本文为您介绍如何通过创建同步任务,导出MaxCompute中的数据至MySQL数据源中。
前提条件
已通过RDS创建MySQL实例,获取RDS实例ID,并在RDS控制台添加白名单。详情请参见创建RDS MySQL实例。
说明通过Serverless资源组调度RDS的数据同步任务时需注意:
通过内网访问,请将资源组绑定的交换机网段IP添加到数据源的白名单列表。
通过公网访问,将Serverless资源组绑定VPC配置的EIP添加至数据源的白名单列表。
详情请参见:添加白名单。
如果您使用的是RDS MySQL数据库,请在RDS MySQL数据库中创建表odps_result,建表语句如下所示。
CREATE TABLE `ODPS_RESULT` ( `education` varchar(255) NULL , `num` int(10) NULL );建表完成后,您可以执行
desc odps_result;语句,查看表详情。已准备好结果表result_table,详情请参见建表并上传数据。
已创建虚拟节点(start)和ODPS SQL节点(insert_data),详情请参见创建业务流程。
背景信息
在DataWorks中,通常通过数据集成功能,定期将系统中产生的业务数据导入至工作区。SQL任务进行计算后,再定期将计算结果导出至您指定的数据源中,以便进一步展示或使用。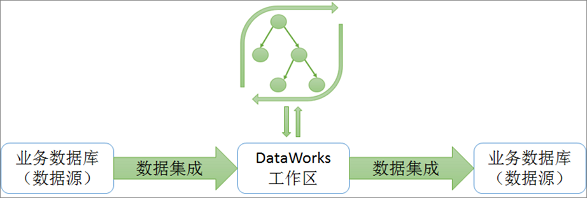
目前数据集成功能支持从RDS、MySQL、SQL Server、PostgreSQL、MaxCompute、OCS、DRDS、OSS、Oracle、FTP、DM、HDFS和MongoDB等数据源中,导入数据至工作空间或从工作空间导出数据。详细的数据源类型列表请参见支持的数据源与读写插件。
步骤一:新增数据源
仅项目管理员角色可以新建数据源,其他角色的成员仅支持查看数据源。
进入管理中心页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入管理中心。
创建MySQL数据源。
单击左侧导航栏的,进入数据源列表页面。
单击新增数据源,在新增数据源对话框中选择数据源类型为MySQL。
