作为流批一体的计算框架,Flink不仅能够提供低延迟的流式数据处理(Streaming Data Processsing),也能进行高吞吐的批处理(Batch Data Processing)。实时计算Flink版对批处理能力进行了专门的支持,提供了包括作业开发、作业运维、作业编排、资源队列管理、数据结果探查等能力,可以利用Flink批处理能力更好地解决业务需求。本文通过具体的示例为您介绍如何利用实时计算Flink版关键功能进行数据批处理。
功能介绍
实时计算Flink版提供了以下关键功能来支持Flink批处理:
SQL作业开发:在SQL开发页面的作业草稿页签,可以创建批作业草稿,批作业草稿会以批作业的形式被部署和执行。
作业管理:在作业运维页面,可以直接部署JAR或Python类型的批作业。在顶部下拉框中选择批作业,查看已部署的批作业。展开目标批作业,可查看其作业实例列表。通常,一个批作业的不同作业实例具有相同的处理逻辑,但是采用不同的参数,例如处理的数据所属日期。
数据查询:在SQL开发页面的查询脚本页签,可以执行一些DDL或短查询,快速地进行数据管理和数据探查。这些短查询执行在预创建的Flink Session中,通过资源复用,实现低延迟的简单查询。
数据管理:在元数据管理页面,可以创建和查看Catalog,包括其中的数据库和表的信息。您也可以在SQL开发页面的元数据页签进行查看,提高开发效率。
任务编排(公测):在任务编排页面,可以定义工作流,通过可视化的操作方式,编排一系列批作业的执行依赖。工作流会作为一个整体,根据定义好的依赖关系执行包含的批作业。支持通过手动触发或定时调度方式来执行创建好的工作流。
管理资源队列:在队列管理页面,可以对工作空间中的资源进行划分,从而避免流作业和批作业、以及不同优先级的作业间发生资源争抢。
注意事项
已创建Flink工作空间,详情请参见开通实时计算Flink版。
由于本文示例使用Apache Paimon存储数据,仅实时计算引擎VVR 8.0.5及以上版本支持本文示例。
示例场景
本文以一个电子商务平台的业务场景为例,使用Apache Paimon的湖仓格式对数据进行存储。模拟了一个数据仓库结构,包括ODS(操作数据存储)、DWD(数据仓库细节级)、DWS(数据仓库汇总级)的存储层级。通过Flink的批处理能力,对数据进行加工清洗后写入Paimon表,从而实现数据分层结构的搭建。
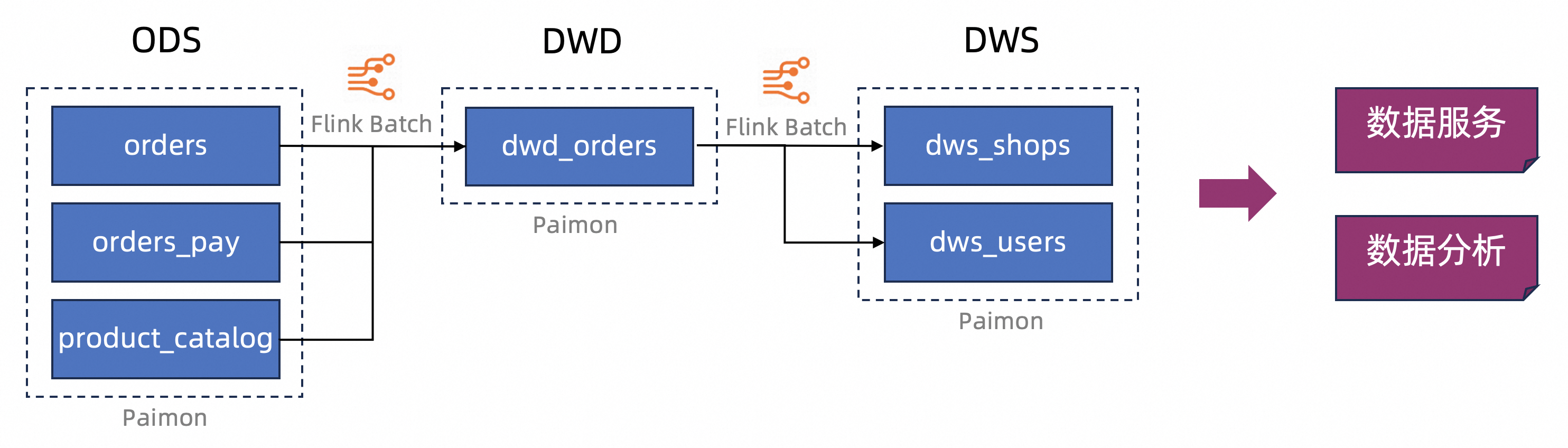
准备工作
创建数据查询。
通过查询脚本页签,您可以创建Catalog以及其中的数据库和表,并且向表中插入一些模拟的数据。
创建Paimon Catalog。
在查询脚本的文本编辑区域,输入如下SQL语句。
CREATE CATALOG `my_catalog` WITH ( 'type' = 'paimon', 'metastore' = 'filesystem', 'warehouse' = '<warehouse>', 'fs.oss.endpoint' = '<fs.oss.endpoint>', 'fs.oss.accessKeyId' = '<fs.oss.accessKeyId>', 'fs.oss.accessKeySecret' = '<fs.oss.accessKeySecret>' );参数配置项如下。
配置项
说明
是否必填
备注
type
Catalog类型。
是
固定值为Paimon。
metastore
元数据存储类型。
是
本文示例填写filesystem,其他类型详情请参见管理Paimon Catalog。
