您可以在自定义配置页签上调整探针功能开关、采样策略等常用设置。
如果您需要使用API方式调整,请参见SaveTraceAppConfig。
前提条件
已为应用安装探针,具体操作,请参见应用监控接入概述。
功能入口
登录ARMS控制台,在左侧导航栏选择。
在应用列表页面顶部选择目标地域,然后单击目标应用名称。
说明语言列的图标含义如下:
 :接入应用监控的Java应用。
:接入应用监控的Java应用。 :接入应用监控的Golang应用。
:接入应用监控的Golang应用。 :接入应用监控的Python应用。
:接入应用监控的Python应用。-:接入可观测链路 OpenTelemetry 版的应用。
在左侧导航栏中单击应用设置,并在右侧页面单击自定义配置页签。
设置自定义配置参数,设置完毕后,在页面底部单击保存。
采样率设置
ARMS专家版
在采样率设置区域,可以为调用链设置采样策略和采样接口名称。更多详细信息,请参见调用链采样模式选择(3.2.8以下探针版本)。
调用链采样率优先级高于限流阈值。

ARMS基础版
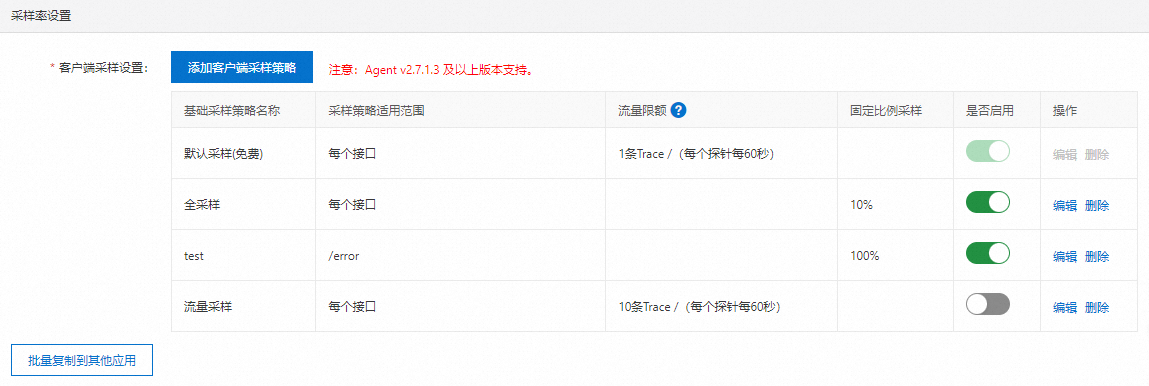
ARMS基础版支持设置客户端采样策略,并按照采集数据行数进行计费。ARMS默认免费为您账号下所有接口的每个探针每分钟采集一条调用链。除此之外,您还可以单击添加客户端采样策略,添加自定义的采样策略。
设置项 | 说明 |
策略名称 | 自定义采样策略名称。 |
采样类型和采样值 |
|
