填,属性名。当前支持的相关属性:max_concurrency、max_queue_size、queue_timeout_ms。关于属性详情,请参见配置查询队列属性。
-
-
示例
-
通用型实例
-- 删除insert_queue查询队列的最大并发数属性 CALL hg_remove_query_queue_property('insert_queue', 'max_concurrency'); -- 删除insert_queue查询队列的最大排队数属性 CALL hg_remove_query_queue_property('insert_queue', 'max_queue_size'); -- 删除insert_queue查询队列的最大排队时间属性 CALL hg_remove_query_queue_property('insert_queue', 'queue_timeout_ms'); -
计算组型实例
-- 在init_warehouse计算组中,删除insert_queue查询队列的最大并发数属性 CALL hg_remove_query_queue_property('init_warehouse', 'insert_queue', 'max_concurrency'); -- 在init_warehouse计算组中,删除insert_queue查询队列的最大排队数设置 CALL hg_remove_query_queue_property('init_warehouse', 'insert_queue', 'max_queue_size'); -- 在init_warehouse计算组中,删除insert_queue查询队列的最大排队时间属性 CALL hg_remove_query_queue_property('init_warehouse', 'insert_queue', 'queue_timeout_ms');
-
查看查询队列元数据
查询队列的元数据存储于系统表hologres.hg_query_queues中。其主要包含的字段信息如下:
|
字段名称 |
字段类型 |
说明 |
|
warehouse_id |
INT |
计算组ID。 说明
通用型实例的warehouse_id字段值为0。 |
|
warehouse_name |
TEXT |
计算组名称。 说明
通用型实例的warehouse_name为空。 |
|
query_queue_name |
TEXT |
查询队列名称。 |
|
property_key |
TEXT |
属性名。 |
|
property_value |
TEXT |
属性值。 |
配置查询队列属性
-
语法
-
通用型实例
CALL hg_set_query_queue_property (query_queue_name, property_key, property_value); -
计算组型实例
CALL hg_set_query_queue_property (warehouse_name, query_queue_name, property_key, property_value);
-
-
参数说明
-
warehouse_name:可选,待配置查询队列属性的计算组名称。如果未配置warehouse_name参数,则默认使用当前连接的计算组。
说明仅计算组型实例需配置此参数。
-
query_queue_name:必填,待配置查询队列属性的查询队列名称。
-
property_key和property_value:必填,当前支持的相关属性:
-
max_concurrency:最大并发数。默认值:-1,表示没有任何并发限制,取值范围:[ -1 , 2147483647 )。
-
max_queue_size:最大排队数量,指支持的最大排队SQL数量。默认值:-1,表示队列无限大,取值范围:[ -1 , 2147483647 )。
-
queue_timeout_ms:最长排队时长(单位:ms),即在排队时长超过该值时,将自动关闭查询。默认值:-1,表示不限制排队时长,取值范围:[ -1 , 2147483647 )。
-
-
-
示例
-
通用型实例
-- 配置insert_queue查询队列的最大并发数为15 CALL hg_set_query_queue_property('insert_queue', 'max_concurrency', '15'); -- 配置insert_queue查询队列的最大排队数为15 CALL hg_set_query_queue_property('insert_queue', 'max_queue_size', '15'); -- 配置insert_queue的查询队列的最大排队时间为3000 ms CALL hg_set_query_queue_property('insert_queue', 'queue_timeout_ms', '3000'); -
计算组型实例
-- 在init_warehouse计算组中,设置insert_queue查询队列的最大并发数为15 CALL hg_set_query_queue_property('init_warehouse', 'insert_queue', 'max_concurrency', '15'); -- 在init_warehouse计算组中,设置insert_queue查询队列的最大排队数为15 CALL hg_set_query_queue_property('init_warehouse', 'insert_queue', 'max_queue_size', '15'); -- 在init_warehouse计算组中,设置insert_queue查询队列的最大排队时间为3000 ms CALL hg_set_query_queue_property('init_warehouse', 'insert_queue', 'queue_timeout_ms', '3000');
