DataWorks数据集成提供了单表实时同步任务,旨在实现不同数据源之间低延迟、高吞吐量的数据复制与流转。该功能基于先进的实时计算引擎,能够捕获源端数据的实时变更(增、删、改),并将其快速应用到目标端。本文以LogHub(SLS)单表实时同步至MaxCompute为例,讲述单表实时任务的配置方式。
准备工作
数据源准备
已创建来源与去向数据源,数据源配置详见:数据源管理。
确保数据源支持实时同步能力,参见:支持的数据源及同步方案。
资源组:已购买并配置Serverless资源组。
网络连通:资源组与数据源之间需完成网络连通配置。
步骤一:新建同步任务
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据集成。
在左侧导航栏单击同步任务,然后在页面顶部单击新建同步任务,并配置任务信息,此处以LogHub(SLS)实时写入MaxCompute为例:
数据来源类型:
LogHub。数据去向类型:
MaxCompute。具体类型:
单表实时。同步步骤:
结构迁移:自动在目标端创建与源端匹配的数据库对象(如表、字段、数据类型等),但不包含数据。
增量同步:持续地捕获源端发生的变更数据(新增、修改、删除),并将其同步至目标端。
支持的数据源及同步方案请参见:支持的数据源及同步方案。
步骤二:配置数据源与运行资源
来源数据源选择已添加的
Kafka数据源,去向数据源选择已添加的MaxCompute数据源。在运行资源区域,选择同步任务所使用的资源组,并为该任务分配资源组CU。支持为全量同步和增量同步分别设置CU,以精确控制资源,避免浪费。如果您的同步任务因资源不足出现OOM现象,请适当调整资源组的CU占用取值。
说明CU是资源组的计量计费单位,1 CU ≈ 1核4 GB内存。建议初次配置时预估吞吐量需求,后续可根据实际监控情况调整。
并确保来源数据源与去向数据源均通过连通性检查。