配置数据源信息。
在创建MySQL数据源对话框,配置各项参数。本文以创建阿里云实例模式类型为例。
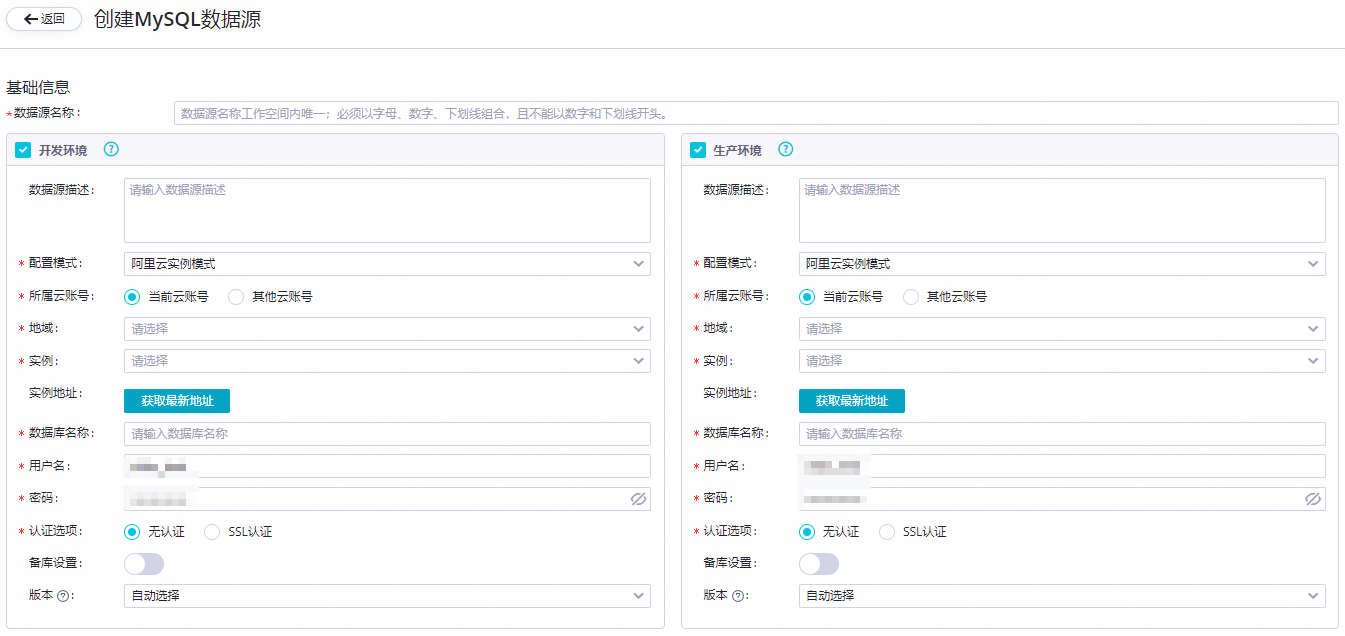
核心参数说明如下。
参数
描述
适用环境
分别配置开发环境及生产环境的数据源。
配置模式
选择阿里云实例模式。
所属云账号
选择当前云账号。
地域
选择相应地域。
实例
选择已创建的RDS MySQL实例。选择实例后,可单击获取最新地址,查看实例相关信息。
若无可用实例,您可进入RDS控制台创建新的实例。
数据库登录信息
此处配置为该数据源对应的默认数据库名称,您需要输入登录数据库的用户名称及密码,密码中避免使用@符号。
后续配置同步任务的说明如下:
配置整库同步(包含实时和离线),您可以选择相应RDS实例下所有具有权限的数据库。
配置离线同步任务,当您选择使用多个数据库时,则每个数据库均需要配置一个数据源。
认证选项
选择无认证。
备库设置
如果数据源具备只读实例(备库),可以在配置任务时开启备库设置,并选择备库ID。设置备库的优势是防止干扰主库,不影响主库性能。如果有多个只读实例,则会任选一个可用的来读取。
说明此功能仅支持Serverless资源组。
测试资源组连通性。
在数据集成和数据调度页签下,分别单击相应资源组后的测试连通性,连通状态为可连通时,表示连通成功。
说明数据同步时,一个任务只能使用一种资源组。
您需要测试每种资源组的连通性,以保证同步任务使用的资源组能够与数据源连通,否则将无法正常执行数据同步任务。
测试连通性通过后,单击完成创建,数据源创建完成。
步骤二:新建并配置同步任务
通过创建同步节点write_result来生成一个同步任务,用于将result_table表中的数据写入至自己的MySQL数据库中。操作如下:
进入数据开发页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据开发。
创建离线同步节点。
单击新建
 图标,选择,新建一个离线同步节点。
图标,选择,新建一个离线同步节点。配置同步任务网络链接。
