本文将为您介绍如何通过DataWorks创建、配置外部表,以及外部表支持的字段类型。
外部表概述
使用外部表前,您需要了解下表中的定义。
名称 | 描述 |
对象存储OSS | 提供标准、低频、归档存储类型,能够覆盖不同的存储场景。同时,OSS能够与Hadoop开源社区及EMR、批量计算、MaxCompute、机器学习和函数计算等产品进行深度结合。 |
MaxCompute | 大数据计算服务MaxCompute为您提供快速且完全托管的数据仓库解决方案,并可以通过与OSS的结合,高效经济地分析处理海量数据。 |
MaxCompute外部表 | 该功能基于MaxCompute新一代的V2.0计算框架,可以帮助您直接对OSS中的海量文件进行查询,无需将数据加载至MaxCompute表中。既减少了数据迁移的时间和人力,也节省了存储的成本。 |
下图为外部表的整体处理架构。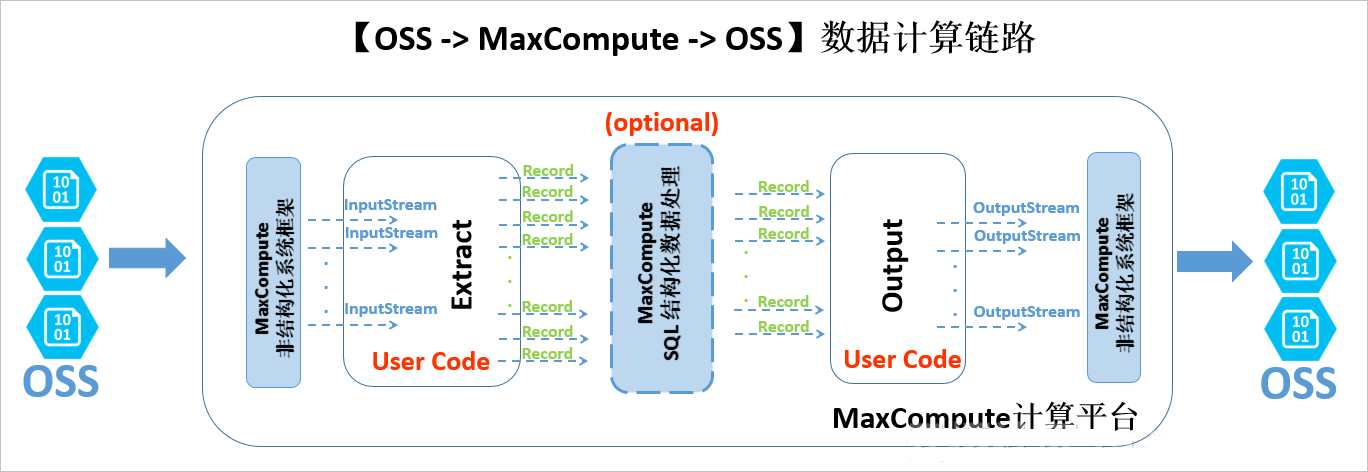
目前,MaxCompute主要支持OSS和OTS等非结构化存储的外部表。从数据的流动和处理逻辑的角度,非结构化处理框架在MaxCompute计算平台两端有耦合地进行数据导入和导出。以OSS外部表为例,处理逻辑如下:
外部的OSS数据经过非结构化框架转换,使用JAVA InputStream类提供给您自定义代码接口。您可以自己实现Extract逻辑,只需要负责对输入的InputStream进行读取、解析、转化和计算,最终返回MaxCompute计算平台通用的Record格式。
上述Record可以自由参与MaxCompute的SQL逻辑运算,该部分计算基于MaxCompute内置的结构化SQL运算引擎,并可能产生新的Record。
经过运算的Record传递给用户自定义的Output逻辑,您可以进行进一步的计算转换,并最终通过系统提供的OutputStream,输出Record中需要输出的信息,由系统负责写入至OSS。
您可以通过DataWorks配合MaxCompute,对外部表进行可视化的创建、搜索、查询、配置、加工和分析等操作。
网络与权限认证
由于MaxCompute与OSS是两个独立的云计算与云存储服务,所以在不同的部署集群上的网络连通性有可能影响MaxCompute访问OSS的数据的可达性。在MaxCompute中访问OSS存储时,建议您使用OSS私网地址(即以-internal.aliyuncs.com结尾的host地址)。
MaxCompute需要有一个安全的授权通道访问OSS数据。MaxCompute结合了阿里云的访问控制服务(RAM)和令牌服务(STS)实现对数据的安全访问。MaxCompute在获取权限时,以表的创建者的身份在STS申请权限(OTS的权限设置与OSS一致)。
STS模式授权
MaxCompute需要直接访问OSS的数据,因此需要将OSS数据相关权限赋给MaxCompute的访问账号。STS是阿里云为客户提供的一种安全令牌管理服务,它是资源访问管理(RAM)产品中的一员。通过STS服务,获得许可的云服务或RAM用户,可以自主颁发自定义时效和子权限的访问令牌。获得访问令牌的应用程序,可以使用令牌直接调用阿里云服务API操作资源。
您可以通过以下两种方式进行授权:
当MaxCompute和OSS的项目所有者是同一个账号时,请直接登录阿里云账号后进行一键授权。
打开新建表的编辑页面,找到物理模型设计模块。
勾选表类型后的外部表。
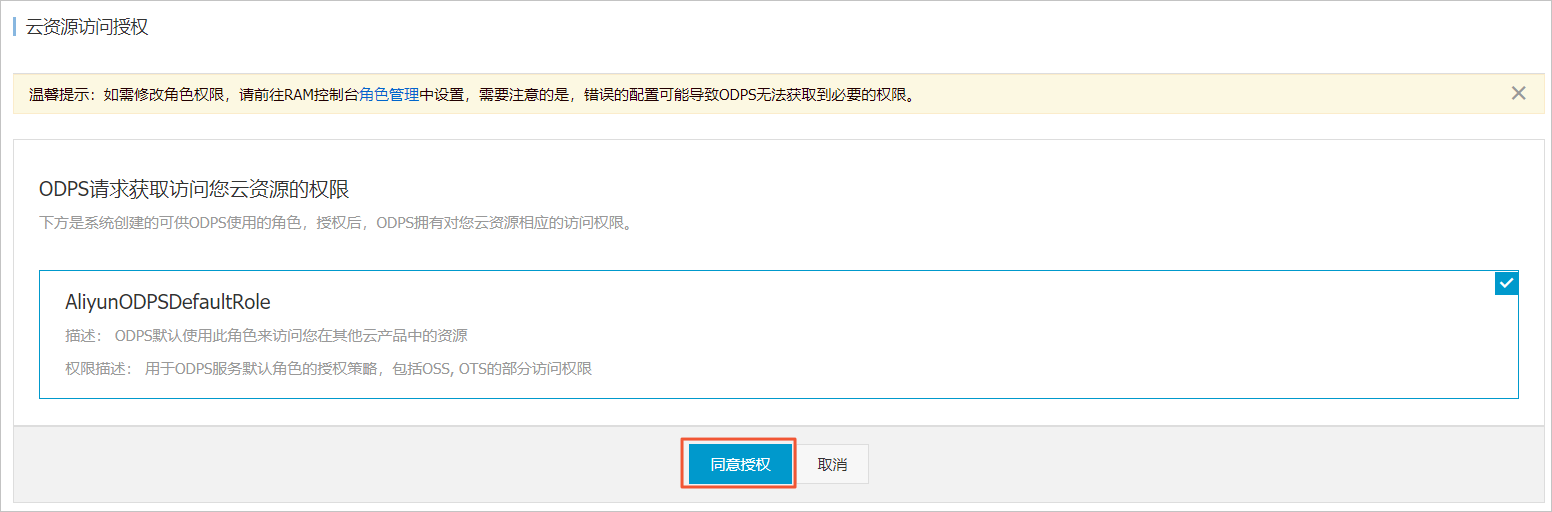
单击选择存储地址后的一键授权。

单击云资源访问授权对话框中的同意授权。
自定义授权,在RAM中授予MaxCompute访问OSS的权限。
登录RAM控制台。
说明如果MaxCompute和OSS不是同一个账号,此处需要由OSS账号登录并授权。
单击左侧导航栏中的。
单击创建角色,选择可信实体类型为阿里云账号,单击下一步。
输入角色名称和备注。
说明设置角色名称为AliyunODPSDefaultRole或AliyunODPSRoleForOtherUser。
选择信任的云账号为当前云账号或其他云账号。
说明如果选择其他云账号,请输入其他云账号的ID。
- 单击完成。
配置角色详情。
在RAM角色管理页面,单击相应的RAM角色名称。在信任策略管理页签下,单击编辑信任策略,根据自身情况输入下述策略内容。
