本文介绍了常用的内存查询命令和内存相关指标的含义。
Linux内存简介
由于BIOS和Kernel启动过程消耗了部分内存,因此MemTotal值(free命令获取)小于RAM容量。
dmesg | grep Memory
Memory: 131604168K/134217136K available (14346K kernel code, 9546K rwdata, 9084K rodata, 2660K init, 7556K bss, 2612708K reserved, 0K cma-reserved)Linux内存查询命令:
通过查询到的内存数据可以得到Linux内存计算公式如下:
total = used + free + buff/cache //总内存=已使用内存+空闲内存+缓存其中,已使用内存数据包括Kernel消耗的内存和所有进程消耗的内存。
kernel used=Slab + VmallocUsed + PageTables + KernelStack + HardwareCorrupted + Bounce + X
进程内存
进程消耗的内存包括:
虚拟地址空间映射的物理内存。
读写磁盘生成PageCache消耗的内存。
虚拟地址映射的物理内存
物理内存:硬件安装的内存(内存条)。
虚拟内存:操作系统为程序运行提供的内存。程序运行空间包括用户空间(用户态)和内核空间(内核态)。
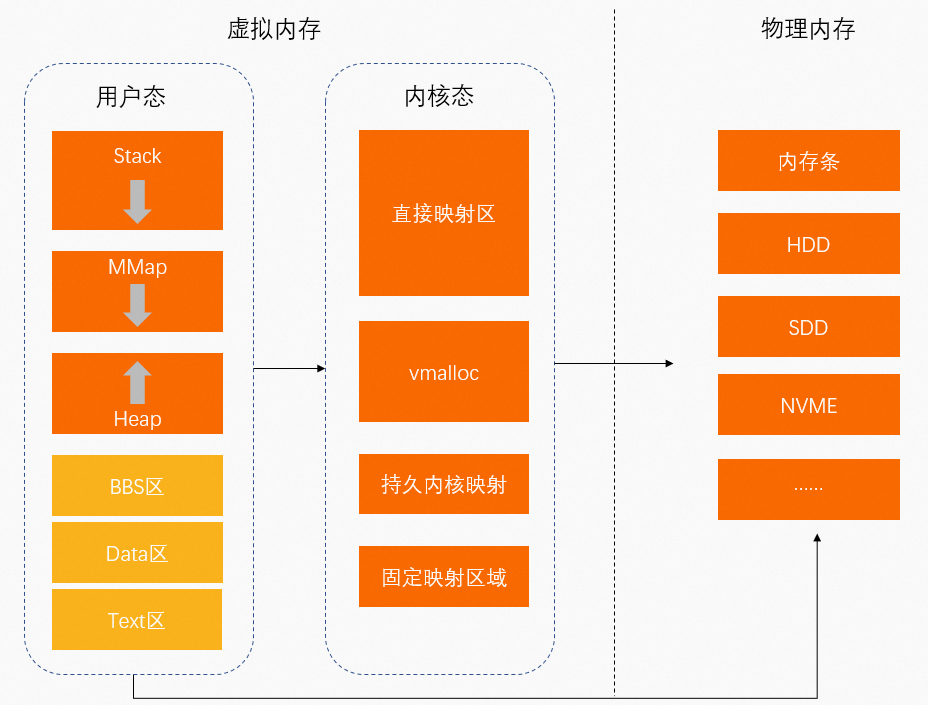
用户态:低特权运行程序。
数据存储空间包括:
栈(Stack):函数调用的函数栈
MMap(Memory Mapping Segment):内存映射区
堆(Heap):动态分配内存
BBS区:未初始化的静态变量存放区
Data区:已初始化的静态常量存放区
Text区:二进制可执行代码存放区
用户态中运行的程序通过MMap将虚拟地址映射至物理内存中。
内核态:运行的程序需要访问操作系统内核数据。
数据存储空间包括:
直接映射区:通过简单映射将虚拟地址映射至物理内存中。
VMALLOC:内核动态映射空间,用于将连续的虚拟地址映射至不连续的物理内存中。
持久内核映射区:将虚拟地址映射至物理内存的高端内存中。
固定映射区:用于满足特殊映射需求。
虚拟地址映射的物理内存可以区分为共享物理内存和独占物理内存。如下图所示,物理内存1和3由进程A独占,物理内存2由进程B独占,物理内存4由进程A和进程B共享。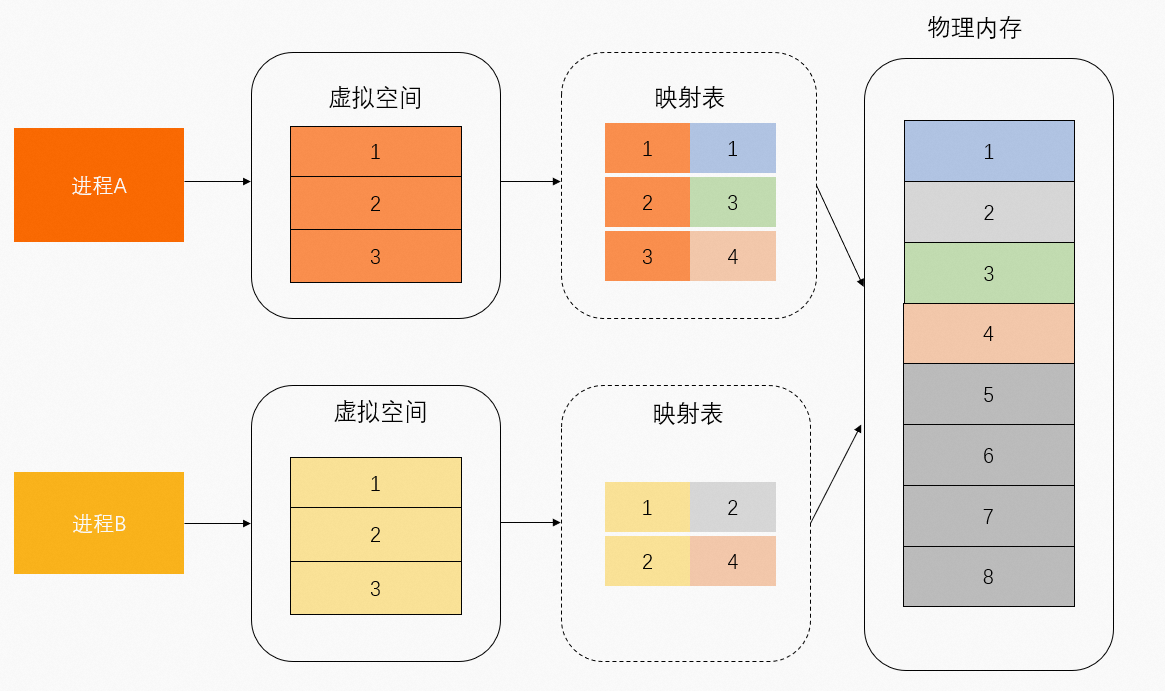
PageCache
除了通过MMap文件直接映射外,进程文件还可以通过系统调用Buffered I/O相关的Syscall将数据写入到PageCache,因此,PageCache也会占用一部分内存。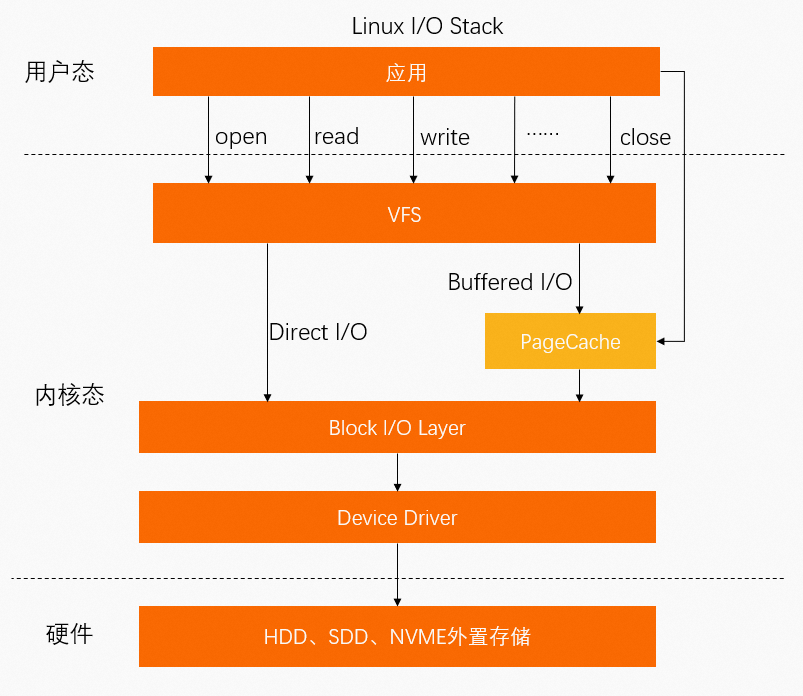