warehouse
OSS服务中所指定的数仓目录。
是
格式为oss://<bucket>/<object>。其中:
bucket:表示您创建的OSS Bucket名称。
object:表示您存放数据的路径。
请在OSS管理控制台上查看您的Bucket和Object名称。
fs.oss.endpoint
OSS服务的连接地址。
否
当warehouse指定的OSS Bucket与Flink工作空间不在同一地域,或使用其它账号下的OSS bucket时需要填写。
请参见OSS地域和访问域名。
fs.oss.accessKeyId
拥有读写OSS权限的阿里云账号或RAM账号的AccessKey。
否
当warehouse指定的OSS Bucket与Flink工作空间不在同一地域,或使用其它账号下的OSS Bucket时需要填写。获取方法请参见创建AccessKey。
fs.oss.accessKeySecret
拥有读写OSS权限的阿里云账号或RAM账号的AccessKey Secret。
否
选中上述代码,单击左侧的运行。
返回
The following statement has been executed successfully!信息表示Catalog创建成功。此时可以在元数据管理页面(或是SQL开发页面的元数据子页面),查看新创建的Catalog。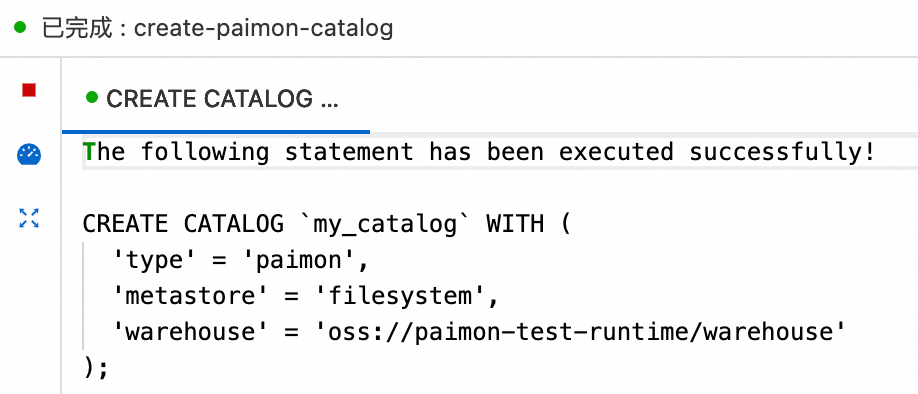
操作流程
步骤一:创建ODS表并插入测试数据
为了简化本示例,我们直接向ODS表中插入了一些测试数据,用于后续的DWD/DWS表的数据生成。在实际生产中,一般会使用Flink流处理从外部数据源读取数据并写入到湖中作为ODS层,具体可以参见 Paimon快速开始:基本功能。
在查询脚本文本编辑区域,输入如下SQL语句并单击左侧的运行。
CREATE DATABASE `my_catalog`.`order_dw`; USE `my_catalog`.`order_dw`; CREATE TABLE orders ( order_id BIGINT, user_id STRING, shop_id BIGINT, product_id BIGINT, buy_fee BIGINT, create_time TIMESTAMP, update_time TIMESTAMP, state INT ); CREATE TABLE orders_pay ( pay_id BIGINT, order_id BIGINT, pay_platform INT, create_time TIMESTAMP ); CREATE TABLE product_catalog ( product_id BIGINT, catalog_name STRING ); -- 插入测试数据 INSERT INTO orders VALUES (100001, 'user_001', 12345, 1, 5000, TO_TIMESTAMP('2023-02-15 16:40:56'), TO_TIMESTAMP('2023-02-15 18:42:56'), 1), (100002, 'user_002', 12346, 2, 4000, TO_TIMESTAMP('2023-02-15 15:40:56'), TO_TIMESTAMP('2023-02-15 18:42:56'), 1), (100003, 'user_003', 12347, 3, 