--当MaxCompute和OSS的Owner是同一个账号。 { "Statement": [ { "Action": "sts:AssumeRole", "Effect": "Allow", "Principal": { "Service": [ "odps.aliyuncs.com" ] } } ], "Version": "1" }--当MaxCompute和OSS的Owner不是同一个账号。 { "Statement": [ { "Action": "sts:AssumeRole", "Effect": "Allow", "Principal": { "Service": [ "MaxCompute的Owner云账号id@odps.aliyuncs.com" ] } } ], "Version": "1" }配置完成后,单击保存信任策略。
配置角色授权策略,并找到授予角色访问OSS必要的权限AliyunODPSRolePolicy,将权限AliyunODPSRolePolicy授权给该角色。如果您无法通过搜索授权找到,可以通过精确授权直接添加。
{ "Version": "1", "Statement": [ { "Action": [ "oss:ListBuckets", "oss:GetObject", "oss:ListObjects", "oss:PutObject", "oss:DeleteObject", "oss:AbortMultipartUpload", "oss:ListParts" ], "Resource": "*", "Effect": "Allow" }, { "Action": [ "ots:ListTable", "ots:DescribeTable", "ots:GetRow", "ots:PutRow", "ots:UpdateRow", "ots:DeleteRow", "ots:GetRange", "ots:BatchGetRow", "ots:BatchWriteRow", "ots:ComputeSplitPointsBySize" ], "Resource": "*", "Effect": "Allow" }, { "Action": [ "pvtz:DescribeRegions", "pvtz:DescribeZones", "pvtz:DescribeZoneInfo", "pvtz:DescribeVpcs", "pvtz:DescribeZoneRecords" ], "Resource": "*", "Effect": "Allow" }, { "Action": [ "dlf:CreateFunction", "dlf:BatchGetPartitions", "dlf:ListDatabases", "dlf:CreateLock", "dlf:UpdateFunction", "dlf:BatchUpdateTables", "dlf:DeleteTableVersion", "dlf:UpdatePartitionColumnStatistics", "dlf:ListPartitions", "dlf:DeletePartitionColumnStatistics", "dlf:BatchUpdatePartitions", "dlf:GetPartition", "dlf:BatchDeleteTableVersions", "dlf:ListFunctions", "dlf:DeleteTable", "dlf:GetTableVersion", "dlf:AbortLock", "dlf:GetTable", "dlf:BatchDeleteTables", "dlf:RenameTable", "dlf:RefreshLock", "dlf:DeletePartition", "dlf:UnLock", "dlf:GetLock", "dlf:GetDatabase", "dlf:GetFunction", "dlf:BatchCreatePartitions", "dlf:ListPartitionNames", "dlf:RenamePartition", "dlf:CreateTable", "dlf:BatchCreateTables", "dlf:UpdateTableColumnStatistics", "dlf:ListTableNames", "dlf:UpdateDatabase", "dlf:GetTableColumnStatistics", "dlf:ListFunctionNames", "dlf:ListPartitionsByFilter", "dlf:GetPartitionColumnStatistics", "dlf:CreatePartition", "dlf:CreateDatabase", "dlf:DeleteTableColumnStatistics", "dlf:ListTableVersions", "dlf:BatchDeletePartitions", "dlf:ListCatalogs", "dlf:UpdateTable", "dlf:ListTables", "dlf:DeleteDatabase", "dlf:BatchGetTables", "dlf:DeleteFunction" ], "Resource": "*", "Effect": "Allow" } ] }
