本文为您介绍Flink工作空间、项目空间以及作业管理及功能使用相关的问题,包括资源变配、查看工作空间ID、作业引擎版本、配置作业参数等。
工作空间与项目空间管理
作业管理
工作空间名称能否修改?
在实时计算管理控制台,单击目标工作空间操作列下的。
可以直接单击工作空间名称进行修改。
VPC和虚拟交换机能否更换?
目前暂不支持更换VPC,但支持修改虚拟交换机。
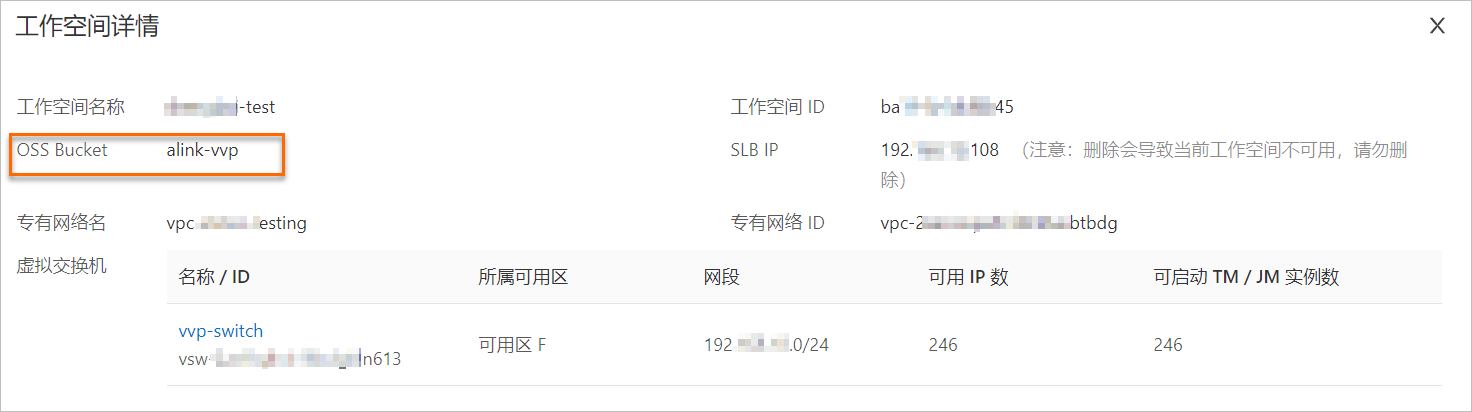
如何查看工作空间ID等信息?
在实时计算管理控制台,单击目标工作空间操作列下的,查看工作空间ID等信息。

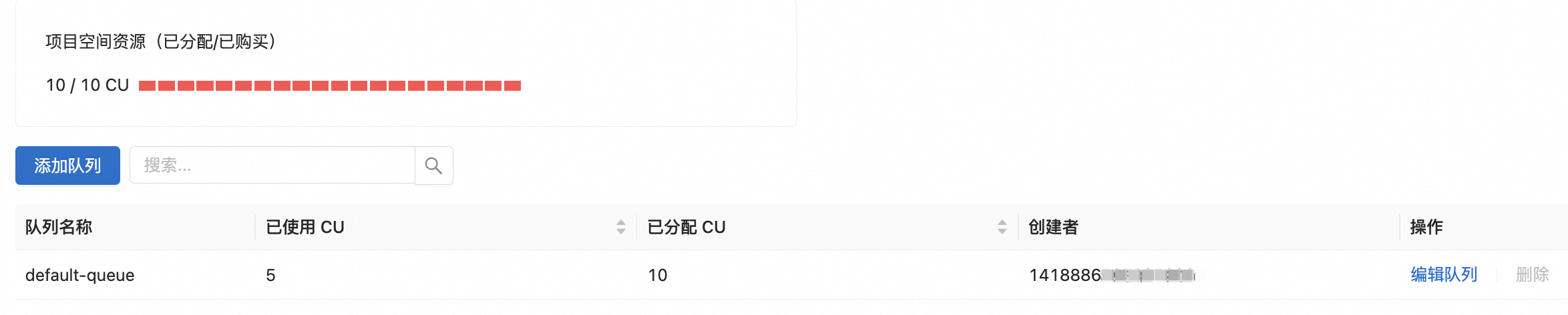
项目空间缩容时显示资源分配失败
问题详情
项目空间缩容时显示资源分配失败。

问题原因
当前所有资源已被分配或使用。
解决方法
需要先降低资源队列已分配资源,详情参见修改资源量,然后再缩容项目空间。
Flink计算资源升配后没生效

如何查看AccessKey ID和AccessKey Secret信息?