3000, TO_TIMESTAMP('2023-02-15 14:40:56'), TO_TIMESTAMP('2023-02-15 18:42:56'), 1), (100004, 'user_001', 12347, 4, 2000, TO_TIMESTAMP('2023-02-15 13:40:56'), TO_TIMESTAMP('2023-02-15 18:42:56'), 1), (100005, 'user_002', 12348, 5, 1000, TO_TIMESTAMP('2023-02-15 12:40:56'), TO_TIMESTAMP('2023-02-15 18:42:56'), 1), (100006, 'user_001', 12348, 1, 1000, TO_TIMESTAMP('2023-02-15 11:40:56'), TO_TIMESTAMP('2023-02-15 18:42:56'), 1), (100007, 'user_003', 12347, 4, 2000, TO_TIMESTAMP('2023-02-15 10:40:56'), TO_TIMESTAMP('2023-02-15 18:42:56'), 1); INSERT INTO orders_pay VALUES (2001, 100001, 1, TO_TIMESTAMP('2023-02-15 17:40:56')), (2002, 100002, 1, TO_TIMESTAMP('2023-02-15 17:40:56')), (2003, 100003, 0, TO_TIMESTAMP('2023-02-15 17:40:56')), (2004, 100004, 0, TO_TIMESTAMP('2023-02-15 17:40:56')), (2005, 100005, 0, TO_TIMESTAMP('2023-02-15 18:40:56')), (2006, 100006, 0, TO_TIMESTAMP('2023-02-15 18:40:56')), (2007, 100007, 0, TO_TIMESTAMP('2023-02-15 18:40:56')); INSERT INTO product_catalog VALUES (1, 'phone_aaa'), (2, 'phone_bbb'), (3, 'phone_ccc'), (4, 'phone_ddd'), (5, 'phone_eee');说明本文创建的是不带主键的Paimon Append Only表,其相比于Paimon主键表具有更好的批量写入性能,但不支持基于主键的更新操作。
执行结果会包含多个子标签页,返回
The following statement has been executed successfully!信息表示对应的DDL语句执行成功。INSERT等DML语句则会返回一个JobId,表明生成了Flink作业并在Flink Session中执行,单击结果栏左侧的在Flink UI中查看,可观察到这几条SQL语句的执行情况,等待数秒至其执行完成。
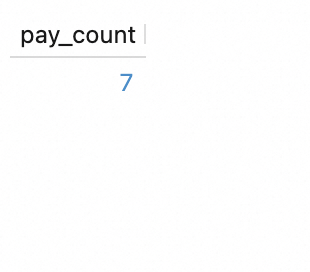
探查ODS表数据。
在查询脚本文本编辑区域,输入如下SQL语句并单击左侧的运行。