使用OSS数据源
如果您已创建并保存了OSS数据源,请在工作空间列表页面找到您所创建的工作空间,单击操作列的管理,在数据源页面进行查看和使用。
创建外部表
DDL模式建表
进入数据开发页面,参见创建并使用MaxCompute表进行DDL模式建表,您只需要遵守正常的MaxCompute语法即可。如果您的STS服务已成功授权,则无需设置odps.properties.rolearn属性。
DDL建表语句示例如下,其中EXTERNAL参数说明该表为外部表。
CREATE EXTERNAL TABLE IF NOT EXISTS ambulance_data_csv_external( vehicleId int, recordId int, patientId int, calls int, locationLatitute double, locationLongtitue double, recordTime string, direction string ) STORED BY 'com.aliyun.odps.udf.example.text.TextStorageHandler' --STORED BY用于指定自定义格式StorageHandler的类名或其它外部表文件格式,必选。 with SERDEPROPERTIES ( 'delimiter'='\\|', --SERDEPROPERTIES序列化属性参数,可以通过DataAttributes传递到Extractor代码中,可选。 'odps.properties.rolearn'='acs:ram::xxxxxxxxxxxxx:role/aliyunodpsdefaultrole' ) LOCATION 'oss://oss-cn-shanghai-internal.aliyuncs.com/oss-odps-test/Demo/SampleData/CustomTxt/AmbulanceData/' --外部表存放地址,必选。 USING 'odps-udf-example.jar'; --指定自定义格式时类定义所在的Jar包,如果未使用自定义格式无需指定。关于STORED BY后接参数,其中CSV或TSV文件对应默认内置的StorageHandler,具体参数如下:
CSV为
com.aliyun.odps.CsvStorageHandler,定义如何读写CSV格式数据,数据格式约定列分隔符为英文逗号(,)、换行符为(\n)。实际参数输入示例:STORED BY'com.aliyun.odps.CsvStorageHandler'。TSV为
com.aliyun.odps.TsvStorageHandler,定义如何读写TSV格式数据,数据格式约定列分隔符为(\t)、换行符为(\n)。
STORED BY后接参数还支持ORC、PARQUET、SEQUENCEFILE、RCFILE、AVRO和TEXTFILE 开源格式外部表,如下所示。对于textFile可以指定序列化类,例如
org.apache.hive.hcatalog.data.JsonSerDe。org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe -> stored as textfile
org.apache.hadoop.hive.ql.io.orc.OrcSerde -> stored as orc
org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe -> stored as parquet
org.apache.hadoop.hive.serde2.avro.AvroSerDe -> stored as avro
org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe -> stored as sequencefile
对于开源格式外部表,建表语句如下。
CREATE EXTERNAL TABLE [IF NOT EXISTS] (<column schemas>) [PARTITIONED BY (partition column schemas)] [ROW FORMAT SERDE ''] STORED AS [WITH SERDEPROPERTIES ( 'odps.properties.rolearn'='${roleran}' [,'name2'='value2',...] ) ] LOCATION 'oss://${endpoint}/${bucket}/${userfilePath}/';SERDEPROPERTIES序列化属性列表如下所示。