进程内存统计指标
单进程内存统计指标
进程资源存储类型如下:
Anonymous(匿名页):程序自行使用的堆栈空间,在磁盘上没有对应文件。
File-backed(文件页):资源存放在磁盘文件中,文件内包含代码段、字体信息等内容。
相关指标:
anno_rss(RSan):所有类型资源的独占内存。
file_rss(RSfd):File-backed资源占用的所有内存。
shmem_rss(RSsh):Anonymous资源的共享内存。
指标查询命令如下:
命令 | 查询指标 | 说明 | 计算公式 |
| VIRT | 虚拟地址空间。 | 无 |
RES | RSS映射的物理内存。 | anno_rss + file_rss + shmem_rss | |
SHR | 共享内存。 | file_rss + shmem_rss | |
MEM% | 内存使用率。 | RES / MemTotal | |
| VSZ | 虚拟地址空间。 | 无 |
RSS | RSS映射的物理内存。 | anno_rss + file_rss + shmem_rss | |
MEM% | 内存使用率。 | RSS / MemTotal | |
| USS | 独占内存。 | anno_rss |
PSS | 按比例分配内存。 | anno_rss + file_rss/m + shmem_rss/n | |
RSS | RSS映射的物理内存。 | anno_rss + file_rss + shmem_rss |
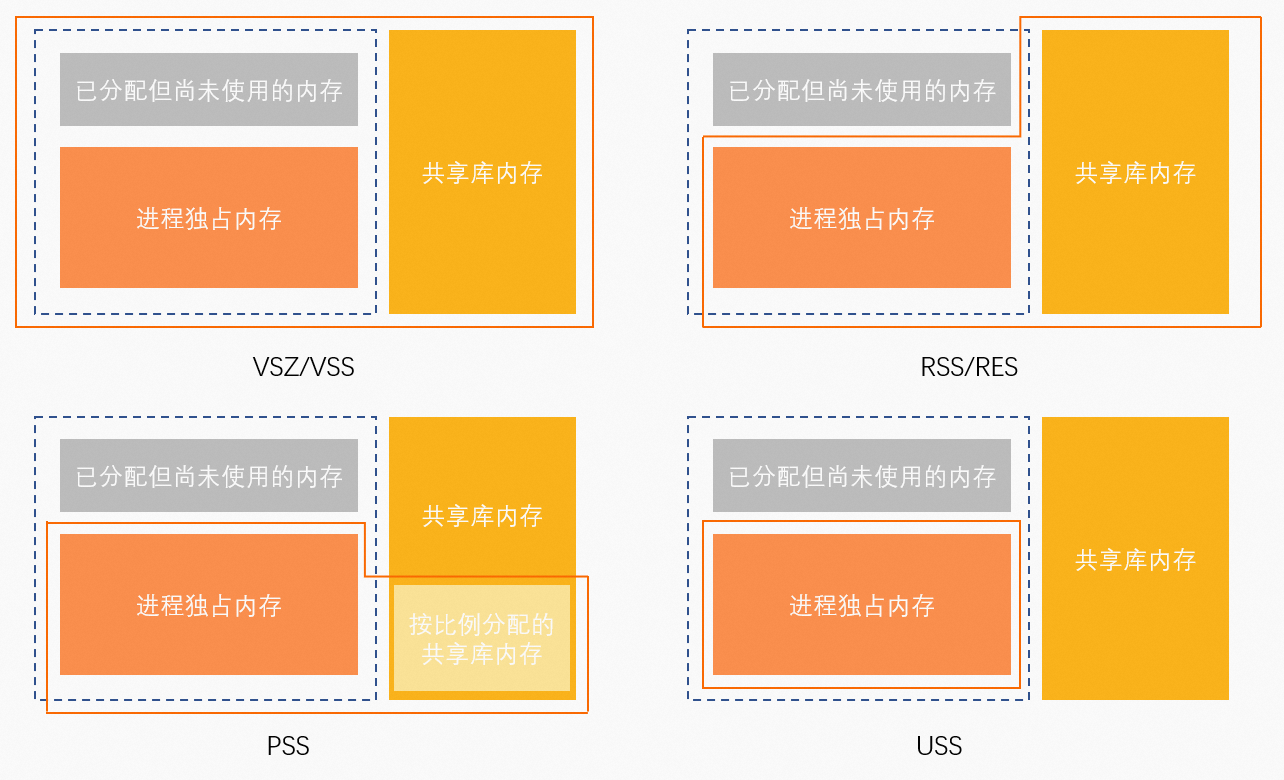
WSS(Memoy Working Set Size)指标:一种更为合理评估进程内存真实使用内存的计算方式。但是受限于Linux Page Reclaim机制,这个概念目前还只是概念,并没有哪一个工具可以正确统计出WSS,只能是趋近。
进程控制组内存统计指标
控制组(Cgroup)用于对Linux的一组进程资源进行限制、管理和隔离。更多信息,请参见官方文档。
Cgroup按层级管理,每个节点都包含一组文件,用于统计由这个节点包含的控制组的某些方面的指标。例如,Memory Control Group(memcg)统计内存相关指标。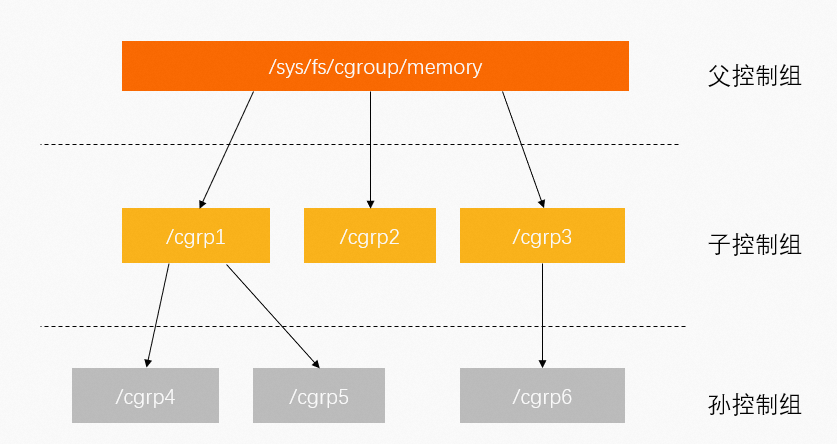
Memory Cgroup文件包含以下指标:
cgroup.event_control #用于eventfd的接口
memory.usage_in_bytes #显示当前已用的内存
memory.limit_in_bytes #设置/显示当前限制的内存额度
