实时同步单表数据时,当输入数据源为PolarDB时,执行同步任务前,您需要参考本文在数据源中配置好网络、白名单等配置,为后续的数据同步做好网络环境和账号权限的准备。
前提条件
在进行数据源配置前,请确保已完成以下规划与准备工作。
数据源准备:已购买输入数据源PolarDB MySQL、输出数据源。输出数据源可以为MaxCompute、Hologres、Elasticsearch、DataHub及Kafka。本文以阿里云PolarDB MySQL作为来源数据源进行示例。
资源规划与准备:已购买独享数据集成资源组,并完成资源配置。详情可参见资源规划与配置。
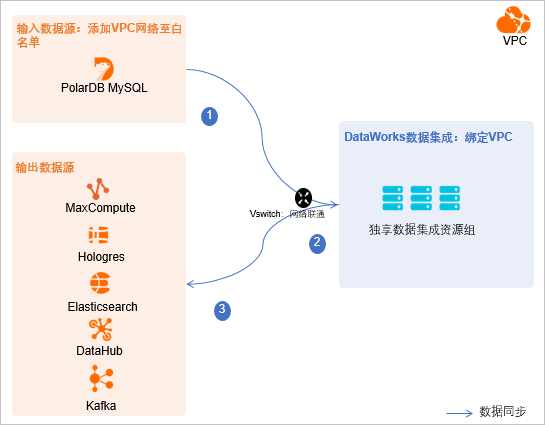
网络环境评估与规划:进行数据集成前,您需根据业务情况,打通数据源、独享数据集成资源组之间的网络,网络联通后参考本文进行交换机、白名单等网络环境下的访问配置。
如果数据源和独享数据集成资源组均处于同地域的同一VPC网络中,数据源与资源组间的网络天然联通。
如果数据源和独享数据集成资源组均处于不同的网络环境中,您需要通过VPN网关等方式,将数据源与资源组间的网络打通。
背景信息
将输入数据源的数据同步至输出数据源时,您需要保障数据源与DataWorks的数据集成资源组在网络上是联通的,且不存在账号权限的访问限制。
网络白名单
以下以使用同一VPC网络环境为例,您需要将数据集成资源组所在的VPC网段添加至白名单中,保障数据集成资源组可访问数据源。
账号权限