属性名
属性值
默认值
描述
odps.text.option.gzip.input.enabled
true/false
false
打开或关闭读压缩
odps.text.option.gzip.output.enabled
true/false
false
打开或关闭写压缩
odps.text.option.header.lines.count
非负整数
0
跳过文本文件头N行
odps.text.option.null.indicator
字符串
空字符串
在解析或者写出NULL值时,代表NULL的字符串
odps.text.option.ignore.empty.lines
true/false
true
是否忽略空行
odps.text.option.encoding
UTF-8/UTF-16/US-ASCII
UTF-8
指定文本的字符编码
说明MaxCompute目前仅支持通过内置extractor读取OSS上gzip压缩的CSV或TSV数据,您可以选择文件是否是gzip压缩,不同的文件格式对应不同的属性设置。
LOCATION参数,格式为:oss://oss-cn-shanghai-internal.aliyuncs.com/Bucket名称/目录名称。您可以通过图形对话框选择获得OSS目录地址,目录后无需加文件名称。
DDL模式创建的表会出现在表管理的表节点树下,可以通过修改其一级、二级主题来调整显示位置。
OTS外部表
OTS外部表建表语句如下。
CREATE EXTERNAL TABLE IF NOT EXISTS ots_table_external( odps_orderkey bigint, odps_orderdate string, odps_custkey bigint, odps_orderstatus string, odps_totalprice double ) STORED BY 'com.aliyun.odps.TableStoreStorageHandler' WITH SERDEPROPERTIES ( 'tablestore.columns.mapping'=':o_orderkey,:o_orderdate,o_custkey, o_orderstatus,o_totalprice', -- (3) 'tablestore.table.name'='ots_tpch_orders' 'odps.properties.rolearn'='acs:ram::xxxxx:role/aliyunodpsdefaultrole' ) LOCATION 'tablestore://odps-ots-dev.cn-shanghai.ots-internal.aliyuncs.com';参数说明如下:
com.aliyun.odps.TableStoreStorageHandler是MaxCompute内置的处理TableStore数据的StorageHandler。
SERDEPROPERTIES是提供参数选项的接口,在使用TableStoreStorageHandler时,有两个必须指定的选项:tablestore.columns.mapping和 tablestore.table.name。
tablestore.columns.mapping:必选项,用来描述MaxCompute将访问的Table Store表的列,包括主键和属性以(:)打头的用来表示Table Store主键,例如此语句中的
:o_orderkey和:o_orderdate,其它均为属性列。Table Store支持1~4个主键,主键类型为STRING、INTEGER和BINARY,其中第一个主键为分区键。指定映射时,您必须提供指定Table Store表的所有主键,对于属性列则没有必要全部提供,可以只提供需要通过MaxCompute来访问的属性列。
tablestore.table.name:需要访问的Table Store表名。如果指定的Table Store表名错误(不存在),则会报错, MaxCompute不会主动去创建Table Store表。
LOCATION:用来指定Table Storeinstance名字、endpoint等具体信息。
图形化建表
进入数据开发页面,参见创建并使用MaxCompute表进行图形化建表。外部表具有如下属性:
基本属性
英文表名(在新建表时输入)
中文表名
一级、二级主题
描述
物理模型设计
表类型:请选择为外部表。