步骤三:配置同步方案
1. 配置数据来源
在数据来源区域,配置 LogHub(SLS)数据来源信息。
在数据来源信息区域,选择需要同步的 Logstore。
Logstore:从下拉列表中选择已有的 Logstore。
单击数据采样,对 LogHub 数据进行采样预览。
在弹出对话框中配置开始时间和采样条数,然后单击开始采集。数据采样结果可为后续的数据处理节点提供预览输入。
在输出字段配置区域,系统会自动加载 Logstore 中的字段列表。可调整数据类型、删除以及手动增加输出字段。
如果配置的字段在 SLS 中不存在,则对应字段向下游输出为 NULL。
2. 数据处理
开启数据处理按钮,目前提供5种数据处理方式(数据脱敏、字符串替换、数据过滤、JSON解析和字段编辑与赋值),您可根据需要做顺序编排,在任务运行时会按照编排的数据处理先后顺序执行数据处理。
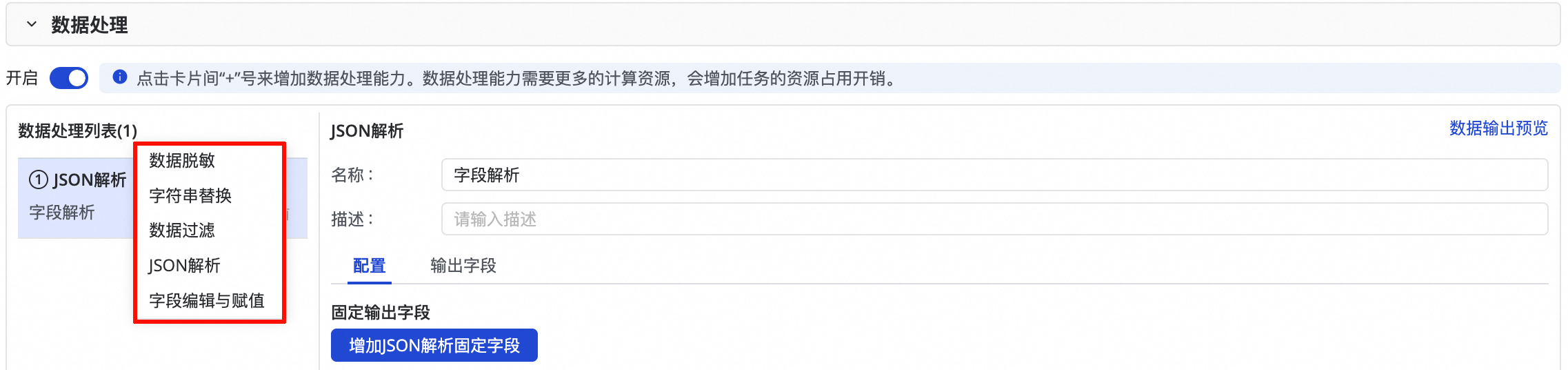
每完成一个数据处理节点配置,可以单击右上角的数据输出预览按钮:
在输入数据下方的表格中,可以看到上个环节数据采样的结果。您可以单击重新获取上游输出,来刷新结果。
如果上游没有输出结果,也可以通过手工构造数据来模拟前置输出。
单击预览,可以查看上游环节输出的数据,经过数据处理节点
处理后输出的结果。
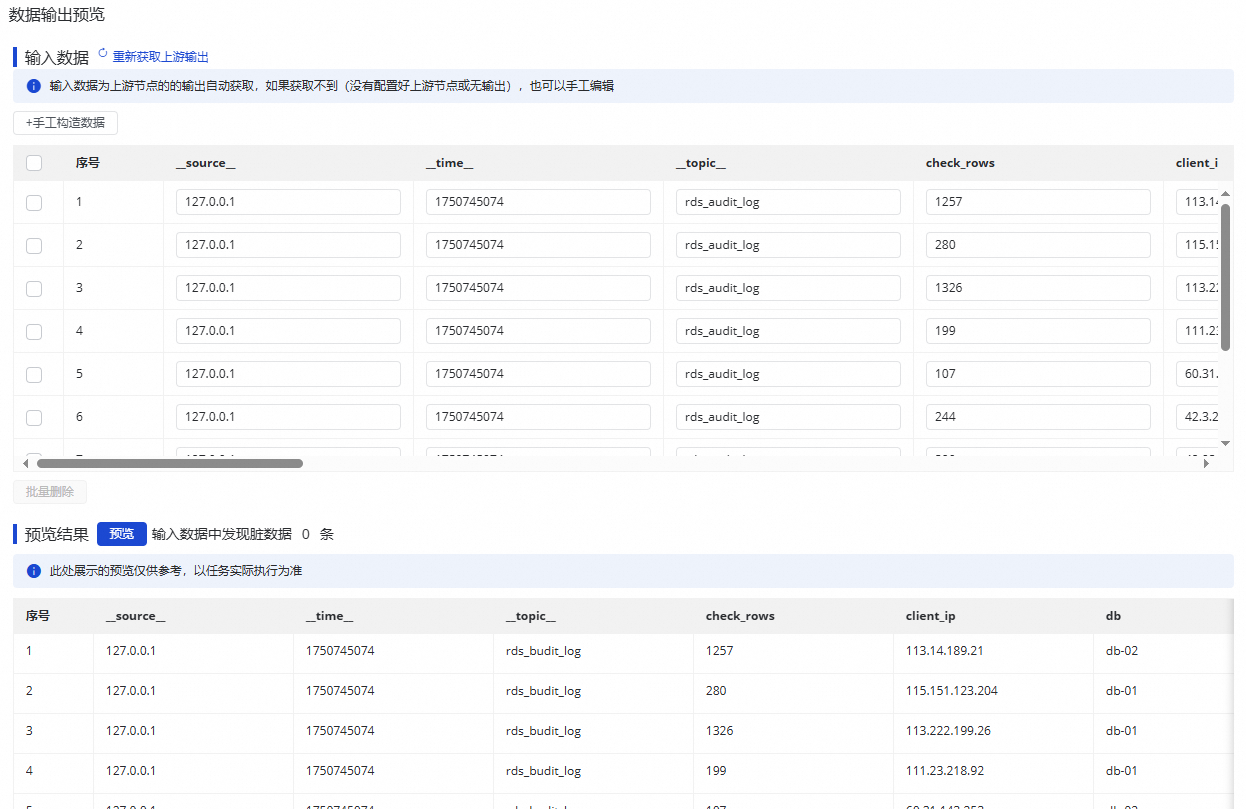
数据输出预览强依赖 LogHub(SLS)来源的数据采样,在执行数据输出预览前需要先在 LogHub(SLS)来源表单中完成数据采样。
3. 配置数据去向
在数据去向区域,选择Tunnel资源组,默认选择“公共传输资源”,即MC的免费quota。
选择要写入目标表是新建表还是使用已有表。
如果是新建表,可在下拉列表中选择新建,默认会创建与数据来源端结构相同的表,您可以手动修改目标端表名和表结构。
如果是使用已有表,请下拉选择需要同步的目标表。