您需要规划一个可访问数据源的账号,用于后续数据集成过程中访问数据源并进行数据提取、写入的同步操作。
其他访问限制。
输入数据源为阿里云PolarDB MySQL时,您需要开启Binlog。阿里云PolarDB MySQL是一款完全兼容MySQL的云原生数据库,默认使用了更高级别的物理日志代替Binlog,但为了更好地与MySQL生态融合,PolarDB支持开启Binlog的功能。
使用限制
目前仅支持使用同步方案同步PolarDB MySQL类型的数据源,不支持同步其他类型的PolarDB数据源。文中均使用PolarDB代指PolarDB MySQL类型的数据源。
PolarDB目前只能用主节点(读写库)进行实时同步。
不支持XA ROLLBACK,针对已经XA PREPARE的事务数据,实时同步会将其同步到目标端,如果XA ROLLBACK,实时同步不会针对XA PREPARE的数据做回滚写入的操作。若要处理XA ROLLBACK场景,需要手动将XA ROLLBACK的表从实时同步任务中移除,再添加表后重新进行全量数据初始化以及增量实时同步。
操作步骤
配置白名单。
将独享数据资源组所在的VPC网段添加至PolarDB集群白名单中,操作如下:
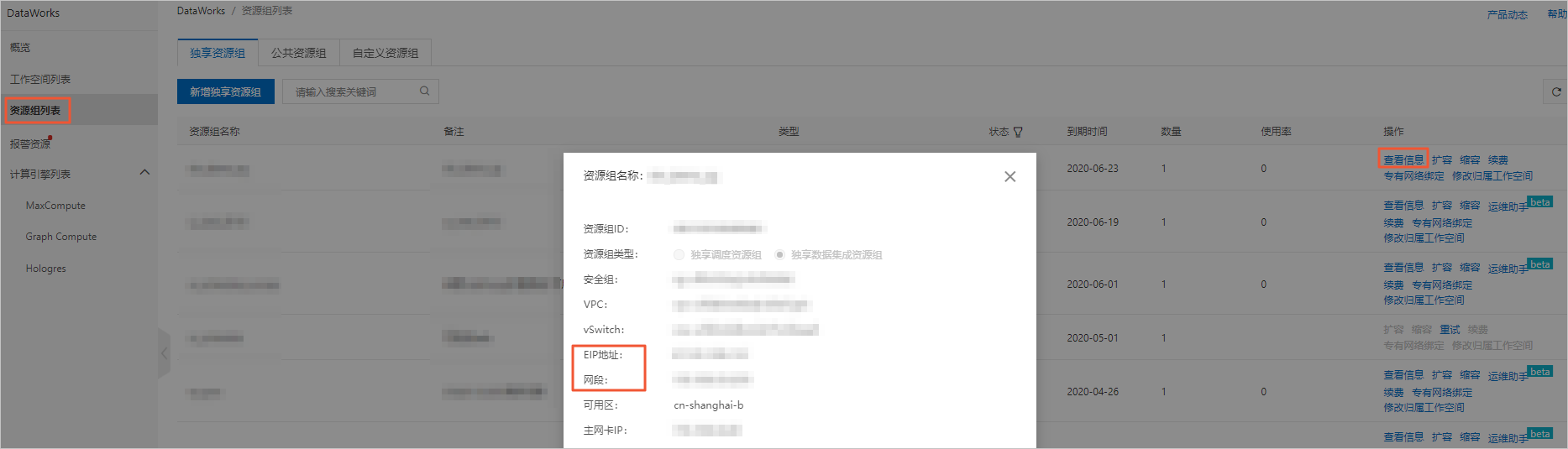
查看并记录独享数据资源组所在的VPC网络。
登录DataWorks控制台。
在左侧导航栏,单击资源组列表。
在独享资源组页签下,单击目标数据集成资源组后的查看信息。
