Trino(即原PrestoSQL)是一个开源的分布式SQL查询引擎,适用于交互式分析查询。EMR-3.44.0和EMR-5.10.0版本开始改用社区正式名称Trino,之前各版本控制台显示为Presto,内核其实是Trino,使用时请注意区分。
基本特性
Trino使用Java语言进行开发,具备易用、高性能和强扩展能力等特点,具体如下:
完全支持ANSI SQL。
支持丰富的数据源:
Hive
Cassandra
Kafka
MongoDB
MySQL
PostgreSQL
SQL Server
Redis
Redshift
本地文件
支持高级数据结构,具体如下:
数组和Map数据
JSON数据
GIS数据
颜色数据
功能扩展能力强,提供了多种扩展机制:
扩展数据连接器
自定义数据类型
自定义SQL函数
流水线:基于Pipeline处理模型数据在处理过程中实时返回给用户。
监控接口完善:
提供友好的Web UI,可视化的呈现查询任务执行过程。
支持JMX协议。
系统组成
Trino的系统组成如下图所示。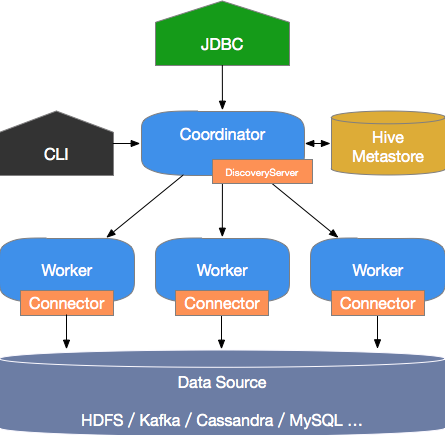
Trino是典型的M/S架构的系统,由一个Coordinator节点和多个Worker节点组成。 Coordinator负责如下工作:
接收用户查询请求,解析并生成执行计划,下发Worker节点执行。
监控Worker节点运行状态,各个Worker节点与Coordinator节点保持心跳连接,汇报节点状态。
维护MetaStore数据。
Worker节点负责执行下发到任务,通过连接器读取外部存储系统到数据,进行处理,并将处理结果发送给Coordinator节点。
应用场景
Trino是定位在数据仓库和数据分析业务的分布式SQL引擎,适合以下应用场景:
ETL
Ad-Hoc查询
海量结构化数据或半结构化数据分析
海量多维数据聚合或报表分析
Trino是一个数仓类产品,因为其对事务支持有限,所以不适合在线业务场景。
产品优势
E-MapReduce(简称EMR)中的Trino与开源Trino比较,还具备如下优势:
即买即用,快速完成上百节点的Trino集群搭建。
弹性扩容简单操作。
与EMR软件栈完美结合,支持处理存储在OSS的数据。
无需运维,EMR提供一站式服务。
基本概念
数据模型
数据模型即数据的组织形式。Trino使用Catalog、Schema和Table三层结构来管理数据。
Catalog
一个Catalog可以包含多个Schema,物理上指向一个外部数据源,可以通过Connector访问该数据源。一次查询可以访问一个或多个Catalog。
Schema
相当于一个数据库实例,一个Schema包含多张数据表。
Table
数据表,与一般意义上的数据库表相同。
Connector
Trino通过各种Connector来接入多种外部数据源。Trino提供了一套标准的SPI接口,用户可以使用这套接口开发自己的Connector,以便访问自定义的数据源。
一个Catalog通常会绑定一种类型的Connector,在Catalog的Properties文件中设置。Trino内置了多种Connector。
更多参考
请根据Trino组件的版本号,修改http://trino.io/docs/3XX/中的版本号,在浏览器访问该链接,查看开源Trino文档。
例如,当Trino版本是331时,访问https://trino.io/docs/331/,详情请参见Trino 331 Documentation。