(可选)编辑表结构。
单击表名后的编辑按钮,可编辑该表的表结构,支持单击根据上游节点输出列重新生成表结构按钮,自动根据上游节点输出列,生成表结构。您可以在自动生成的表结构中选择一列配置为主键。
4. 配置字段映射
系统会自动按照同名映射原则生成上游列与目标表列之间的映射,您可根据需要进行调整,支持一个上游列映射到多个目标表列,不允许多个上游列映射到一个目标表列,当上游列未配置到目标表列的映射时,对应列不会写入目标表。
分区设置(可选)。
时间自动分区是根据业务时间(此处为_timestamp)字段进行分区的,一级分区为年,二级分区为月,以此类推。
根据字段内容动态分区通过指定源端表某字段与目标MaxCompute表分区字段对应关系,实现源端对应字段所在数据行写入到MaxCompute表对应的分区中。
步骤四:高级配置
同步任务提供高级参数可供精细化配置,系统设有默认值,多数情况下无需修改。如有修改必要,您可以:
单击界面右上方的高级配置,进入高级参数配置页面。
说明数据开发的高级配置位于任务配置界面右侧页签。
支持为同步任务的读端和写端分别设置参数。修改自动设置运行时配置,设置为false,可以自定义运行时配置。
根据参数提示,修改参数值,参数含义见参数名称后的解释。部分参数的配置建议可参考实时同步高级参数。
请在完全了解参数含义与作用后果再进行修改,以免产生不可预料的错误或者数据质量问题。
步骤五:模拟运行
数据开发中的单表实时,模拟运行功能位于工具栏。
完成上述所有任务配置后,您可以单击左下角的模拟运行来调试任务,模拟整个任务针对少量采样数据的处理,查看数据写入目标表后的结果。当任务配置错误、模拟运行过程中异常或者产生脏数据时,会实时反馈出异常信息,能够帮助您快速评估任务配置的正确性,以及是否能得到预期结果。
在弹出的对话框中设置采样参数(开始时间和采样条数)。
单击开始采集得到采样数据。