SELECT count(*) as order_count FROM `my_catalog`.`order_dw`.`orders`; SELECT count(*) as pay_count FROM `my_catalog`.`order_dw`.`orders_pay`; SELECT * FROM `my_catalog`.`order_dw`.`product_catalog`;这些SQL语句也会在Flink Session中执行,最终可以在3个查询的结果页面中查看返回结果。


步骤二:创建DWD和DWS表
在查询脚本文本编辑区域,输入如下SQL语句并单击左侧的运行。
USE `my_catalog`.`order_dw`;
CREATE TABLE dwd_orders (
order_id BIGINT,
order_user_id STRING,
order_shop_id BIGINT,
order_product_id BIGINT,
order_product_catalog_name STRING,
order_fee BIGINT,
order_create_time TIMESTAMP,
order_update_time TIMESTAMP,
order_state INT,
pay_id BIGINT,
pay_platform INT COMMENT 'platform 0: phone, 1: pc',
pay_create_time TIMESTAMP
) WITH (
'sink.parallelism' = '2'
);
CREATE TABLE dws_users (
user_id STRING,
ds STRING,
total_fee BIGINT COMMENT '当日完成支付的总金额'
) WITH (
'sink.parallelism' = '2'
);
CREATE TABLE dws_shops (
shop_id BIGINT,
ds STRING,
total_fee BIGINT COMMENT '当日完成支付总金额'
) WITH (
'sink.parallelism' = '2'
);此处创建的仍然是Paimon Append Only表。Paimon表作为Flink Sink不支持自动并发推导,需要显式设置其并发度,否则可能会报错。
步骤三:创建与部署DWD和DWS作业
创建和部署DWD作业。
创建DWD表更新作业。
在页面新建空白的批作业草稿,命名为dwd_orders,建议选择带有推荐标签的引擎版本,SQL方言使用默认的Flink SQL,将如下SQL语句复制到文本编辑区域中。由于DWD表是Paimon Append Only表,因此此处使用INSERT OVERWRITE语句进行整体的覆写。
INSERT OVERWRITE my_catalog.order_dw.dwd_orders SELECT o.order_id, o.user_id, o.shop_id, o.product_id, c.catalog_name, o.buy_fee, o.create_time, o.update_time, o.state, p.pay_id, p.pay_platform, p.create_time FROM my_catalog.order_dw.orders as o, my_catalog.order_dw.product_catalog as c, my_catalog.order_dw.orders_pay as p WHERE o.product_id = c.product_id AND o.order_id = p.order_id单击页面右上方的部署,单击确定,部署dwd_orders作业。