-
清空指定查询队列中正在排队的请求
-
语法
-
通用型实例
CALL hg_clear_query_queue (query_queue_name); -
计算组型实例
CALL hg_clear_query_queue (warehouse_name, query_queue_name);
-
-
参数说明
-
warehouse_name:可选,计算组名称。如果未配置warehouse_name参数,则默认使用当前连接的计算组。
说明仅计算组型实例需配置此参数。
-
query_queue_name:必填,查询队列名称。
-
-
示例
-
通用型实例
-- 清空select_queue查询队列中正在排队的所有请求 CALL hg_clear_query_queue ('select_queue'); -
计算组型实例
-- 清空init_warehouse计算组中,select_queue查询队列中正在排队的所有请求 CALL hg_clear_query_queue ('init_warehouse', 'select_queue');
-
分类器管理
删除分类器
-
语法
-
通用型实例
CALL hg_drop_classifier (query_queue_name, classifier_name); -
计算组型实例
CALL hg_drop_classifier (warehouse_name, query_queue_name, classifier_name);
-
-
参数说明
-
warehouse_name:可选,计算组名称。如果未配置warehouse_name参数,则默认使用当前连接的计算组。
说明仅计算组型实例需配置此参数。
-
query_queue_name:必填,待创建分类器的查询队列名称。
-
classifier_name:必填,分类器名称。
-
-
示例
-
通用型实例
-- 在insert_queue查询队列中,删除classifier_insert分类器 CALL hg_drop_classifier ('insert_queue', 'classifier_insert'); -
计算组型实例
-- 在init_warehouse计算组的insert_queue查询队列中,删除classifier_insert分类器 CALL hg_drop_classifier ('init_warehouse', 'insert_queue', 'classifier_insert');
-
删除分类器属性
-
语法
-
通用型实例
CALL hg_remove_classifier_property (query_queue_name, classifier_name, property_key); -
计算组型实例
CALL hg_remove_classifier_property (warehouse_name, query_queue_name, classifier_name, property_key);
-
-
参数说明
-
warehouse_name:可选,计算组名称。如果未配置warehouse_name参数,则默认使用当前连接的计算组。
说明仅计算组型实例需配置此参数。
-
query_queue_name:必填,查询队列名称。
-
classifier_name:必填,分类器名称。
-
property_key:必填,当前支持的相关属性:priority。关于分类器属性详情,请参见配置分类器属性。
-
-
示例
-
通用型实例
-- 在insert_queue查询队列中,删除classifier_insert分类器的优先级属性 CALL hg_remove_classifier_property ('insert_queue', 'classifier_insert', 'priority'); -
计算组型实例
-- 在init_warehouse计算组的insert_queue查询队列中,删除classifier_insert分类器的优先级属性 CALL hg_remove_classifier_property ('init_warehouse', 'insert_queue', 'classifier_insert', 'priority');
-
配置分类器属性
-
语法
-
通用型实例
CALL hg_set_classifier_property (query_queue_name, classifier_name, property_key, property_value); -
计算组型实例
CALL hg_set_classifier_property (warehouse_name, query_queue_name, classifier_name, property_key, property_value);
-
-
参数说明
-
warehouse_name:可选,计算组名称。如果未配置warehouse_name参数,则默认使用当前连接的计算组。
说明仅计算组型实例需配置此参数。
-
query_queue_name:必填,查询队列名称。
-
classifier_name:必填,分类器名称。
-
property_key和property_value:必填,当前支持的相关属性:
priority:分类器匹配优先级,数值越大优先级越高。默认值:50,取值范围:[ 1 , 100 ]。
说明-
分类器的优先级越高,则匹配的顺序越靠前。
-
当多个分类器具有相同的优先级时,将依据查询队列和分类器名称的字典序进行匹配,优先匹配字典序较小的项。例如,queue_a(classifier_1) 的优先级高于 queue_b(classifier_1)。
-
-
-
示例
-
通用型实例
-- 在insert_queue查询队列中,设置classifier_insert分类器的优先级为30 CALL hg_set_classifier_property ('insert_queue', 'classifier_insert', 'priority', '30'); -