单击预览结果按钮,模拟任务运行,并查看输出结果。
模拟运行输出的结果仅作预览,不会写入目标端数据源,对生产数据造成影响。
步骤六:发布并执行任务
完成所有配置后,单击页面底部的保存,完成任务配置。
数据集成的任务需要发布至生产环境运行,因此新建或者编辑任务均需执行发布操作后方可生效。发布时,若勾选发布后直接启动运行,则在发布时会同步启动任务。否则,发布完成后,需要进入界面,在目标任务的操作列,手动启动任务。
单击任务列表中对应任务的名称/ID,查看任务的详细执行过程。
步骤七:配置报警规则
任务发布上线运行后,可以为其配置告警规则,以便在任务出现异常时第一时间获得通知,确保生产环境的稳定性和数据时效性。在数据集成的任务列表,单击目标任务操作列的。
1.新增报警
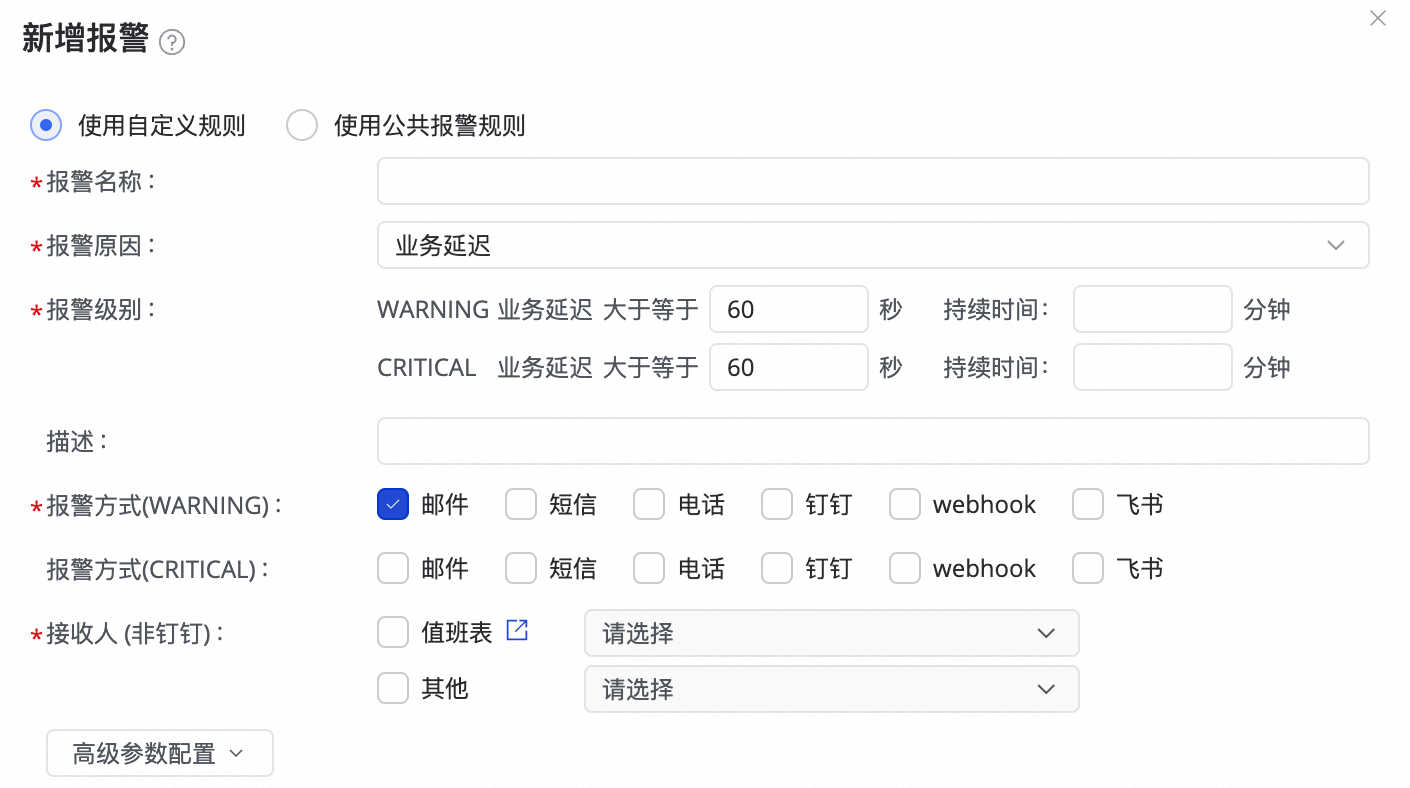
(1) 单击新建规则,配置报警规则。
您可以通过设置报警原因,对任务的业务延迟、Failover、任务状态、DDL通知、任务资源利用率等指标进行监控,并根据指定的阈值设置CRITICAL或WARNING两种不同级别的告警方式。
设置报警方式后,可通过设置高级参数配置,控制报警信息发送的时间间隔,防止一次性发送信息太多,造成浪费和消息堆积。
若报警原因选择业务延迟、任务状态和任务资源利用率,也支持开启恢复通知,方便任务恢复正常后,通知接收人。
(2) 管理报警规则。
对于已创建的报警规则,您可以通过报警开关控制报警规则是否开启,同时,您可以根据报警级别将报警发送给不同的人员。
2.查看报警
单击展开任务列表的,进入报警事件,可以查看已经发生的告警信息。
后续步骤
任务启动后,您可以:
在同步任务列表中查看任务运行状态和执行概况。
单击任务名称,进入任务详情页面,查看结构迁移和实时数据同步的详细信息。
在操作列对任务进行启动或停止,或在更多中进行编辑、查看等操作。
常见问题
实时同步任务常见问题请参见实时同步常见问题。