适用接口 | 设置采样策略生效的接口范围,可选择每个接口或指定接口并输入指定的接口名称。 说明 目前每个采样策略在选择指定接口时,仅支持输入一个接口名。若需对多个接口进行调用链采样,则需设置多个采样策略。 |
完成采样策略设置后,您可以在控制台选择是否开启该策略。多个采样策略会同时生效,但存在优先级如下:默认采样(免费)> 单接口流量限额 > 单接口固定比例采样 > 全部接口流量限额 > 全部接口固定比例采样。您也可以编辑已添加的采样策略,或删除不需要的采样策略。
Agent(探针)开关和日志级别
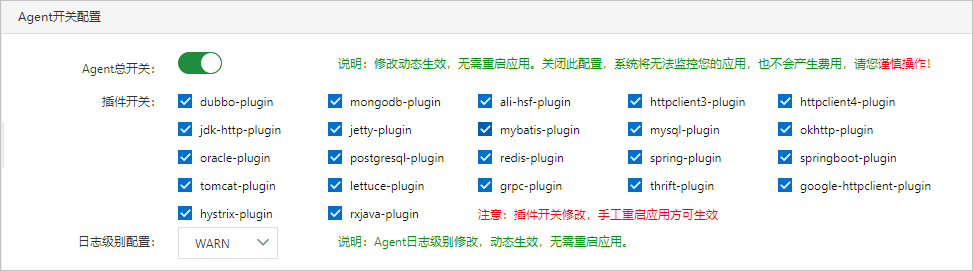
在Agent开关配置区域,可以打开或关闭探针总开关以及各插件开关,并配置日志级别。
探针总开关和日志级别的修改即时生效,无需重启应用。如果关闭探针总开关,则系统将无法监控您的应用,请谨慎操作。要使对各插件开关的修改生效,必须手动重启应用。
阈值设置
在阈值设置区域,可以设置慢SQL查询阈值。

消息队列配置
在消息队列配置区域,可以设置消息相关参数。
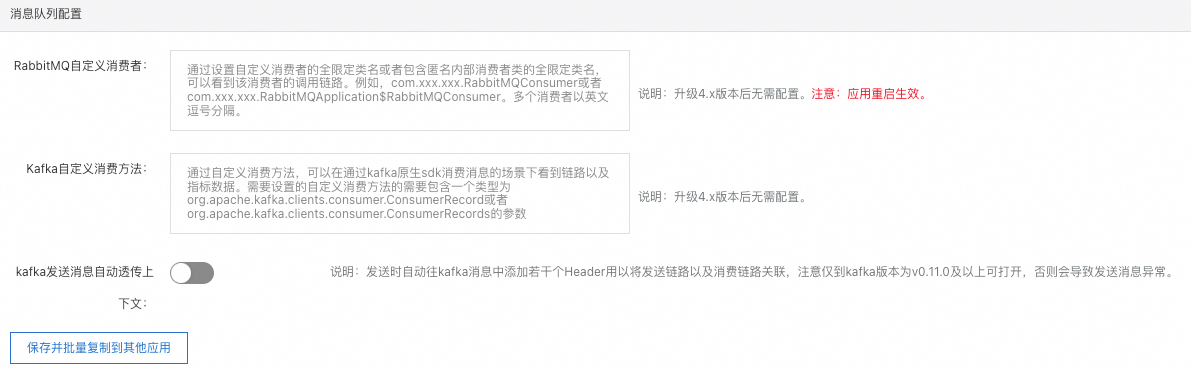
自定义RabbitMQ消费者:通过设置自定义消费者的类名或者包含匿名内部消费者的类名,可以看到该消费者的调用链路。多个消费者以英文半角逗号(,)分隔。
自定义Kafka消费方法:通过自定义消费方法,可以在通过Kafka原生SDK消费消息的场景下看到链路以及指标数据。
Kafka发送消息自动透传上下文:发送时自动往Kafka消息中添加若干个Header用于关联发送链路和消费链路。
探针采集配置
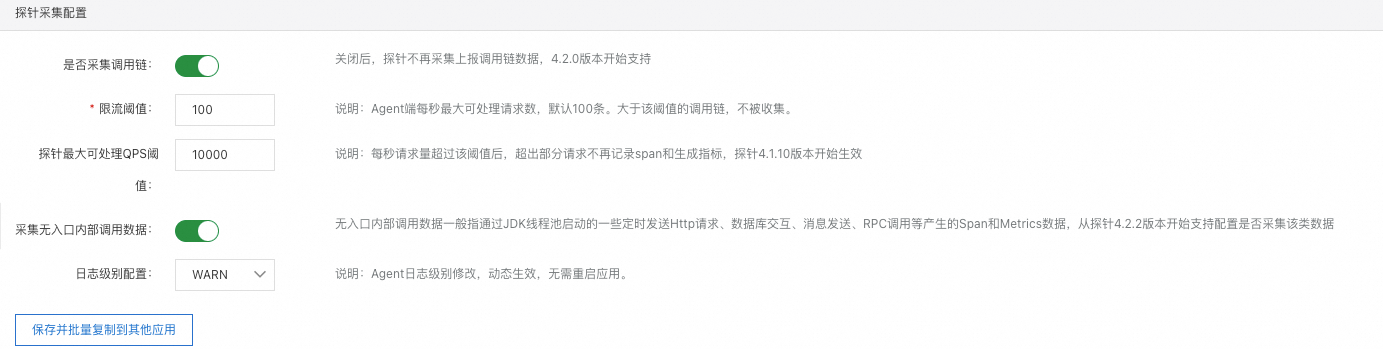