计算组型实例
-- 在init_warehouse计算组的insert_queue的查询队列中,设置classifier_insert分类器的优先级为30 CALL hg_set_classifier_property ('init_warehouse', 'insert_queue', 'classifier_insert','priority', '30');
-
删除分类器匹配规则
-
删除分类器中指定条件属性(condition_name)的一条匹配规则
-
语法
-
通用型实例
CALL hg_remove_classifier_rule_condition_value (query_queue_name, classifier_name, condition_name, condition_value); -
计算组型实例
CALL hg_remove_classifier_rule_condition_value (warehouse_name, query_queue_name, classifier_name, condition_name, condition_value);
-
-
参数说明
-
warehouse_name:可选,计算组名称。如果未配置warehouse_name参数,则默认使用当前连接的计算组。
说明仅计算组型实例需配置此参数。
-
query_queue_name:必填,查询队列名称。
-
classifier_name:必填,分类器名称。
-
condition_name和condition_value:必填,待删除的条件属性名称和取值。当前支持的条件属性:user_name、command_tag、db_name、engine_type、digest、storage_mode。关于分类器匹配规则的条件属性详情,请参见配置分类器匹配规则。
-
-
示例
-
通用型实例
-- 在名为insert_queue的查询队列中,删除classifier_insert分类器中command_tag为INSERT的匹配规则 CALL hg_remove_classifier_rule_condition_value ('insert_queue', 'classifier_insert', 'command_tag', 'INSERT'); -- 在名为insert_queue的查询队列中,删除classifier_insert分类器中user_name为p4_12345的匹配规则 CALL hg_remove_classifier_rule_condition_value ('insert_queue', 'classifier_insert', 'user_name', 'p4_12345'); -- 在名为insert_queue的查询队列中,删除classifier_insert分类器中db_name为prd_db的匹配规则 CALL hg_remove_classifier_rule_condition_value ('insert_queue', 'classifier_insert', 'db_name', 'prd_db'); -- 在名为insert_queue的查询队列中,删除classifier_insert分类器中engine_type为HQE的匹配规则 CALL hg_remove_classifier_rule_condition_value ('insert_queue', 'classifier_insert', 'engine_type', 'HQE'); -- 在名为insert_queue的查询队列中,删除classifier_insert分类器中digest为md5edb3161000a003799a5d3f2656b70b4c的匹配规则 CALL hg_remove_classifier_rule_condition_value ('insert_queue', 'classifier_insert', 'digest', 'md5edb3161000a003799a5d3f2656b70b4c'); -- 在名为insert_queue的查询队列中,删除classifier_insert分类器中storage_mode为hot的匹配规则 CALL hg_remove_classifier_rule_condition_value ('insert_queue', 'classifier_insert', 'storage_mode', 'hot'); -
计算组型实例
-- 在init_warehouse计算组的insert_queue查询队列中,删除classifier_insert分类器中command_tag为INSERT的匹配规则 CALL hg_remove_classifier_rule_condition_value ('init_warehouse', 'insert_queue', 'classifier_insert', 'command_tag', 'INSERT'); -- 在init_warehouse计算组的insert_queue查询队列中,删除classifier_insert分类器中user_name为p4_12345的匹配规则 CALL hg_remove_classifier_rule_condition_value ('init_warehouse', 'insert_queue', 'classifier_insert', 'user_name', 'p4_12345'); -- 在init_warehouse计算组的insert_queue查询队列中,删除classifier_insert分类器中db_name为prd_db的匹配规则 CALL hg_remove_classifier_rule_condition_value ('init_warehouse', 