memory.failcnt #显示内存使用量达到限制值的次数
memory.max_usage_in_bytes #历史内存最大使用量
memory.soft_limit_in_bytes #设置/显示当前限制的内存软额度
memory.stat #显示当前cgroup的内存使用情况
memory.use_hierarchy #设置/显示是否将子cgroup的内存使用情况统计到当前cgroup里面
memory.force_empty #触发系统立即尽可能的回收当前cgroup中可以回收的内存
memory.pressure_level #设置内存压力的通知事件,配合cgroup.event_control一起使用
memory.swappiness #设置和显示当前的swappiness
memory.move_charge_at_immigrate #设置当进程移动到其他cgroup中时,它所占用的内存是否也随着移动过去
memory.oom_control #设置/显示oom controls相关的配置
memory.numa_stat #显示numa相关的内存其中需要关注以下3个指标:
memory.limit_in_bytes:限制当前控制组可以使用的内存大小。对应K8s、Docker下memory limit指标。
memory.usage_in_bytes:当前控制组里所有进程实际使用的内存总和,约等于memory.stat文件下的RSS+Cache指标值。
memory.stat:当前控制组的内存统计详情。
memory.stat文件字段
说明
cache
PageCache缓存页大小。
rss
控制组中所有进程的anno_rss内存之和。
mapped_file
控制组中所有进程的file_rss和shmem_rss内存之和。
active_anon
活跃LRU(least-recently-used,最近最少使用)列表中所有Anonymous进程使用内存和Swap缓存,包括
tmpfs(shmem),单位为字节。inactive_anon
不活跃LRU列表中所有Anonymous进程使用内存和Swap缓存,包括
tmpfs(shmem),单位为字节。active_file
活跃LRU列表中所有File-backed进程使用内存,以字节为单位。
inactive_file
不活跃LRU列表中所有File-backed进程使用内存,以字节为单位。
unevictable
无法再生的内存,以字节为单位。
以上指标中如果带有
total_前缀则表示当前控制组及其下所有子孙控制组对应指标之和。例如total_rss指标表示当前控制组及其下所有子孙控制组的RSS指标之和。
总结
单进程和进程控制组指标区别:
