本文将介绍如何使用数据管理DMS任务编排(老)调度Spark MLLib任务。
前提条件
背景信息
近年来,随着大数据的兴起与算力的提升,机器学习和深度学习得到了广泛的应用,如千人千面的推荐系统、人脸支付、自动驾驶汽车等。MLlib是Spark的机器学习库,包括分类、回归、聚类、协同过滤、降维等算法,本文介绍的是Kmeans聚类算法。
创建Spark虚拟集群
创建虚拟集群,详情请参见创建虚拟集群。
授予ADB删除OSS文件的权限。
上传数据和代码
- 登录OSS管理控制台。
本示例将准备如下数据,并保存至data.txt文件。
0.0 0.0 0.0 0.1 0.1 0.1 0.2 0.2 0.2 9.0 9.0 9.0 9.1 9.1 9.1 9.2 9.2 9.2准备如下spark MLLib代码,并将该代码打包成FatJar文件。
说明示例代码功能:读取data.txt文件中的数据,训练Kmeans模型。
package com.aliyun.spark import org.apache.spark.SparkConf import org.apache.spark.mllib.clustering.KMeans import org.apache.spark.mllib.linalg.Vectors import org.apache.spark.sql.SparkSession object SparkMLlib { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("Spark MLlib Kmeans Demo") val spark = SparkSession .builder() .config(conf) .getOrCreate() val rawDataPath = args(0) val data = spark.sparkContext.textFile(rawDataPath) val parsedData = data.map(s => Vectors.dense(s.split(' ').map(_.toDouble))) val numClusters = 2 val numIterations = 20 val model = KMeans.train(parsedData, numClusters, numIterations) for (c <- model.clusterCenters) { println(s"cluster center: ${c.toString}") } val modelOutputPath = args(1) model.save(spark.sparkContext, modelOutputPath) } }将以上步骤的data.txt文件和FatJar文件上传至OSS中,操作详情可参见控制台上传文件。
使用DMS任务编排调度Spark任务
- 登录数据管理DMS 5.0。
在顶部菜单栏中,选择。
单击新增任务流。
在新建任务流对话框,将任务流名称设置为
Just_Spark,将描述设置为Just_Spark demo.,单击确认。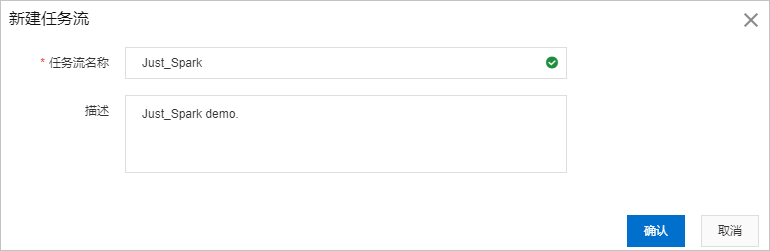
在任务编排页面中,将左侧任务类型中的DLA Serverless Spark拖拽到画布的空白区域。
在画布中双击DLA Serverless Spark节点,配置以下信息。
从地域列表中,选择目标Spark集群所在的地域。
从Spark 集群列表中,选择目标Spark集群。
在作业配置文本框中,输入以下代码。
{ "name": "spark-mllib-test", "file": "oss://oss-bucket-name/kmeans_demo/spark-mllib-1.0.0-SNAPSHOT.jar", "className": "com.aliyun.spark.SparkMLlib", "args": [ "oss://oss-bucket-name/kmeans_demo/data.txt", "oss://oss-bucket-name/kmeans_demo/model/" ], "conf": { "spark.driver.resourceSpec": "medium", "spark.executor.instances": 2, "spark.executor.resourceSpec": "medium", "spark.dla.connectors": "oss" } }说明file为FatJar文件在OSS中的绝对路径。args为data.txt与model在OSS中的绝对路径。
完成以上配置后,单击保存按钮。
单击页面左上方的试运行按钮进行测试。
如果执行日志的最后一行出现
status SUCCEEDED,表明任务试运行成功。如果执行日志的最后一行出现
status FAILED,表明任务试运行失败,在执行日志中查看执行失败的节点和原因,修改配置后重新尝试。
发布任务流。具体操作,请参见发布或下线任务流。
查看任务流的执行状态
- 登录数据管理DMS 5.0。
在顶部菜单栏中,选择。
单击任务流名称,进入任务流详情页面。
单击画布右上方前往运维,在任务流运维页面查看。
在任务流运维页面上方,查看任务流的创建时间、修改时间、调度配置情况、是否发布状态等基本信息。
单击运行记录页签,选择调度触发或手动触发,查看任务流运行记录。
说明调度触发:通过调度或指定时间的方式运行任务流。
手动触发:通过手动单击试运行的方式运行任务流。
单击状态列前的
 ,查看任务流运行日志。
,查看任务流运行日志。在操作列中,单击执行历史,查看任务流的操作时间、操作人员和操作内容。
在操作列中,对不同执行状态的任务流进行终止、重跑、暂停、恢复和置成功的操作。
说明对于执行成功的任务流,可以进行重跑操作。
对于执行失败的任务流,可以将该任务流运行记录的状态置为成功。
对于执行中的任务流,可以终止或暂停任务流运行。
单击发布列表页签,查看任务流的版本ID,发布人,发布时间、版本详情和DAG图。
您还可以选中任意2个版本ID,单击版本对比,查看版本的对比信息。