'insert_queue', 'classifier_insert', 'db_name', 'prd_db'); -- 在init_warehouse计算组的insert_queue查询队列中,删除classifier_insert分类器中engine_type为HQE的匹配规则 CALL hg_remove_classifier_rule_condition_value ('init_warehouse', 'insert_queue', 'classifier_insert', 'engine_type', 'HQE'); -- 在init_warehouse计算组的insert_queue查询队列中,删除classifier_insert分类器中digest为md5edb3161000a003799a5d3f2656b70b4c的匹配规则 CALL hg_remove_classifier_rule_condition_value ('init_warehouse', 'insert_queue', 'classifier_insert', 'digest', 'md5edb3161000a003799a5d3f2656b70b4c'); -- 在init_warehouse计算组的insert_queue查询队列中,删除classifier_insert的分类器中storage_mode为hot的匹配规则 CALL hg_remove_classifier_rule_condition_value ('init_warehouse', 'insert_queue', 'classifier_insert', 'storage_mode', 'hot');
-
-
-
删除分类器中指定条件属性(condition_name)的所有匹配规则
-
语法
-
通用型实例
CALL hg_remove_classifier_rule_condition (query_queue_name, classifier_name, condition_name); -
计算组型实例
CALL hg_remove_classifier_rule_condition (warehouse_name, query_queue_name, classifier_name, condition_name);
-
-
参数说明
-
warehouse_name:可选,计算组名称。如果未配置warehouse_name参数,则默认使用当前连接的计算组。
说明仅计算组型实例需配置此参数。
-
query_queue_name:必填,查询队列名称。
-
classifier_name:必填,分类器名称。
-
condition_name:必填,待删除的条件属性名称。关于分类器匹配规则的条件属性详情,请参见配置分类器匹配规则。条件属性当前支持的条件属性user_name、command_tag、db_name、engine_type、digest、storage_mode。
-
-
示例
-
通用型实例
-- 在名为insert_queue的查询队列中,删除classifier_insert分类器中command_tag相关的所有匹配规则 CALL hg_remove_classifier_rule_condition ('insert_queue', 'classifier_insert', 'command_tag'); -- 在名为insert_queue的查询队列中,删除名为classifier_insert的分类器中 user_name 相关的所有匹配规则 CALL hg_remove_classifier_rule_condition ('insert_queue', 'classifier_insert', 'user_name'); -- 在名为insert_queue的查询队列中,删除名为classifier_insert的分类器中 db_name 相关的所有匹配规则 CALL hg_remove_classifier_rule_condition ('insert_queue', 'classifier_insert', 'db_name'); -- 在名为insert_queue的查询队列中,删除名为classifier_insert的分类器中 engine_type 相关的所有匹配规则 CALL hg_remove_classifier_rule_condition ('insert_queue', 'classifier_insert', 'engine_type'); -- 在名为insert_queue的查询队列中,删除名为classifier_insert的分类器中 digest 相关的所有匹配规则 CALL hg_remove_classifier_rule_condition ('insert_queue', 'classifier_insert', 'digest'); -- 在名为insert_queue的查询队列中,删除名为classifier_insert的分类器中 storage_mode 相关的所有匹配规则 CALL hg_remove_classifier_rule_condition ('insert_queue', 'classifier_insert', 'storage_mode'); -
计算组型实例