复制对话框中的EIP地址和网段至数据库白名单。
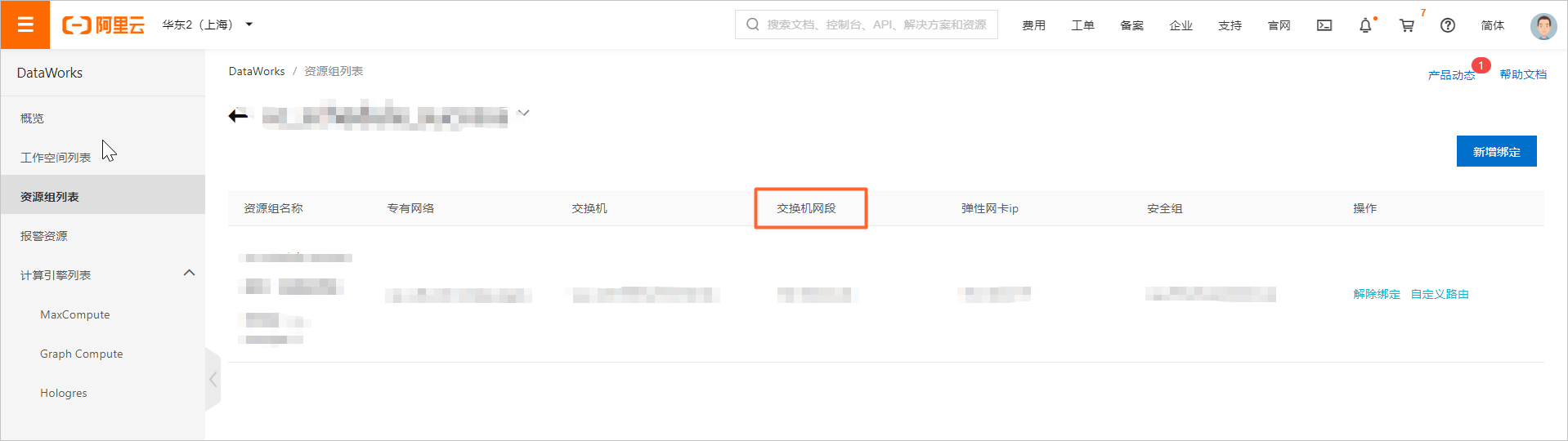
在独享资源组页签下,单击目标数据集成资源组后的网络设置。
在专有网络绑定页签,查看交换机网段并将其添加至数据库的白名单中。
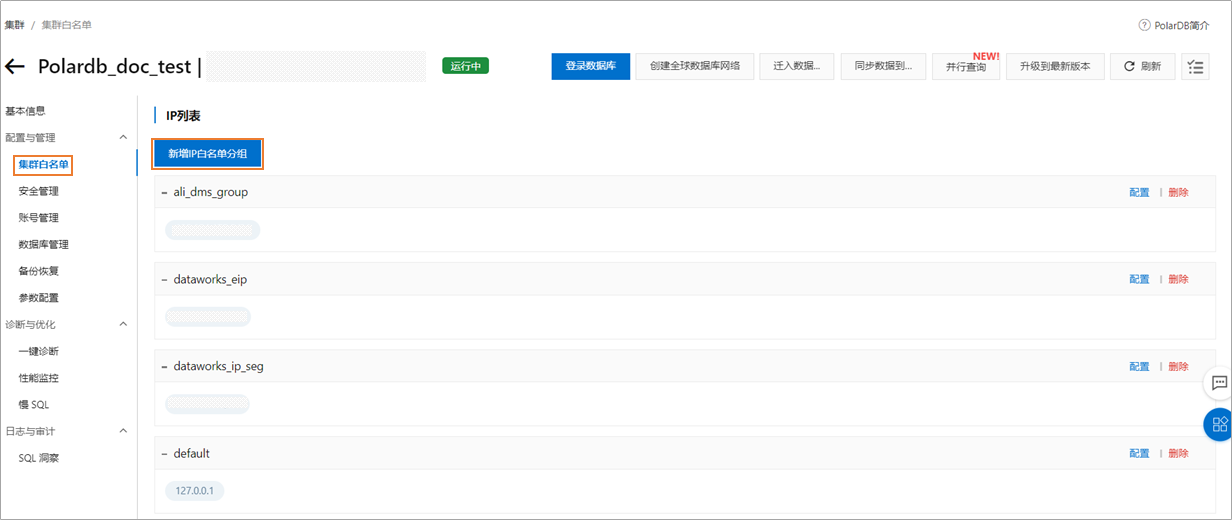
将上述步骤中记录的独享数据资源组的EIP和网段添加至PolarDB的白名单中。
 操作详情可参见设置白名单。
操作详情可参见设置白名单。
创建账号并配置账号权限。
您需要规划一个数据库的登录账户用于后续执行操作,此账户需拥有数据库的
SELECT, REPLICATION SLAVE, REPLICATION CLIENT权限。创建账号。
操作详情可参见创建数据库账号。
配置权限。
您可参考以下命令为账号添加此权限,或直接给账号赋予
SUPER权限。-- CREATE USER '同步账号'@'%' IDENTIFIED BY '同步账号'; GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO '同步账号'@'%';
开启PolarDB的Binlog。
操作详情可参见开启Binlog。
后续步骤
配置完成数据源后,输入数据源、资源实例、输出数据源彼此间已可网络联通,且不存在访问限制。您可将输入数据源和输出数据源添加至DataWorks的数据源列表中,便于后续创建数据同步方案时关联输入和输出数据源。添加数据源操作可参见添加数据源。