是否采集调用链:控制调用链数据是否上报,默认开启,关闭后,调用链数据不再上报。
限流阈值:探针每秒最大可处理请求数,默认100条。大于该阈值的调用链,不被收集。
说明调用链采样率优先级高于限流阈值。
探针最大可处理QPS阈值:探针每秒可处理的请求数量(出于性能考虑,实际生效阈值和用户配置阈值有5%以内偏差),超出该阈值的请求不会被监控,即不会对超出阈值的请求生成Span或者记录指标,日志关联TraceId功能也不会生效。
采集无入口内部调用数据:无入口内部调用数据一般指通过JDK线程池启动的一些定时发送HTTP请求、数据库交互、消息发送、RPC调用等产生的Span和Metrics数据。
日志级别配置:调整探针日志的打印级别,用于问题排查。
接口调用配置
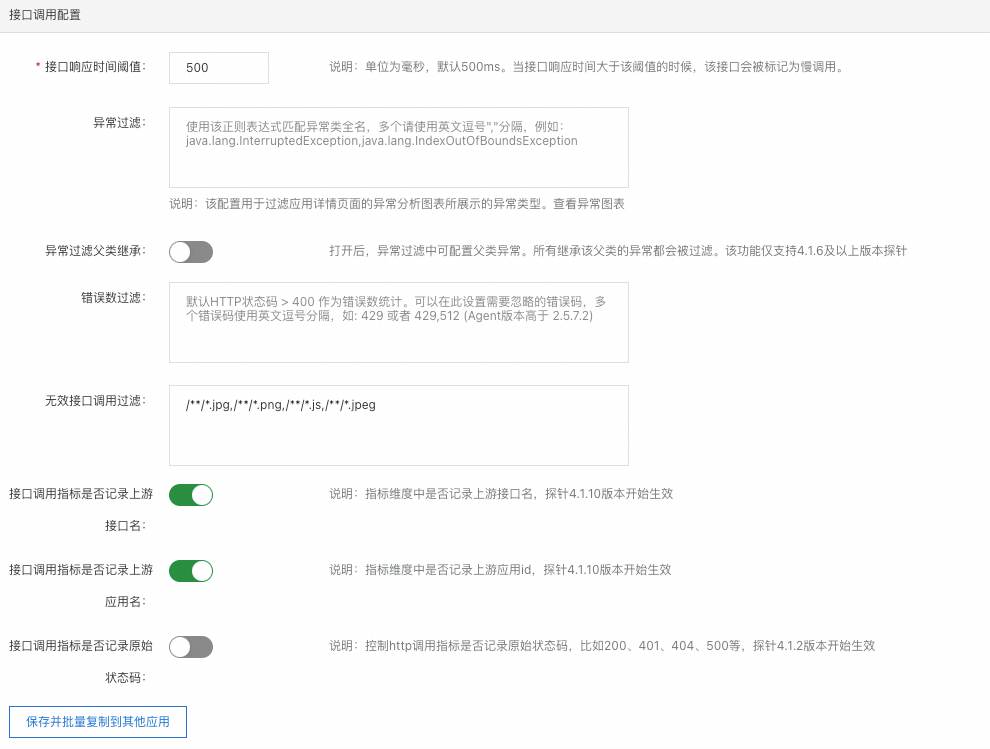
接口响应时间阈值:当接口响应时间大于该阈值的时候,该接口会被标记为慢调用。
异常过滤:此处输入的异常不会显示在应用详情和异常分析页面的图表中。
异常过滤父类继承:开启后,如果当前采集到异常是异常过滤白名单中配置的异常类的子类,则也会被过滤。
配置效果:满足过滤条件的异常将不会展示在ARMS控制台。
错误数过滤:默认情况下,大于400的状态码会计入错误数,您可以自定义大于400但不计入的HTTP状态码。
无效接口调用过滤:输入不需要查看调用情况的接口,探针将不会上报相关接口产生的观测数据,从而将其从接口调用页面隐去。
接口调用指标是否记录上游接口名和接口调用指标是否记录上游应用名:
