实时数仓Hologres是一款兼容PostgreSQL 11协议的实时数仓,与大数据生态无缝连接,支持高并发地实时写入,数据写入即可查,同时也支持离线数据的加速查询、实时数据和离线数据联邦分析,助力快速搭建企业级实时数仓。
Hologres数据同步说明
Hologres有着非常庞大的生态家族,支持多种异构数据源的离线、实时写入。
对于开源大数据:Hologres支持当下最流行的大数据开源组件,其中包括Flink、Blink和Spark等,通过内置的Hologres Connector实现高并发实时写入。
对于数据库类数据:Hologres与DataWorks数据集成(DataX和StreamX)深度集成,支持通过Hologres Writer和Hologres Reader,实现方便高效地将多种数据库数据离线、实时、整库同步至Hologres中,满足各类企业数据同步迁移的需求。
无论是实时数据,还是离线数据,同步至Hologres之后就能使用Hologres对数据进行多维分析,例如通过JDBC或者ODBC对数据进行查询、分析、监控,然后直接承接上游的业务例如大屏、报表、应用等可视化展现,实现数据从写入到服务分析一体化。具体使用流程如下所示: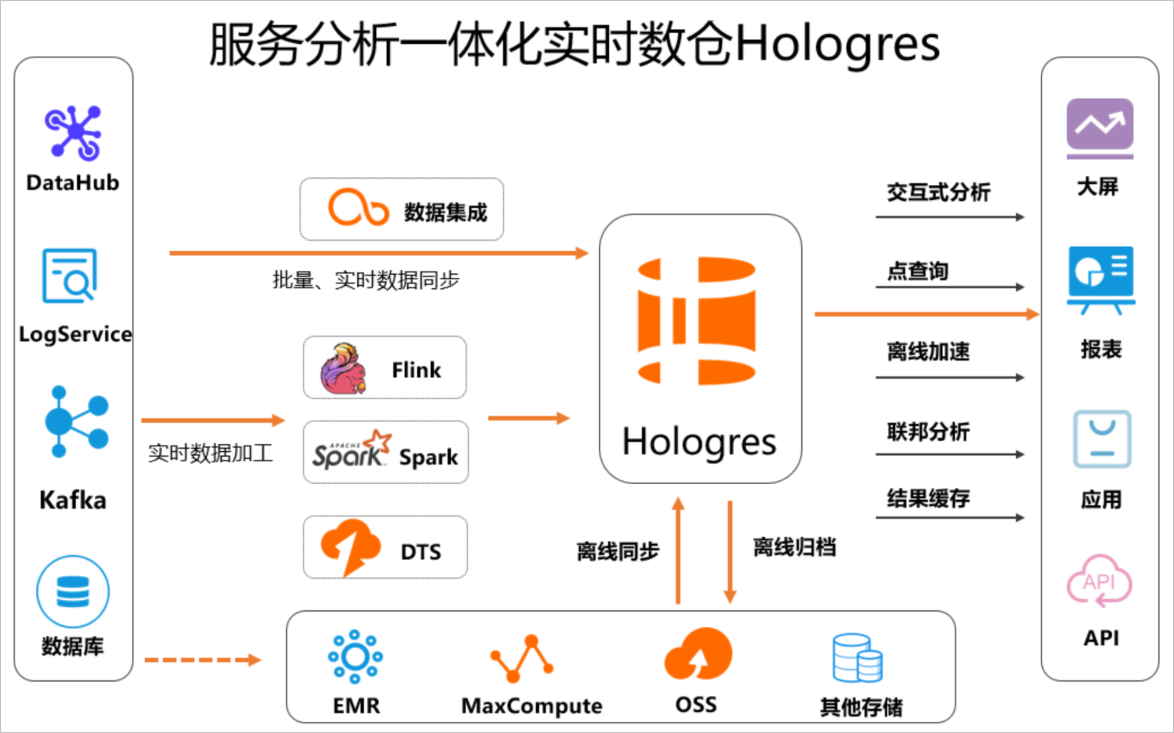
常见同步方案
常见数据源同步数据至Hologres的同步方式支持情况如下表所示,您可以根据业务情况选择合适的同步方式。
常见数据源 | Hologres内置同步方案 | DataWorks数据集成方式同步数据 | Flink方式同步数据 |
MaxCompute | 支持(推荐,SQL命令) | 支持 | 支持 |
OSS | 支持(推荐,SQL命令) | 支持 | 不支持 |
本地文件 | 支持(Copy命令) | 不支持 | 不支持 |
MySQL等数据库 | 不支持 | 支持(推荐) | 支持 |
Kafka | 不支持 | 支持 | 支持 |
DataHub | 支持(Hologres数据源直接写入) | 支持 | 支持 |
开源Connector支持
Hologres支持丰富的同步Connector如下表所示,并且这些Connector已经开源,请您根据业务情况自行选用。
Connector名称 | 适用场景 |
适用于大批量数据写入(批量、实时同步至Hologres)和高QPS点查(维表关联)场景,基于JDBC实现,也提供C语言和GO语言版本。 | |
将实例部分表导入导出的备份工具,适用于实例迁移或者数据库数据迁移的场景,也可以dump至中间存储再恢复。 | |
适配开源DataX,依赖DataX框架,适用开源DataX将多种数据源写入Hologres,相比PostgreSQL Writer性能更好。 | |
对接开源Flink,Flink版本包括1.11、1.12、1.13以及后续版本,实现高性能实时写入。 说明 阿里云Flink支持Hologres数据源,可以直接写入,无需引用connector。 | |
适用于Kafka直接写入Hologres的场景。 | |
适用于Spark(社区版以及阿里云EMR Spark版)写入Hologres的场景,支持Spark2.x、3.x及以上版本,提供高性能的写入。 | |
适用于Hive写入Hologres的场景,支持Hive2.x、3.x及以上版本,提供高性能的写入。 |