AccessKey ID
主账号:使用阿里云账号(主账号)登录阿里云控制台后,将鼠标悬浮在右上方的账号图标上,单击AccessKey管理进行查看。
RAM用户:查看RAM用户的AccessKey信息。
AccessKey Secret
为降低AccessKey泄露的风险,阿里云账号(主账号)和RAM用户的AccessKey Secret只在创建时显示,后续不支持查看,您需要在创建时妥善保管。
如果您没有或忘记AccessKey信息,具体操作请参见创建AccessKey。
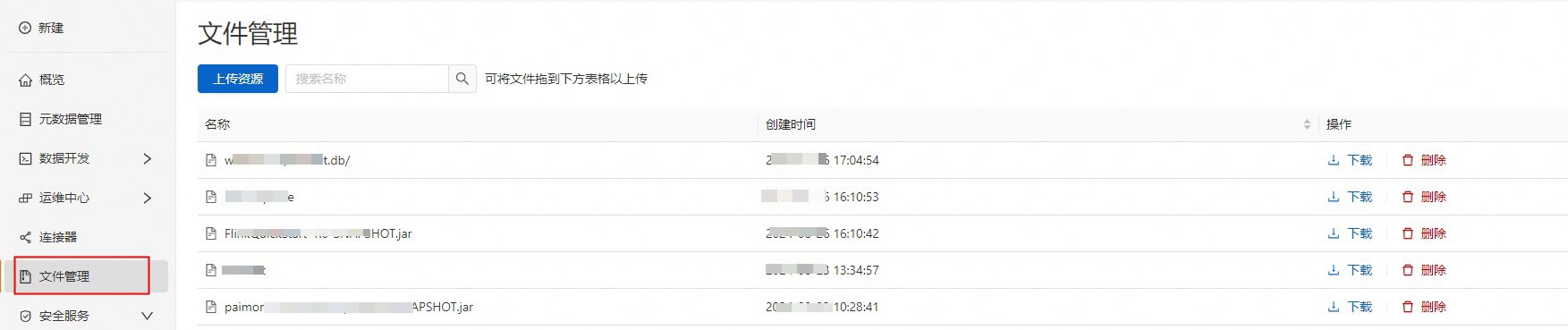
如何在OSS上传文件让Flink作业使用?
如果您在开通Flink工作空间时选择OSS Bucket存储类型,您可以通过在与工作空间绑定的OSS Bucket上传文件,并在Flink作业中使用。您也可以直接在实时计算开发控制台文件管理页面上传文件供Flink使用,详情请参见文件管理。
实时计算控制台未显示已开通的Flink工作空间?