分区类型:OTS类型外部表不支持分区。
选择存储地址:即LOCATION参数。您可以在物理模型设计栏中设置LOCATION参数。单击点击选择,即可选择存储地址。选择完成后,单击一键授权。
选择存储格式:根据业务需求进行选择,支持CSV、TSV、ORC、PARQUET、SEQUENCEFILE、RCFILE、AVRO、TEXTFILE和自定义文件格式。如果您选择了自定义文件格式,需要选择自定义的资源。在提交资源时,可以自动解析出其包含的类名并可以供用户选取。
rolearn:如果STS已授权,可以不填写。
表结构设计

参数
描述
字段类型
MaxCompute 2.0支持TINYINT、SMALLINT、INT、BIGINT、VARCHAR和STRING类型。
操作
支持新增、修改和删除。
长度/设置
对于VARCHAR类型,可以支持设置长度。对于复杂类型可以直接填写复杂类型的定义。
支持的字段类型
外部表支持的简单字段类型如下表所示。
类型 | 是否新增 | 格式举例 | 描述 |
TINYINT | 是 | 1Y,-127Y | 8位有符号整型,范围为-128~127。 |
SMALLINT | 是 | 32767S, -100S | 16位有符号整型,范围为-32,768~32,767。 |
INT | 是 | 1000,-15645787 | 32位有符号整型,范围为-2^31~2^31-1。 |
BIGINT | 否 | 100000000000L, -1L | 64位有符号整型,范围为-2^63+1~2^63-1。 |
FLOAT | 是 | 无 | 32位二进制浮点型。 |
DOUBLE | 否 | 3.1415926 1E+7 | 8字节双精度浮点数,64位二进制浮点型。 |
DECIMAL | 否 | 3.5BD,99999999999.9999999BD | 10进制精确数字类型,整型部分范围为-1,036+1~1,036-1,小数部分精确到10~18。 |
VARCHAR(n) | 是 | 无 | 变长字符类型,n为长度,取值范围为1~65,535。 |
STRING | 否 | “abc”,’bcd’,”alibaba” | 字符串类型,目前长度限制为8MB。 |
BINARY | 是 | 无 | 二进制数据类型,目前长度限制为8MB。 |
DATETIME | 否 | DATETIME ‘2017-11-11 00:00:00’ | 日期时间类型,使用东八区时间作为系统标准时间。范围0000年1月1日~9999年12月31日,精确到毫秒。 |
TIMESTAMP | 是 | TIMESTAMP ‘2017-11-11 00:00:00.123456789’ | 与时区无关的时间戳类型,范围为0000年1月1日~9999年12月31日23.59:59.999,999,999,精确到纳秒。 |
BOOLEAN | 否 | 包括TRUE和FALSE | BOOLEAN类型,取值TRUE或FALSE。 |
外部表支持的复杂字段类型如下表所示。
类型 | 定义方法 | 构造方法 |
ARRAY | array< int >; array< struct< a:int, b:string >> | array(1, 2, 3); array(array(1, 2); array(3, 4)) |
MAP | map< string, string >; map< smallint, array< string>> | map(“k1”, “v1”, “k2”, “v2”); map(1S, array(‘a’, ‘b’), 2S, array(‘x’, ‘y)) |
STRUCT | struct< x:int, y:int>; struct< field1:bigint, field2:array< int>, field3:map< int, int>> | named_struct(‘x’, 1, ‘y’, 2); named_struct(‘field1’, 100L, ‘field2’, array(1, 2), ‘field3’, map(1, 100, 2, 200)) |
如果需要使用MaxCompute 2.0支持的新数据类型(TINYINT、SMALLINT、 INT、 FLOAT、VARCHAR、TIMESTAMP 、BINARY或复杂类型),需要在建表语句前加上语句set odps.sql.type.system.odps2=true;,set语句和建表语句一起提交执行。如果需要兼容HIVE,建议加上语句odps.sql.hive.compatible=true;。
查看和处理外部表
您可以在数据开发页面,单击左侧导航栏中的表管理,查询外部表,详情请参见表管理。处理外部表的方式与内部表基本一致。