指标 | 单进程 | 进程控制组(memcg) |
RSS | anon_rss + file_rss + shmem_rss | anon_rss |
mapped_file | 无 | file_rss + shmem_rss |
cache | 无 | PageCache |
控制组的RSS指标只包含anno_rss,对应单进程下的USS指标,因此控制组的mapped_file+RSS则对应单进程下的RSS指标。
单进程中PageCache需单独统计,控制组中memcg文件统计的内存已包含PageCache。
Docker和K8s中的内存统计
Docker和K8s中的内存统计即Linux memcg进程统计,但两者内存使用率的定义不同。
docker stat命令
返回示例如下:
docker stat命令查询原理,请参见官方文档。
func calculateMemUsageUnixNoCache(mem types.MemoryStats) float64 {
return float64(mem.Usage - mem.Stats["cache"])
}LIMIT对应控制组的memory.limit_in_bytes。
MEM USAGE对应控制组的memory.usage_in_bytes - memory.stat[total_cache]。
kubectl top pod命令
kubectl top命令通过Metric-server和Heapster获取Cadvisor中working_set的值,表示Pod实例使用的内存大小(不包括Pause容器)。Petrics-server中Pod内存获取原理如下,更多信息,请参见官方文档。
func decodeMemory(target *resource.Quantity, memStats *stats.MemoryStats) error {
if memStats == nil || memStats.WorkingSetBytes == nil {
return fmt.Errorf("missing memory usage metric")
}
*target = *uint64Quantity(*memStats.WorkingSetBytes, 0)
target.Format = resource.BinarySI
return nil
}Cadvisor内存workingset算法如下,更多信息,请参见官方文档。
func setMemoryStats(s *cgroups.Stats, ret *info.ContainerStats) {
ret.Memory.Usage = s.MemoryStats.Usage.Usage