您可以从以下几个方面排查问题,若仍无法解决,可以提交工单反馈。
确认Flink工作空间是否已完成初始化(通常需要5~10分钟)。
请确保实时计算控制台页面顶部选择了正确的地域,工作空间仅会在您开通时所选的地域中显示。
如果您是以RAM用户身份登录,请确保该用户具有实时计算管理控制台的相关权限。具体权限配置请参见权限管理。
报错:Has not enough ip address: abnormal event detected from kubernetes
报错详情
Has not enough ip address:abnormal event detected from kubernetes (type:[Warning], reason:[CniError_CodeUnKnownErr], message:[CniAllocateError: allocateIP failed: ipamCreate failed: failed to create ENI: all vSwitches ([*****]) cannot be used: CreateNetworkInterface: RequestId: 67959AE5-EA20-5CB4-8560-5BD6752472FD, ErrorCode: InvalidVSwitchId.IpNotEnough, Message: The specified VSwitch "*****" has not enough IpAddress., elapsedTime: 245.03232ms])报错原因
虚拟交换机没有可用IP。
解决方案
新建可用IP,详情请参见修改虚拟交换机。
报错:Unknown Error: Http failure response for xxxxx
报错详情
上传文件失败,且提示如下报错信息。

报错原因
在阿里云控制台国际站域名改造后,使用alibabacloud.com新域名进行文件上传时,如果未提前在对象存储OSS上配置跨域规则(CORS),请求将会因跨域限制而失败。
解决方案
在OSS控制台上,对Flink工作空间绑定的OSS Bucket设置跨域规则,具体的设置方法请参见文件管理。
如何查看当前作业的Flink版本?
您可以通过以下方式查看:
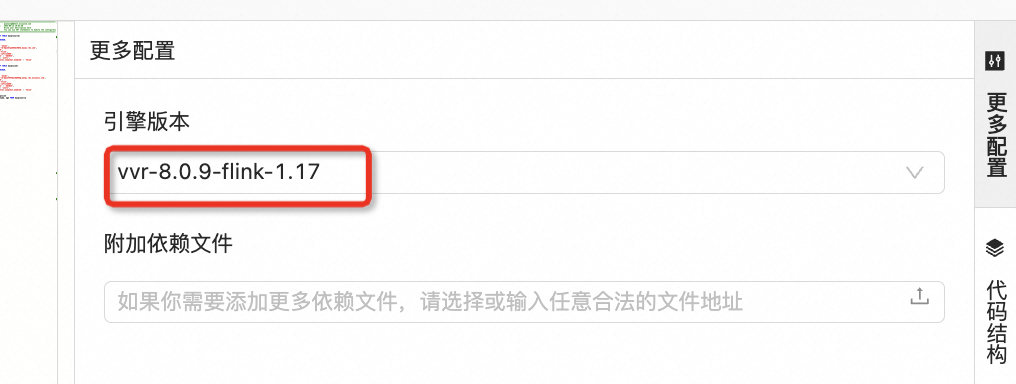
在ETL或数据摄入页面右侧,单击更多配置,在引擎版本项中查看版本信息。
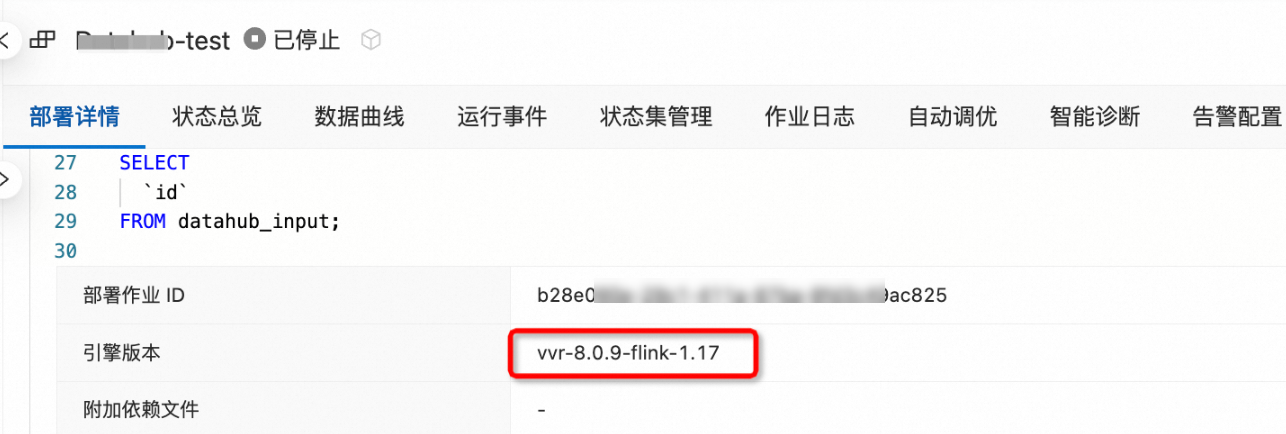
在页面,单击目标作业名称,在部署详情页签基础配置区域,查看版本信息。
如何修改实时计算Flink版的引擎版本?