在节点编辑页面的网络与资源配置页签,配置数据来源为MaxCompute(ODPS)、数据去向为MySQL,并选择用于执行同步任务的资源组,测试数据源与资源组的网络连通性。网络连通性配置,详情请参见网络连通方案。
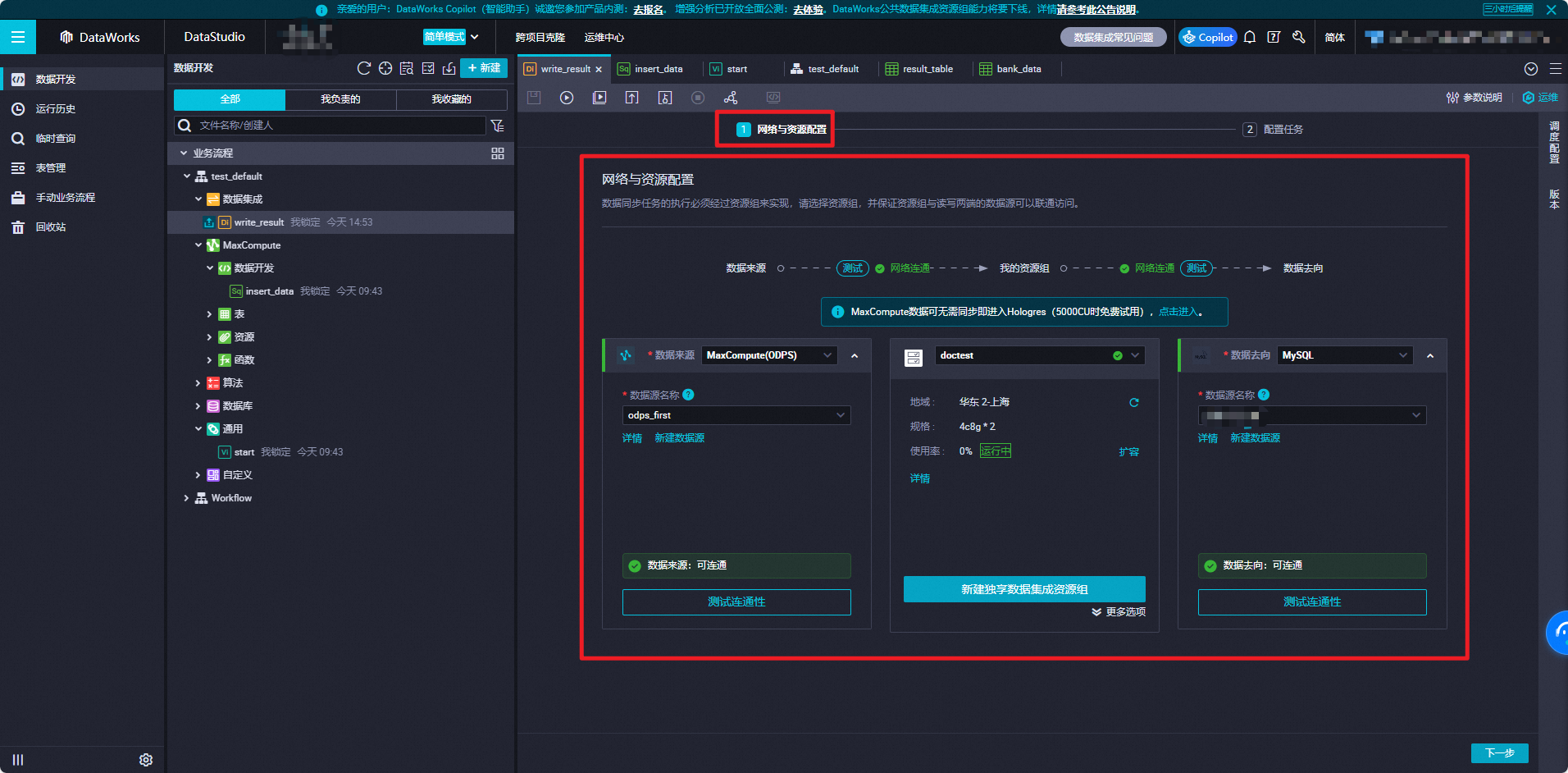
单击下一步,进入任务配置界面。
配置同步任务信息。
配置数据来源与去向。
数据来源选择result_table表,数据去向选择odps_result表。其他参数可根据业务需求选择配置,配置详情可参考通过向导模式配置离线同步任务。
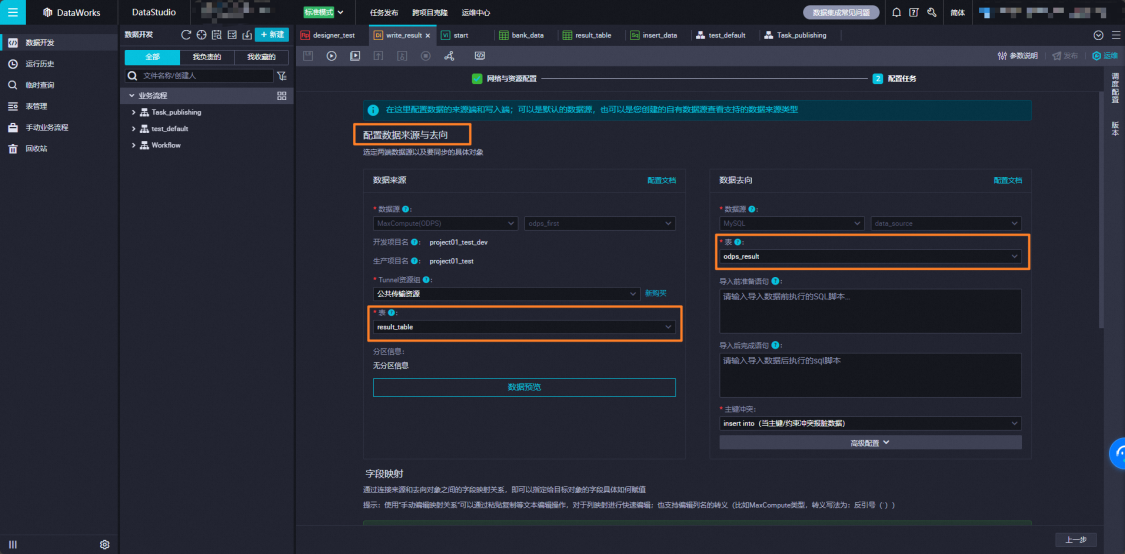
配置字段映射。
选择数据来源和数据去向后,需指定源端和目标端列的映射关系,配置字段映射关系后,任务将根据字段映射关系,将源端字段写入目标端对应类型的字段中。此处需配置源端表字段和目标表字段为一一对应关系。
配置通道控制。
参数
描述
任务期望最大并发数
用于定义当前任务从源端并行读取或并行写入目标端的最大线程数。
说明由于资源规格等原因,实际执行时并发数可能小于等于此处配置的并发数,调试资源组收费将按照实际执行的并发数收费。详情请参见:性能指标。
离线同步任务将通过调度资源组下发至数据集成任务执行资源组上执行,任务调度收费与离线同步任务个数有关,和任务配置的并发无关。关于离线同步任务下发机制,详情请参见:DataWorks资源组概述。
同步速率
用于控制同步速率。
限流:您可以通过限流控制同步速率,以保护读取端数据库,避免抽取速度过大,给源库造成太大的压力。限速最小配置为1MB/s。
不限流:在不限流的情况下,任务将在所配置的并发数的限制基础上,提供现有硬件环境下最大的传输性能。
说明流量度量值是数据集成本身的度量值,不代表实际网卡流量。通常,网卡流量是通道流量膨胀的1至2倍,实际流量膨胀取决于具体的数据存储系统传输序列化情况。
脏数据策略
用于定义脏数据阈值,及对任务的影响。
重要当脏数据过多时,会影响同步任务的整体同步速度。
不配置时默认允许脏数据,即任务产生脏数据时不影响任务执行。
配置为0,表示不允许脏数据存在。如果同步过程中产生脏数据,任务将失败退出。
允许脏数据并设置其阈值时:
若产生的脏数据在阈值范围内,同步任务将忽略脏数据(即不会写入目标端),并正常执行。