创建和部署DWS作业。
创建DWS表更新作业。
参考创建DWD表更新作业,创建批作业草稿dws_shops和dws_users,将下列SQL语句分别复制到对应草稿的文本编辑区域中。
INSERT OVERWRITE my_catalog.order_dw.dws_shops SELECT order_shop_id, DATE_FORMAT(pay_create_time, 'yyyyMMdd') as ds, SUM(order_fee) as total_fee FROM my_catalog.order_dw.dwd_orders WHERE pay_id IS NOT NULL AND order_fee IS NOT NULL GROUP BY order_shop_id, DATE_FORMAT(pay_create_time, 'yyyyMMdd');INSERT OVERWRITE my_catalog.order_dw.dws_users SELECT order_user_id, DATE_FORMAT(pay_create_time, 'yyyyMMdd') as ds, SUM(order_fee) as total_fee FROM my_catalog.order_dw.dwd_orders WHERE pay_id IS NOT NULL AND order_fee IS NOT NULL GROUP BY order_user_id, DATE_FORMAT(pay_create_time, 'yyyyMMdd');单击页面右上方的部署,单击确定,部署dws_shops和dws_users作业。
步骤四:启动与查看DWD和DWS作业
启动与查看DWD作业数据。
在页面,在下拉框中选择批作业,单击dwd_orders作业操作列下的启动。
对应批作业实例列表中,生成了一个启动中的批作业实例,如下图所示。

当该作业实例的状态变为已完成时,表示数据处理完毕。
探查数据结果。
在查询脚本文本编辑区域,输入如下SQL语句并单击左侧的运行,查询DWD表的数据。
SELECT * FROM `my_catalog`.`order_dw`.`dwd_orders`;结果如下所示。

启动与查看DWS作业数据。
在页面,在下拉框中选择批作业,单击dws_shops和dws_users作业操作列下的启动。
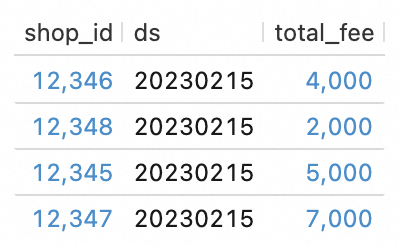
在查询脚本文本编辑区域,输入如下SQL语句并单击左侧的运行,查询DWS表的数据。
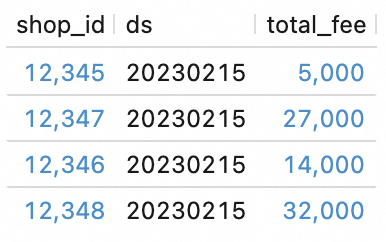
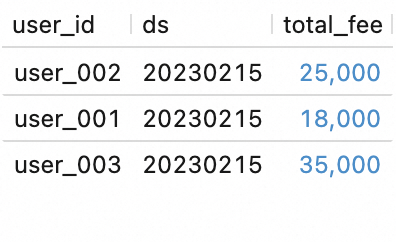
SELECT * FROM `my_catalog`.`order_dw`.`dws_shops`; SELECT * FROM `my_catalog`.`order_dw`.`dws_users`;结果如下所示。
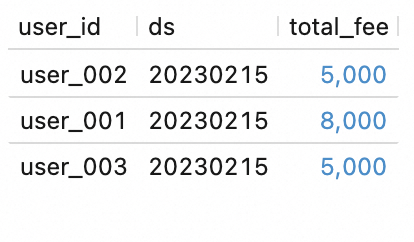
步骤五:通过作业编排构建批处理链路
本部分将把前面创建的作业编排成一个工作流,使得它们可以被统一的触发并有序的执行。
创建工作流。
单击左侧的,单击创建工作流。
在弹出的面板中,填入名称wf_orders,调度类型保持不变(默认为手动触发),资源队列选择default-queue后,单击创建,进入工作流编辑页面。
编辑工作流。