-- 在init_warehouse计算组的insert_queue查询队列中,删除名为classifier_insert的分类器中command_tag相关的所有匹配规则 CALL hg_remove_classifier_rule_condition ('init_warehouse', 'insert_queue', 'classifier_insert', 'command_tag'); -- 在init_warehouse计算组的insert_queue查询队列中,删除名为classifier_insert的分类器中user_name相关的所有匹配规则 CALL hg_remove_classifier_rule_condition ('init_warehouse', 'insert_queue', 'classifier_insert', 'user_name'); -- 在init_warehouse计算组的insert_queue查询队列中,删除名为classifier_insert的分类器中db_name相关的所有匹配规则 CALL hg_remove_classifier_rule_condition ('init_warehouse', 'insert_queue', 'classifier_insert', 'db_name'); -- 在init_warehouse计算组的insert_queue查询队列中,删除名为classifier_insert的分类器中engine_type相关的所有匹配规则 CALL hg_remove_classifier_rule_condition ('init_warehouse', 'insert_queue', 'classifier_insert', 'engine_type'); -- 在init_warehouse计算组的insert_queue查询队列中,删除名为classifier_insert的分类器中digest相关的所有匹配规则 CALL hg_remove_classifier_rule_condition ('init_warehouse', 'insert_queue', 'classifier_insert', 'digest'); -- 在init_warehouse计算组的insert_queue查询队列中,删除名为classifier_insert的分类器中storage_mode相关的所有匹配规则 CALL hg_remove_classifier_rule_condition ('init_warehouse', 'insert_queue', 'classifier_insert', 'storage_mode');
-
-
查看分类器元数据
分类器的元数据存储于系统表hologres.hg_classifiers中。其主要包含的字段信息如下:
|
字段 |
字段类型 |
说明 |
|
warehouse_id |
INT |
计算组ID。 说明
通用型实例的warehouse_id字段值为0。 |
|
warehouse_name |
TEXT |
计算组名称。 说明
通用型实例的warehouse_name为空。 |
|
query_queue_name |
TEXT |
查询队列名称。 |
|
classifier_name |
TEXT |
分类器名称。 |
|
property_key |
TEXT |
属性名。 |
|
property_value |
TEXT |
属性值。 |
使用Serverless Computing资源执行查询队列的查询
Hologres从V3.0.10版本起,支持指定某个查询队列中的查询全部由Serverless Computing资源执行。设置后,队列中的查询将按请求顺序和配置的优先级申请Serverless资源执行,不再受查询队列的并发配置、排队机制等因素影响。详情请参见Serverless Computing使用指南。
如果实例所在可用区不支持Serverless Computing,仍将使用本实例计算资源执行。
-
通用型实例
-
语法
-- 设置目标Queue中的查询全部通过Serverless资源运行 CALL hg_set_query_queue_property('<query_queue_name>', 'computing_resource', 'serverless'); -- (可选)设置目标Queue中的查询使用Serverless资源时的优先级,支持1-5,默认为3 CALL hg_set_query_queue_property('<query_queue_name>', 'query_priority_when_using_serverless_computing', '<priority>'); -
参数说明
-
query_queue_name:必填,查询队列名称。
-
priority:优先级,默认为3,取值范围
[1, 5]。
-
-
示例
-- 设置目标Queue中的查询全部通过Serverless资源运行 CALL hg_set_query_queue_property('insert_queue', 'computing_resource', 'serverless'); -- 设置目标Queue中的查询使用Serverless资源时的优先级为2 CALL hg_set_query_queue_property('insert_queue', 'query_priority_when_using_serverless_computing', '2');
-
-
计算组型实例
-
语法
-- 设置目标Queue中的查询全部通过Serverless资源运行 CALL hg_set_query_queue_property('<warehouse_name>', '<query_queue_name>', 'computing_resource', 'serverless'); -- (可选)设置目标Queue中的查询使用Serverless资源时的优先级,支持1-5,默认为3 CALL hg_set_query_queue_property('<warehouse_name>', '<query_queue_name>', 'query_priority_when_using_serverless_computing', '<priority>'); -
参数说明
-
warehouse_name:必填,计算组名称。
-
query_queue_name:必填,查询队列名称。
-