控制接口指标中是否记录调用该接口的上游应用和上游接口,主要影响提供服务中的链路上下游是否有数据。当应用的上游应用较多时,记录该信息可能导致指标上报量剧增,增加费用。
接口调用指标是否记录原始状态码:在HTTP接口相关指标中记录原始的响应码。
池化监控配置
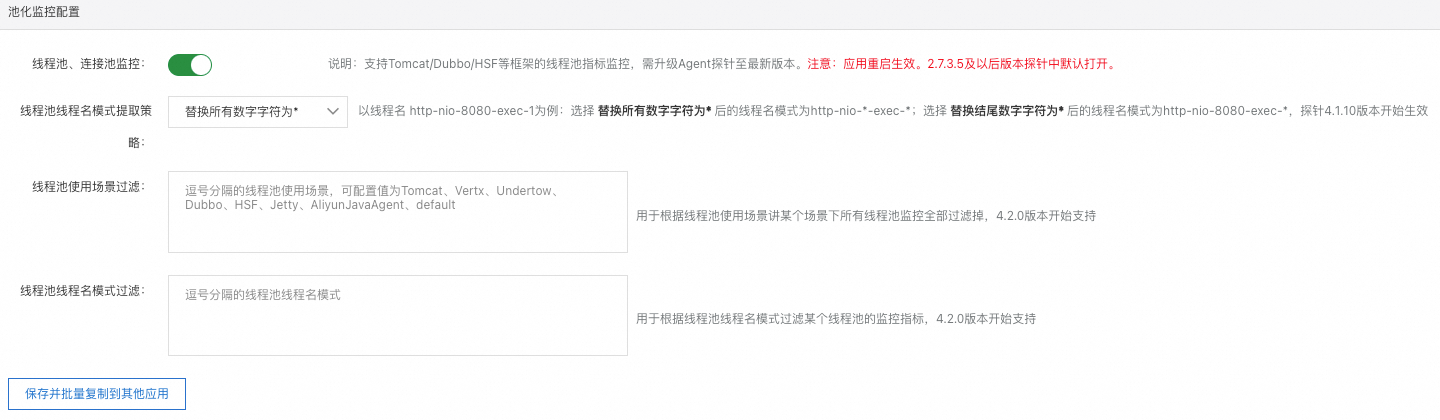
线程池、连接池监控:支持Tomcat/Dubbo/HSF等框架的线程池指标监控,需升级探针至最新版本。
线程池线程名模式提取策略:该功能默认将线程池中任意一个运行线程的线程名中所有数字字符替换为
*,您也可以调整为仅将线程名的结尾字符替换为*。一般在应用中启动了多个Dubbo Provider,且不同Dubbo Provider的监听端口不一致的情况下,如果按照默认策略,则两个Dubbo Provider中的两个线程池因为提取出来的线程名模板相同会被聚合成一个,此时可以通过调整该策略来区分为两个线程池。线程池使用场景过滤和线程池线程名模式过滤:按照线程池使用场景和线程池线程名模式过滤不上报某些线程池的监控指标。
说明该配置仅对 4.2.0 及以上版本的Java探针生效。
线程池使用场景:指该线程使用的场景,目前支持Tomcat、Vert.x、Undertow、Dubbo、Jetty、AliyunJavaAgent、default几种,其中AliyunJavaAgent代表探针使用的线程池,default代表未归类的其他线程池。
线程池线程名模式:指该线程池中线程名经过处理得到的线程名模式,例如http-nio-*-exec-*一般是将实际线程中数字部分替换为*后得到线程名。