单击初始的节点,命名为v_dwd_orders,选取其作业为dwd_orders。
单击添加节点,创建节点v_dws_shops,选取其作业为dws_shops,上游节点为v_dwd_orders。
再次单击添加节点,创建节点v_dws_users,选取其作业为dws_users,上游节点为v_dwd_orders。
单击右上角的保存并确定。
创建的工作流如下所示。
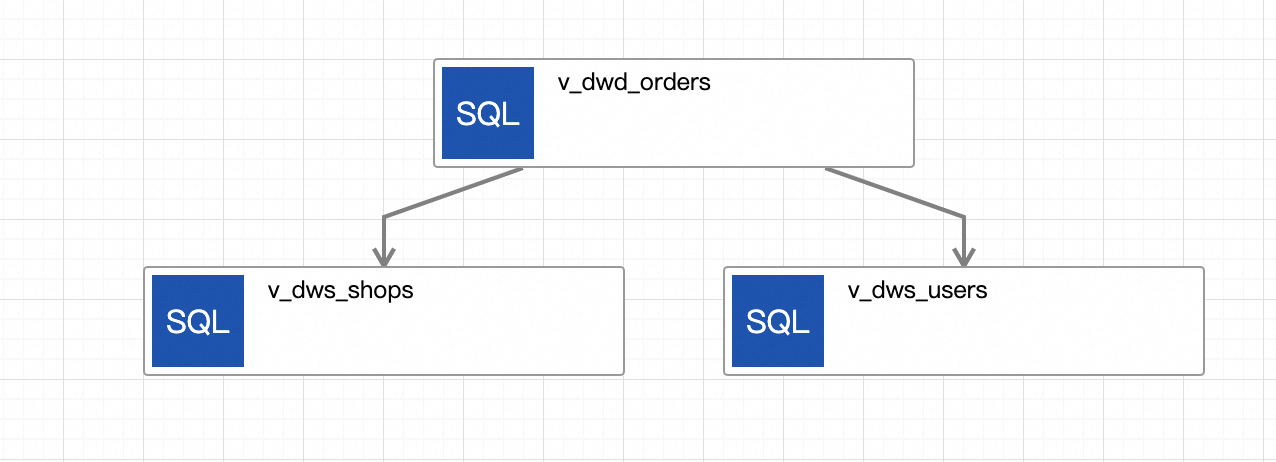
手动触发工作流运行
说明工作流也可以被修改为定时调度的工作流,只需要在任务编排页面,单击工作流右侧的编辑工作流,将调度模式修改为周期调度即可,详情请参见任务编排(公测)。
在触发工作流运行前,先给ODS表插入一些新数据,用于验证工作流的执行结果。
在查询脚本文本编辑区域,输入如下SQL语句并单击左侧的运行。
USE `my_catalog`.`order_dw`; INSERT INTO orders VALUES (100008, 'user_001', 12346, 1, 10000, TO_TIMESTAMP('2023-02-15 17:40:56'), TO_TIMESTAMP('2023-02-15 18:42:56'), 1), (100009, 'user_002', 12347, 2, 20000, TO_TIMESTAMP('2023-02-15 18:40:56'), TO_TIMESTAMP('2023-02-15 18:42:56'), 1), (100010, 'user_003', 12348, 3, 30000, TO_TIMESTAMP('2023-02-15 19:40:56'), TO_TIMESTAMP('2023-02-15 18:42:56'), 1); INSERT INTO orders_pay VALUES (2008, 100008, 1, TO_TIMESTAMP('2023-02-15 20:40:56')), (2009, 100009, 1, TO_TIMESTAMP('2023-02-15 20:40:56')), (2010, 100010, 1, TO_TIMESTAMP('2023-02-15 20:40:56'));单击结果栏左侧的在Flink UI,观察作业状态。
在页面,单击上一部分创建的工作流操作列下的触发运行,单击确定,触发工作流运行。

单击工作流名称,进入工作流实例列表与详情页面,可以看到工作流实例列表。
单击运行中的工作流实例运行ID,即可进入工作流实例的执行详情页面,观察到各个节点的执行状态。等待整个工作流执行完成。
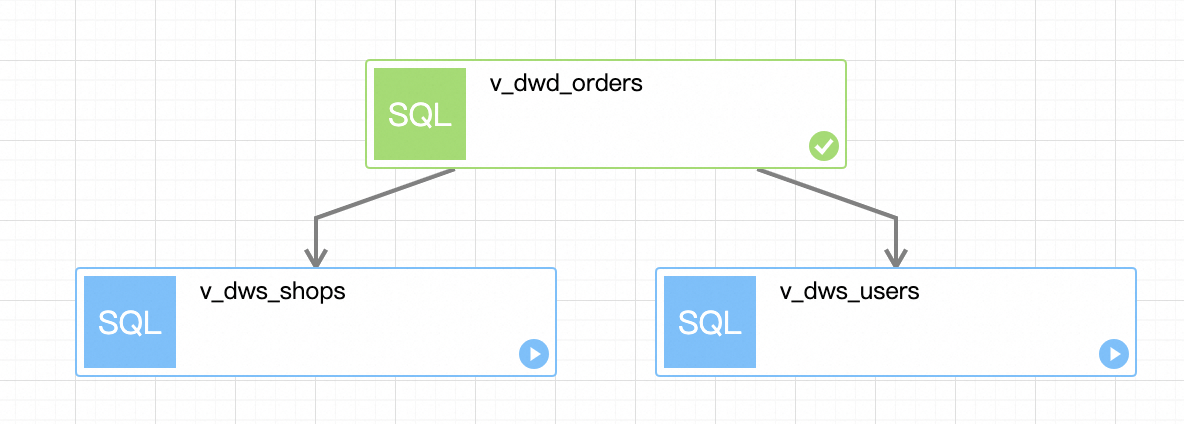
查看工作流执行结果
在查询脚本文本编辑区域,输入如下SQL语句并单击左侧的运行。
SELECT * FROM `my_catalog`.`order_dw`.`dws_shops`; SELECT * FROM `my_catalog`.`order_dw`.`dws_users`;查看工作流的执行结果。
可以看到,ODS层新增数据经过处理已经写入DWS表中。
相关文档
如果您想要对Flink批处理的原理和配置调优有更多了解,请参见 Flink批处理调优指南
如果您想要使用Flink+Paimon搭建实时数仓,操作步骤详情请参见基于Flink搭建流式湖仓OpenLake方案。
除了在实时计算开发控制台进行Flink作业开发等操作,您同样可以在本地进行,具体操作请参见VS Code本地开发插件。