priority:必填,优先级,默认为3,取值范围
[1, 5]。
-
-
示例
-- 设置目标Queue中的查询全部通过Serverless资源运行 CALL hg_set_query_queue_property('init_warehouse', 'insert_queue', 'computing_resource', 'serverless'); -- 设置目标Queue中的查询使用Serverless资源时的优先级为2 CALL hg_set_query_queue_property('init_warehouse', 'insert_queue', 'query_priority_when_using_serverless_computing', '2');
-
常见场景
查看指定SQL使用的查询队列
通过EXPLAIN查看具体使用的查询队列,其中Query Queue字段即使用的查询队列。示例如下。
-- 创建查询队列,并发度为 10,最大排队数量为 20
CALL hg_create_query_queue ('select_queue', 10, 20);
-- 创建分类器并绑定 command_tag 属性
CALL hg_create_classifier ('select_queue', 'classifier_1');
CALL hg_set_classifier_rule_condition_value ('select_queue', 'classifier_1', 'command_tag', 'select');
-- 通过 Explain Analyze 查看 Query 所匹配的 Classifier 和 Query queue
EXPLAIN ANALYZE SELECT * FROM hg_stat_activity;返回结果如下。
QUERY PLAN
Gather (cost=0.00..14.96 rows=1000 width=408)
[4:1 id=100003 dop=1 time=16/16/16ms rows=142(142/142/142) mem=43/43/43KB open=0/0/0ms get_next=16/16/16ms]
-> Forward (cost=0.00..12.19 rows=1000 width=408)
[0:4 id=100002 dop=4 time=16/8/5ms rows=142(39/35/33) mem=6/6/6KB open=16/8/5ms get_next=0/0/0ms scan_rows=142(39/35/33)]
-> ExecuteExternalSQL on PQE (cost=0.00..10.04 rows=0 width=408)
" External SQL: SELECT "datid" AS c_d2adb610_0, "datname" AS c_d2adb760_1, "pid" AS c_d2adb8a0_2, "usesysid" AS c_d2adba10_3, "usename" AS c_d2adbb60_4, "application_name" AS c_d2adbd10_5, "client_addr" AS c_d2adbe80_6, "client_hostname" AS c_d2df1020_7, "client_port" AS c_d2df1190_8, "backend_start" AS c_d2df1300_9, "xact_start" AS c_d2df1470_10, "query_start" AS c_d2df15e0_11, "state_change" AS c_d2df1750_12, "wait_event_type" AS c_d2df18c0_13, "wait_event" AS c_d2df1a30_14, "state" AS c_d2df1b80_15, "backend_xid" AS c_d2df1cf0_16, "backend_xmin" AS c_d2df1e60_17, "query" AS c_d2df1fb0_18, "backend_type" AS c_d2df2120_19, "query_id" AS c_d2df2290_20, "transaction_id" AS c_d2df2400_21, "extend_info" AS c_d2df2570_22, "running_info" AS c_d2df26e0_23 FROM pg_catalog."hg_stat_activity""
Query id:[1001002491453065719]
Query Queue: init_warehouse.select_queue.classifier_1查看活跃Query中SQL使用的查询队列
可以通过如下SQL查看活跃Query中SQL使用的查询队列名称、当前状态和排队时间等信息。
SELECT
running_info::json -> 'current_stage' ->> 'stage_name' AS stage_name,
running_info::json -> 'current_stage' ->> 'queue_time_ms' AS queue_time_ms,
running_info::json ->> 'query_queue' AS query_queue,
*
FROM
hg_stat_activity;查看Query Log中SQL使用的查询队列
可以使用如下SQL查看Query Log中的SQL使用的查询队列、当前状态和排队时间,其中query_detail字段会记录SQL使用的查询队列。关于hologres.hg_query_log系统表详情,请参见查看query_log表。