ret.Memory.MaxUsage = s.MemoryStats.Usage.MaxUsage
ret.Memory.Failcnt = s.MemoryStats.Usage.Failcnt
if s.MemoryStats.UseHierarchy {
ret.Memory.Cache = s.MemoryStats.Stats["total_cache"]
ret.Memory.RSS = s.MemoryStats.Stats["total_rss"]
ret.Memory.Swap = s.MemoryStats.Stats["total_swap"]
ret.Memory.MappedFile = s.MemoryStats.Stats["total_mapped_file"]
} else {
ret.Memory.Cache = s.MemoryStats.Stats["cache"]
ret.Memory.RSS = s.MemoryStats.Stats["rss"]
ret.Memory.Swap = s.MemoryStats.Stats["swap"]
ret.Memory.MappedFile = s.MemoryStats.Stats["mapped_file"]
}
if v, ok := s.MemoryStats.Stats["pgfault"]; ok {
ret.Memory.ContainerData.Pgfault = v
ret.Memory.HierarchicalData.Pgfault = v
}
if v, ok := s.MemoryStats.Stats["pgmajfault"]; ok {
ret.Memory.ContainerData.Pgmajfault = v
ret.Memory.HierarchicalData.Pgmajfault = v
}
workingSet := ret.Memory.Usage
if v, ok := s.MemoryStats.Stats["total_inactive_file"]; ok {
if workingSet < v {
workingSet = 0
} else {
workingSet -= v
}
}
ret.Memory.WorkingSet = workingSet
}通过以上命令算法可以得出,kubectl top pod命令查询到的Memory Usage = Memory WorkingSet = memory.usage_in_bytes - memory.stat[total_inactive_file]。
总结
命令 | 生态 | Memory Usage计算方式 |
| Docker | memory.usage_in_bytes - memory.stat[total_cache] |