SQL或YAML作业
在ETL或数据摄入页面右侧,单击更多配置,在引擎版本项中选择目标版本。如果为已部署作业,您需要重新部署并启动作业,以使线上作业更换版本。
JAR或Python作业
在作业运维页面单击目标作业名称,在部署详情页签,单击基本配置区域右上角的编辑,在引擎版本项中选择目标版本,单击保存后单击启动。
如何配置自定义的作业运行参数?
登录实时计算管理控制台。
单击目标工作空间操作列下的控制台。
在作业运维页面,单击目标作业名称。
在部署详情页签,单击运行参数配置区域右侧编辑。
在其他配置项中,配置代码信息。
请确保键值对之间冒号后存在一个空格。代码示例如下。
task.cancellation.timeout: 180s单击保存。
如何持久化Flink常用配置,提升配置效率?
实时计算Flink版提供作业模板功能,您可以将常用的参数设置为默认的,这样再次创建新的作业就无需手动配置了。

如何避免AK或账号密码等信息泄露?
使用变量可以避免明文AccessKey、密码等信息带来的安全风险,通过复用可以避免重复编写相同的代码或值,易于配置管理。支持在SQL作业、JAR或Python作业、日志配置和UI界面等场景中使用。详情请参见变量管理。
如何让Flink作业更合理地利用计算资源?
您可以通过以下方式进行调整:
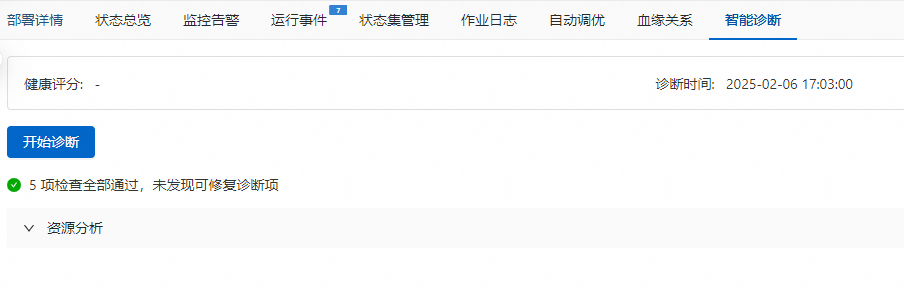
手动调整:在智能诊断页签,单击开始诊断,查看资源分析结论,并根据提示手动进行调整。
自动调整:开启自动调优(包含智能调优和定时调优两种模式)功能让Flink系统自动完成资源调节,具体的适用场景和配置操作,详情请参见配置自动调优。
Cron表达式编写规则
作业状态集管理中采用的是Unix风格规则,而任务编排中采用的是Java风格规则,请根据不同的使用场景,正确使用Cron表达式。
Unix 风格规则
字段定义:
分 时 日 月 周,只有五个字段。“日”与“周”的并集关系:如果同时定义了第3个字段(日)和第5个字段(周),那它们是“或 (OR)” 的关系。
0 12 1 * 5表示“每月的1号 或者 每个周五”的中午12点都会执行,而不是“每月1号且刚好是周五”的情况执行。不支持问号
?:千万不要使用?,系统会报错或无法识别。如果想忽略某个字段,只能用*。
Java风格规则(Quartz)
字段定义:
秒 分 时 日 月 周,常用的为6个字段。“日”与“周”的冲突关系:
“日”和“周”这两个字段不能同时有具体值(或同时为
*)为了避免逻辑冲突(例如:明确指定了“1号”又指定了“周五”,如果1号不是周五怎么办?),这两个字段中必须有一个是
?。规则:填了“日”,周就是
?;填了“周”,日就是?。
周的数字定义不同:1 代表周日,2 代表周一,以此类推。建议使用英文缩写避免歧义:
SUN,MON,TUE。