Span Attributes配置
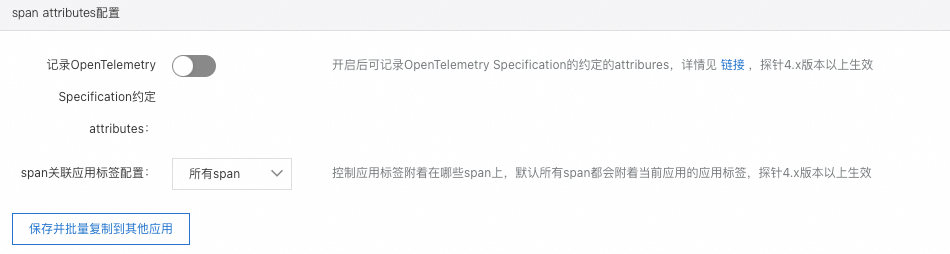
记录OpenTelemetry Specification约定attributes:OpenTelemetry Specification中为每一种插件类型约定了其生成Span所应当包含的Attributes项,但ARMS探针出于数据上报量考虑,默认情况下在Span中并不会记录这些Attributes,您可以按照自身需求开启,开启后,各框架会增加的Attributes请参见OpenTelemetry Specification。
Span关联应用标签配置:用于控制当前在控制台应用列表页面为应用绑定的标签会被附在哪些Span上,默认情况下,所有Span都会包含应用标签。出于用量考虑,您可以将应用标签仅附在入口Span上(入口Span一般包括HTTP Server、RPC Server、MQ消费消息、定时任务)。
高级设置

方法堆栈最大长度:默认为128条,最大值为400条。
同类异常堆栈区分深度:同类型异常,用于作为不同异常区分的堆栈深度,一般设置为第一个差异调用的深度。
采集SQL最大长度:默认为1024个字符,最小值为256,最大值为4096。
采集SQL绑定值:捕获PrepareStatement参数绑定的变量值,无需重启应用即可生效,当前仅支持向PrepareStatement中设置SQL变量值的场景。
原始SQL:仅对SQL截断,不做额外处理。
是否记录MySQL查询返回值大小:开启后ARMS将会记录MySQL查询返回值大小。