| K8s | memory.usage_in_bytes - memory.stat[total_inactive_file] |
如果使用Top、PS命令查询内存,则进程控制组下的Memory Usage指标需对Top、PS命令查询到的指标进行以下计算:
进程组生态 | 计算公式 |
Memcg | rss + cache(active cache + inactive cache) |
Docker | rss |
K8s | rss + active cache |
Java内存统计
Java进程的虚拟地址空间
Java进程虚拟地址空间中数据存储区域分布如下: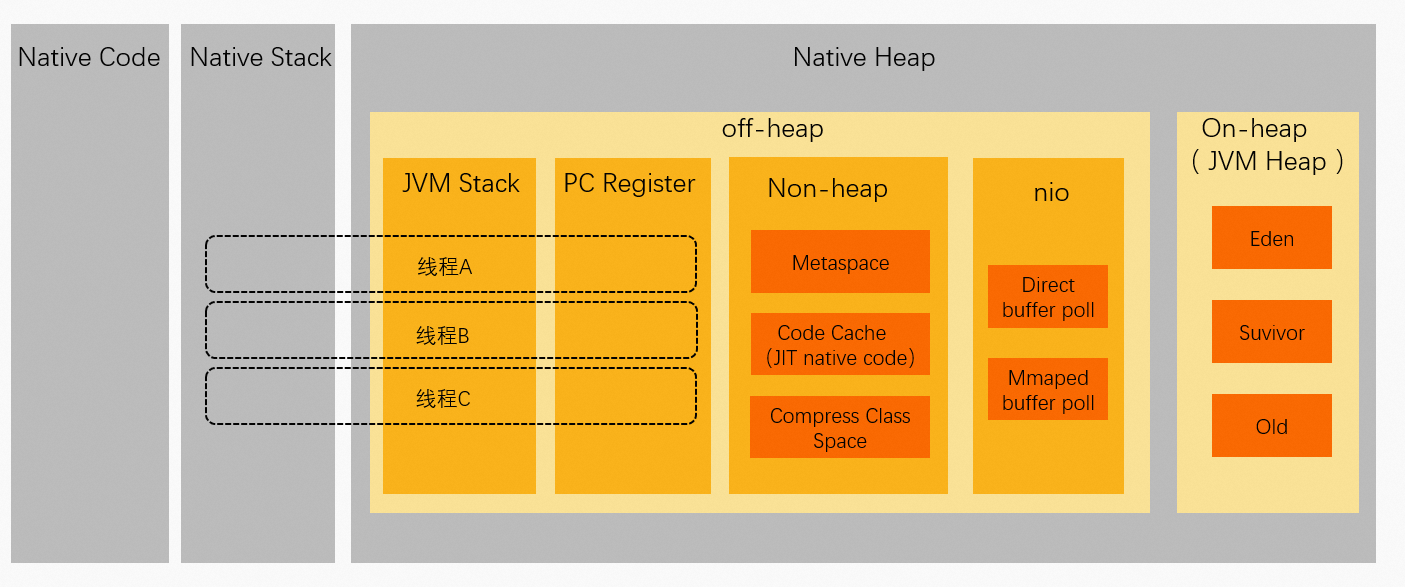
通过JMX获取内存指标
Java进程可以通过JMX暴露的数据获取内存指标,例如通过Jconsole获取内存指标。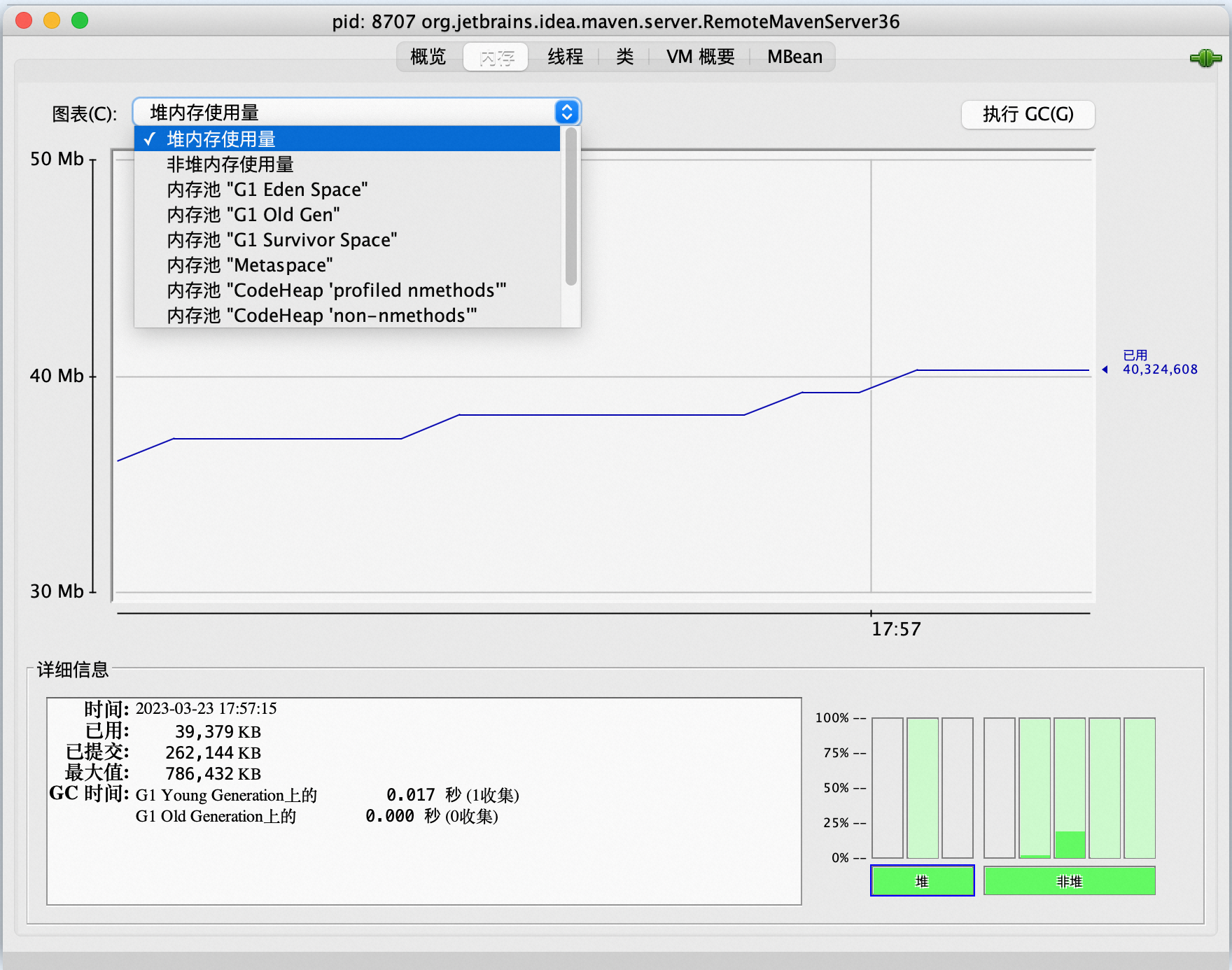
内存相关的数据通过MBean透出。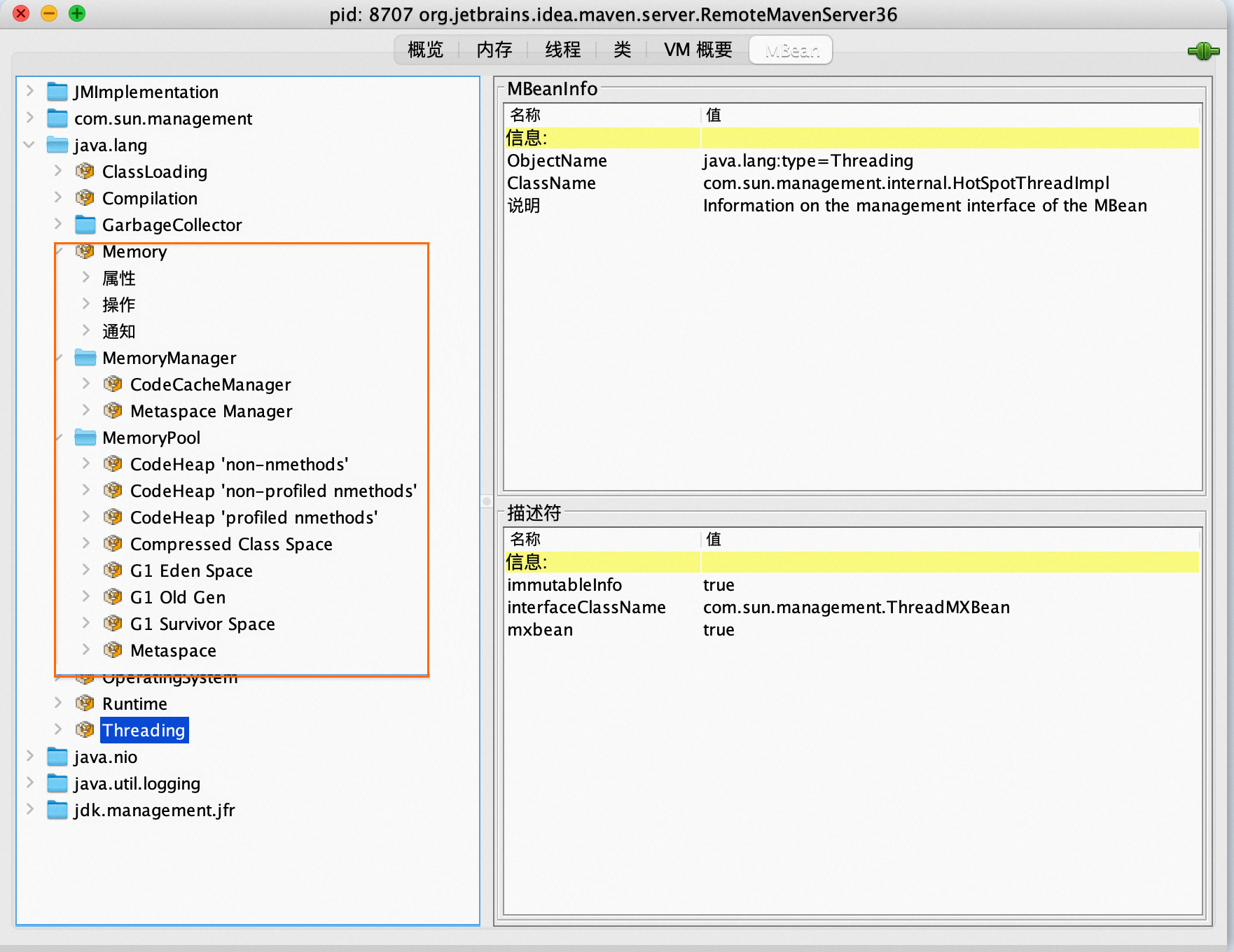
JMX暴露的指标并未展示JVM进程全部的内存指标,例如,Java Thread消耗的内存就未展示。因此,JMX暴露的内存Usage数据累加得出的结果并不等于JVM进程的RSS值。
JMX MemoryUsage工具
JMX通过MemoryPool的MBean透出了MemoryUsage的概念,更多信息,请参见官方文档。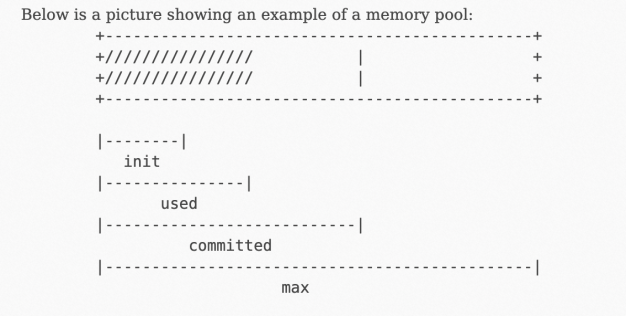
其中,used为物理内存消耗。
NMT工具
Java Hotspot VM提供了一个跟踪内存的工具Native Memory Tracking (NMT),具体使用方法,请参见官方文档。
NMT本身有额外的OverHead,并不适合在生产环境使用。
通过NMT获取的内存指标如下:
jcmd 7 VM.native_memory
Native Memory Tracking:
Total: reserved=5948141KB, committed=4674781KB
- Java Heap (reserved=4194304KB, committed=4194304KB)
(mmap: reserved=4194304KB, committed=4194304KB)
- Class (reserved=1139893KB, committed=104885KB)
(classes #21183)
( instance classes #20113, array classes #1070)
(malloc=5301KB #81169)