SELECT * FROM hologres.hg_query_log WHERE query_detail like '%query_queue = <warehouse_name>.<queue_name>%';--仅计算组类型实例需配置该参数warehouse_name执行上述SQL返回的extended_info字段,包含以下信息:
-
serverless_computing_source:表示SQL来源,表示使用Serverless Computing资源执行的SQL。取值如下:-
user_submit:自行指定使用Serverless资源执行的SQL,与Query Queue无关。 -
query_queue:指定查询队列的SQL全部由Serverless资源执行。 -
query_queue_rerun:通过Query Queue的大查询控制功能,自动使用Serverless资源重新运行的SQL。
-
-
query_id_of_triggered_rerun:该字段仅在serverless_computing_source为query_queue_rerun时存在,表示重新运行的SQL对应的原始Query ID。
创建不同匹配规则的查询队列
-
示例1:创建请求类型为INSERT匹配规则的查询队列。示例如下。
创建完成后,所有INSERT类型的SQL请求将被classifier_1分类器匹配并分配到insert_queue查询队列。
-- 创建查询队列,并发度为 10,最大排队数量为 20 CALL hg_create_query_queue ('insert_queue', 10, 20); -- 创建分类器并绑定 command_tag 属性 CALL hg_create_classifier ('insert_queue', 'classifier_1'); CALL hg_set_classifier_rule_condition_value ('insert_queue', 'classifier_1', 'command_tag', 'INSERT'); -
创建用户为p4_123和p4_345匹配规则的查询队列。示例如下。
创建完成后,p4_123、p4_345用户提交的SQL请求将被classifier_2分类器匹配并分配到user_queue查询队列。
-- 创建查询队列,并发度为 3,最大排队数量为无穷大 CALL hg_create_query_queue ('user_queue', 3); CALL hg_set_query_queue_property('user_queue','max_queue_size', -1); -- 创建分类器并设置user_name匹配规则 CALL hg_create_classifier ('user_queue', 'classifier_2'); CALL hg_set_classifier_rule_condition_value ('user_queue', 'classifier_2', 'user_name', 'p4_123'); CALL hg_set_classifier_rule_condition_value ('user_queue', 'classifier_2', 'user_name', 'p4_345');说明若用户账号为自定义账号,则需要加上双引号,例如
CALL hg_set_classifier_rule_condition_value ('user_queue', 'classifier_2', 'user_name', '"BASIC$xxx"');。 -
创建数据库名称为test和postgres DB匹配规则的查询队列。示例如下。
创建完成后,test和postgres DB数据库相关的SQL请求将被classifier_3分类器匹配并分配到db_queue查询队列。
-- 创建查询队列,并发度为 5 CALL hg_create_query_queue ('db_queue', 5); -- 设置最大排队时间为600000 ms,排队超过这个时间则报错 CALL hg_set_query_queue_property ('db_queue', 'queue_timeout_ms', '600000'); -- 创建分类器并绑定 db_name 属性 CALL hg_create_classifier ('db_queue', 'classifier_3'); CALL hg_set_classifier_rule_condition_value ('db_queue', 'classifier_3', 'db_name', 'test'); CALL hg_set_classifier_rule_condition_value ('db_queue', 'classifier_3', 'db_name', 'postgres'); -
创建引擎类型为HQE匹配规则的查询队列。示例如下。
创建完成后,HQE引擎相关的SQL请求将被classifier_4分类器匹配并分配到hqe_queue查询队列。
-- 创建查询队列,并发度为10 CALL hg_create_query_queue ('hqe_queue', 10); -- 创建分类器并绑定engine_type属性 CALL hg_create_classifier ('hqe_queue', 'classifier_4'); CALL hg_set_classifier_rule_condition_value ('hqe_queue', 'classifier_4', 'engine_type', 'HQE');
禁止所有任务(极端场景)
将insert_queue查询队列的并发度和排队数设置为0。示例如下。
CALL hg_set_query_queue_property ('insert_queue', 'max_concurrency', '0');
CALL hg_set_query_queue_property ('insert_queue', 'max_queue_size', '0');