调用链新格式:采用支持调用链时间排序的新存储格式(默认开启)。
调用链压缩:是否将重复调用(比如for循环)简化,无需重启应用即可生效。
请求入参最大长度:默认为512字符,支持的最大长度为2048字符。
分位数统计:是否开启分位数统计功能。
说明分位数:指将一个随机变量的概率分布范围分为几个等分的数值点,常用的有中位数(即二分位数)、四分位数、百分位数等。
自动透传异步:当通过线程池提交异步任务时,自动透传异步上下文。
异步透传扫描包名:添加异步透传扫描包实现异步任务监控。异步透传扫描包中的Runnable、Callable和Supplier接口在创建新对象时会自动捕获当前线程调用链的上下文,并在异步线程中执行时使用该调用链上下文,完成串联。探针版本必须为v2.7.1.3及以上。
请求中返回TraceId:仅针对HTTP类型的请求,在Response Header中返回字段为
eagleeye-traceid。
线程设置
在线程设置区域,可以打开或关闭线程分析总控开关。
仅应用监控专家版支持该功能。

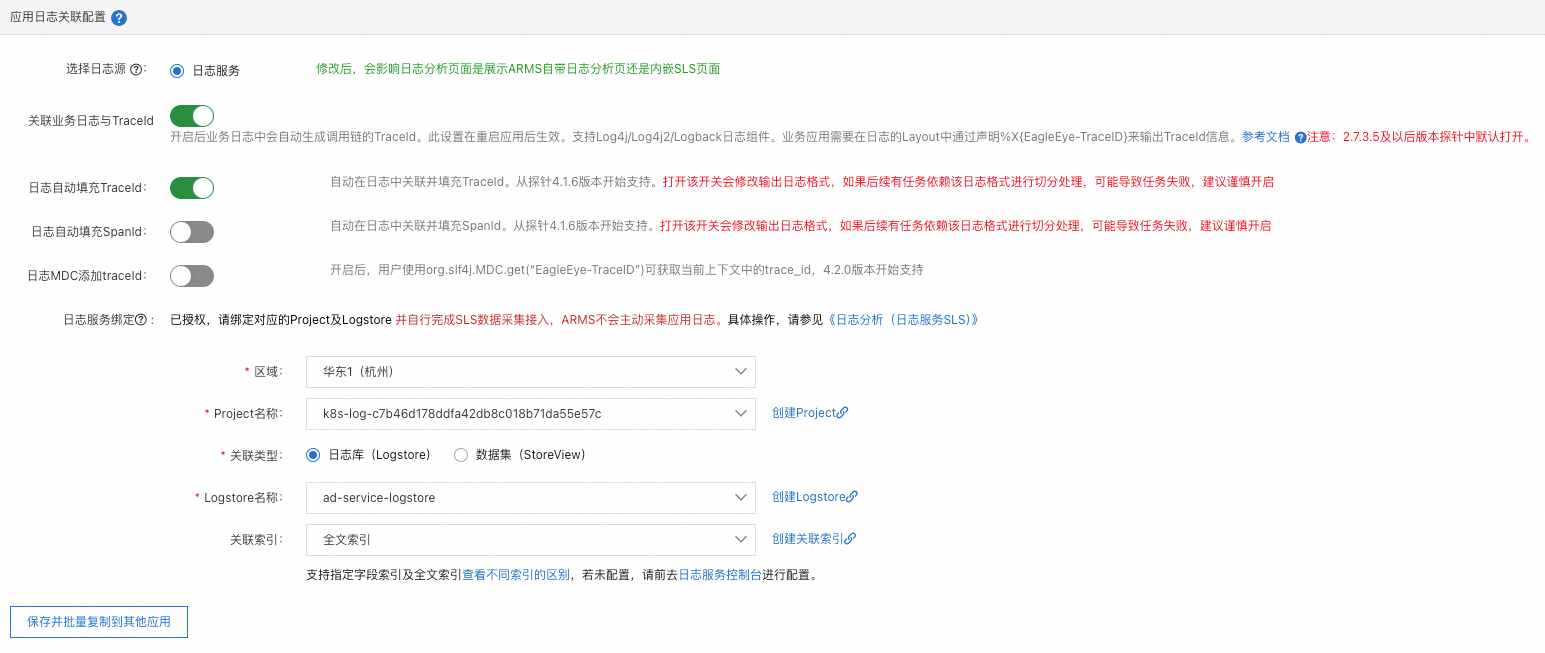
应用日志关联配置
在应用日志关联配置区域,可以设置应用关联的日志源信息。更多信息,请参见日志分析。
仅应用监控专家版支持该功能。
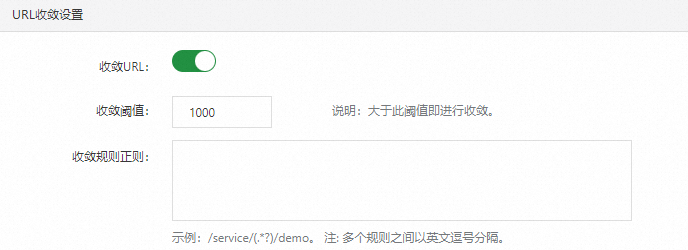
URL收敛规则