(mmap: reserved=1134592KB, committed=99584KB)
( Metadata: )
( reserved=86016KB, committed=84992KB)
( used=80663KB)
( free=4329KB)
( waste=0KB =0.00%)
( Class space:)
( reserved=1048576KB, committed=14592KB)
( used=12806KB)
( free=1786KB)
( waste=0KB =0.00%)
- Thread (reserved=228211KB, committed=36879KB)
(thread #221)
(stack: reserved=227148KB, committed=35816KB)
(malloc=803KB #1327)
(arena=260KB #443)
- Code (reserved=49597KB, committed=2577KB)
(malloc=61KB #800)
(mmap: reserved=49536KB, committed=2516KB)
- GC (reserved=206786KB, committed=206786KB)
(malloc=18094KB #16888)
(mmap: reserved=188692KB, committed=188692KB)
- Compiler (reserved=1KB, committed=1KB)
(malloc=1KB #20)
- Internal (reserved=45418KB, committed=45418KB)
(malloc=45386KB #30497)
(mmap: reserved=32KB, committed=32KB)
- Other (reserved=30498KB, committed=30498KB)
(malloc=30498KB #234)
- Symbol (reserved=19265KB, committed=19265KB)
(malloc=16796KB #212667)
(arena=2469KB #1)
- Native Memory Tracking (reserved=5602KB, committed=5602KB)
(malloc=55KB #747)
(tracking overhead=5546KB)
- Shared class space (reserved=10836KB, committed=10836KB)
(mmap: reserved=10836KB, committed=10836KB)