若产生的脏数据超出阈值范围,同步任务将失败退出。
说明脏数据认定标准:脏数据是对业务没有意义,格式非法或者同步过程中出现问题的数据。单条数据写入目标数据源过程中发生了异常,则此条数据为脏数据。因此只要是写入失败的数据均被归类于脏数据。
例如,源端是VARCHAR类型的数据写入INT类型的目标列中,则会因为转换不合理导致脏数据无法成功写入目的端。您可以在同步任务配置时,控制同步过程中是否允许脏数据产生,并且支持控制脏数据条数,即当脏数据超过指定条数时,任务失败退出。
分布式处理能力
用于控制是否开启分布式模式来执行当前任务。
开启:分布式执行模式可以将您的任务切片分散到多台执行节点上并发执行,进而做到同步速度随着执行集群规模做水平扩展,突破单机执行瓶颈。
未开启:配置的并发数据仅仅是单机上的进程并发,无法利用多机联合计算。
如果您对于同步性能有比较高的诉求可以使用分布式模式。另外分布式模式也可以使用机器的碎片资源,对资源利用率友好。
重要如果使用独享数据集成资源组,且只有1台机器,不建议使用分布式,因为无法利用多机资源能力。
如果单机已经满足速度需要,建议优选单机模式,简化任务执行模式。
并发数大于等于8个才能开启分布式处理能力。
开启分布式处理开关会占用更多资源,如运行时报错内存溢出(OOM),可尝试关闭此开关。
配置任务依赖关系。
双击当前业务流程,设置insert_data节点为write_result节点的上游节点。
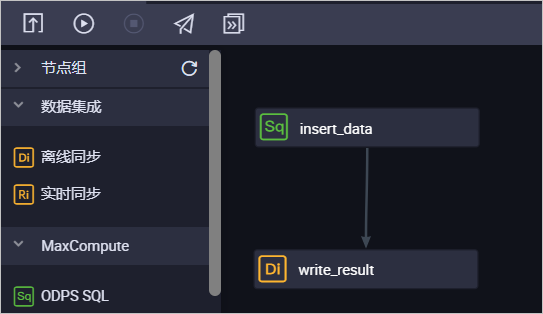
任务配置完成后,单击工具栏的
 图标,保存任务。
图标,保存任务。
步骤三:提交并发布任务
同步任务保存后,返回业务流程。单击工具栏中的![]() 图标,提交同步任务至调度系统。调度系统会根据配置的属性,从第二天开始自动定时执行。
图标,提交同步任务至调度系统。调度系统会根据配置的属性,从第二天开始自动定时执行。
后续步骤
现在,您已经学习了如何创建同步任务,将数据导出至不同类型的数据源中,您可以继续下一个教程。在该教程中,您将学习如何设置同步任务的调度属性和依赖关系。详情请参见设置周期和依赖。
相关文档
更多离线任务的配置,详情请参见配置离线同步任务。