在URL收敛设置区域,可以打开或关闭收敛功能的开关,并设置收敛阈值、收敛规则。URL收敛是指将具有相似性的一系列URL作为一个单独的个体展示,例如将前半部分都为/service/demo/的一系列URL集中展示。收敛阈值是指要进行URL收敛的最低数量条件,例如当阈值为100时,则符合规则正则表达式的URL达到100时才会对它们进行收敛。
设置Arthas监控
在Arthas监控区域,可以打开或关闭Arthas诊断功能,并设置生效IP。更多信息,请参见Arthas诊断。
仅应用监控专家版支持该功能。

持续剖析
在持续剖析区域,可以打开或关闭总开关、CPU热点、内存热点、代码热点功能,并设置生效IP或网段。更多信息,请参见接入持续剖析功能。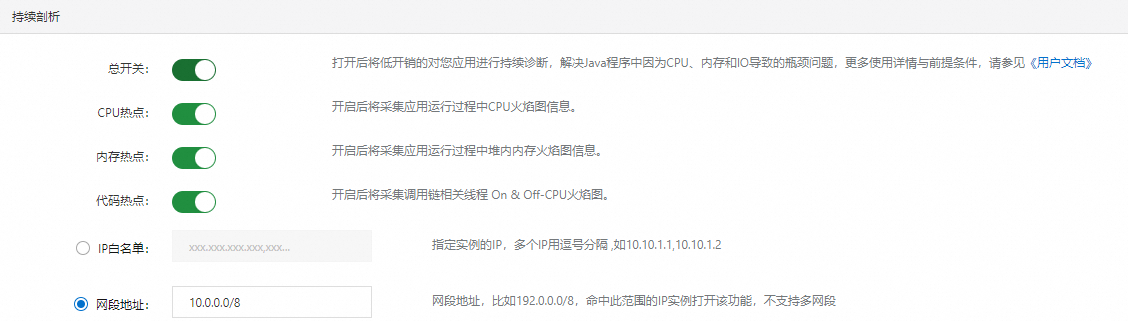
调用链透传协议设置
在调用链透传协议设置区域,您可以根据自己的需求选择使用的Trace协议,ARMS支持的Trace协议请参见ARMS支持的Trace上下文传播协议。

默认情况下,当一次调用到来时,ARMS探针会按照EagleEye、OpenTelemetry、SkyWalking、Jaeger、Zipkin的顺序依次探测是否存在该协议约定的请求头,如果探测到某个协议存在,则按照该协议约定恢复Trace上下文,后续调用下游时,也按照该协议约定往请求中塞入相关Header。当上述检测都失败时,默认使用EagleEye协议。
您可以在该页面选择任一协议作为优先协议。选择并保存后,ARMS会优先探测是否存在该协议约定的请求头。例如,按照如下配置,当一次调用到来时,ARMS探针将会改为按照Jaeger、EagleEye、OpenTelemetry、SkyWalking、Zipkin的顺序依次探测是否存在协议约定上下文。