- Arena Chunk (reserved=169KB, committed=169KB)
(malloc=169KB)
- Tracing (reserved=16642KB, committed=16642KB)
(malloc=16642KB #2270)
- Logging (reserved=7KB, committed=7KB)
(malloc=7KB #267)
- Arguments (reserved=19KB, committed=19KB)
(malloc=19KB #514)
- Module (reserved=463KB, committed=463KB)
(malloc=463KB #3527)
- Synchronizer (reserved=423KB, committed=423KB)
(malloc=423KB #3525)
- Safepoint (reserved=8KB, committed=8KB)
(mmap: reserved=8KB, committed=8KB)通过上述输出指标可以得知,JVM内部划分了很多细分的用途不同的内存区域,例如Java Heap、Class等,但是还有很多额外的内存块。另外,JMX并没有暴露线程(Thread)的内存使用信息,但是实际Java程序大多都有数以万计的线程,因此Thread也消耗了的大量内存。
Hotspot内部关于内存种类划分的定义,请参见官方文档。
Reserved和Committed指标
NMT的输出统计透出了两个概念:Reserved和Committed。但Reserved和Committed都无法映射已使用物理内存(Used)。
虚拟地址Reserved、Committed和物理地址映射关系如下图所示,可以得出Committed总是大于Used(此处Used基本是等同于进程JVM的RSS)。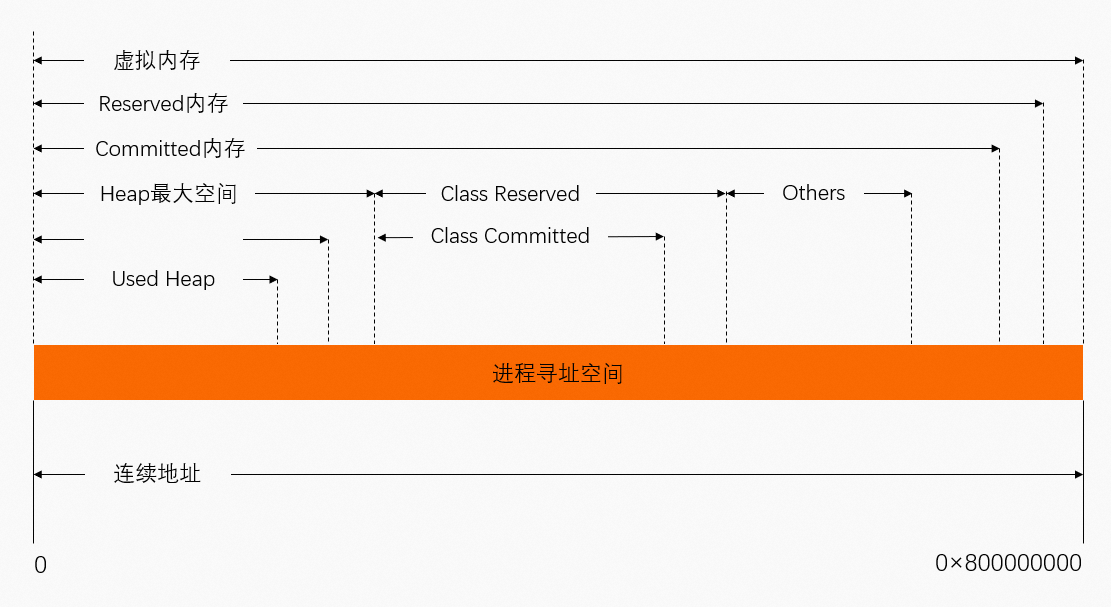
总结
常见Java应用工具统计出来的指标主要是由JMX暴露的,关于内存的统计,JMX暴露了一些JVM内部可跟踪的MemoryPool,这些MemoryPool的总和并不能和JVM进程的RSS映射。
NMT暴露了JVM内部使用内存的细节,但是衡量结果并不是Used,而是Committed。因此,总Committed应该比RSS稍大。
NMT对JVM外的一些内存无法跟踪。如果Java程序有额外的Molloc等行为,NMT是统计不到的,因此如果看到RSS比NMT大,也是正常的。
如果NMT的Committed和RSS相差非常多,那就要怀疑内存是否泄露。
您可以通过NMT的其他指标做进一步排查:
借助NMT的baseline和diff排查是JVM内部哪个区域出现问题。
借助NMT结合pmap排查JVM之外的内存问题。