您也可以选择强制使用某一种协议。例如,按照如下配置,当一次调用到来时,ARMS探针只会探测是否存在Jaeger协议约定的请求头,如果不存在,不会依次检测其他协议,而是重新生成新的Trace上下文。

信息脱敏
在信息脱敏区域,通过设置脱敏规则,探针将对JVM系统参数、K8s Yaml、方法入参、Arthas环境变量和系统变量等内容在采集时就进行脱敏处理。脱敏规则中各元素通过英文半角逗号分隔,每一个元素代表一个不区分大小写的正则表达式,以password为例,脱敏规则等同于正则表达式.*password.*。
探针在采集数据时会对数据的key按照对应的表达式进行过滤,如果满足条件,该key会被认为包含敏感数据进行脱敏处理。如下图所示,当脱敏规则为licenseKey时,其对-Darms.licenseKey为key的信息进行了脱敏处理。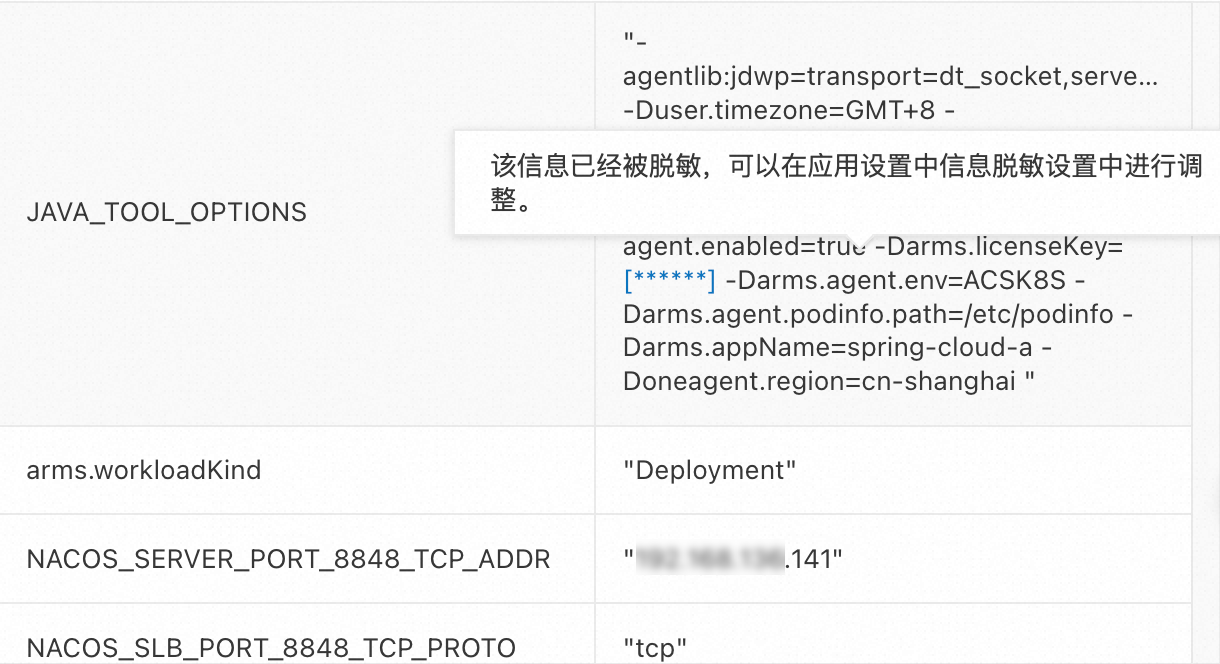
将配置复制到其他应用
如果您需要为其他应用同步相同配置,可以将对应配置复制到其他应用上。
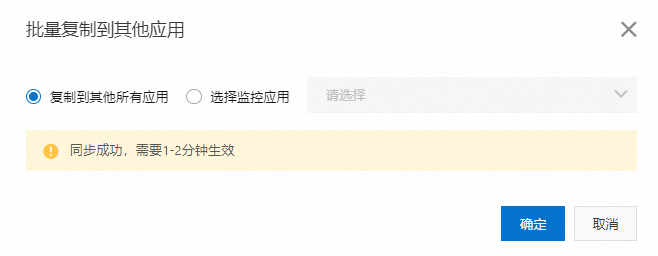
将单个配置复制到其他应用
在对应配置区域单击批量复制到其他应用。
在弹出的对话框中选择生效的应用,然后单击确定。
将所有配置复制到其他应用
在页面底部单击批量复制到其他应用。
在弹出的对话框中选择生效的应用,然后单击确定。
全局默认配置
您可以将当前配置保存为全局默认配置,在之后创建新应用时将会默认使用当前配置。
在页面底部单击保存当前应用设置为全局默认配置。
在弹出的对话框中单击确认。